
Show code cell source
# -*- coding: utf-8 -*-
# This is a report using the data from IQAASL.
# IQAASL was a project funded by the Swiss Confederation
# It produces a summary of litter survey results for a defined region.
# These charts serve as the models for the development of plagespropres.ch
# The data is gathered by volunteers.
# Please remember all copyrights apply, please give credit when applicable
# The repo is maintained by the community effective January 01, 2022
# There is ample opportunity to contribute, learn and teach
# contact dev@hammerdirt.ch
# Dies ist ein Bericht, der die Daten von IQAASL verwendet.
# IQAASL war ein von der Schweizerischen Eidgenossenschaft finanziertes Projekt.
# Es erstellt eine Zusammenfassung der Ergebnisse der Littering-Umfrage für eine bestimmte Region.
# Diese Grafiken dienten als Vorlage für die Entwicklung von plagespropres.ch.
# Die Daten werden von Freiwilligen gesammelt.
# Bitte denken Sie daran, dass alle Copyrights gelten, bitte geben Sie den Namen an, wenn zutreffend.
# Das Repo wird ab dem 01. Januar 2022 von der Community gepflegt.
# Es gibt reichlich Gelegenheit, etwas beizutragen, zu lernen und zu lehren.
# Kontakt dev@hammerdirt.ch
# Il s'agit d'un rapport utilisant les données de IQAASL.
# IQAASL était un projet financé par la Confédération suisse.
# Il produit un résumé des résultats de l'enquête sur les déchets sauvages pour une région définie.
# Ces tableaux ont servi de modèles pour le développement de plagespropres.ch
# Les données sont recueillies par des bénévoles.
# N'oubliez pas que tous les droits d'auteur s'appliquent, veuillez indiquer le crédit lorsque cela est possible.
# Le dépôt est maintenu par la communauté à partir du 1er janvier 2022.
# Il y a de nombreuses possibilités de contribuer, d'apprendre et d'enseigner.
# contact dev@hammerdirt.ch
# sys, file and nav packages:
import datetime as dt
from datetime import date, datetime, time
from babel.dates import format_date, format_datetime, format_time, get_month_names
import locale
# math packages:
import pandas as pd
import numpy as np
from math import pi
# charting:
import matplotlib as mpl
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
from matplotlib import ticker
from matplotlib.ticker import MultipleLocator
import seaborn as sns
from matplotlib import colors as mplcolors
# build report
from reportlab.platypus.flowables import Flowable
from reportlab.platypus import SimpleDocTemplate, Paragraph, Spacer, Image, PageBreak, KeepTogether
from reportlab.lib.pagesizes import A4
from reportlab.rl_config import defaultPageSize
from reportlab.lib.units import inch, cm
from reportlab.lib.styles import getSampleStyleSheet, ParagraphStyle
from reportlab.lib.colors import HexColor
from reportlab.platypus import Table, TableStyle
from reportlab.lib import colors
# the module that has all the methods for handling the data
import resources.featuredata as featuredata
from resources.featuredata import makeAList
# home brew utitilties
# import resources.chart_kwargs as ck
import resources.sr_ut as sut
# images and display
from PIL import Image as PILImage
from IPython.display import Markdown as md
from myst_nb import glue
# chart style
sns.set_style("whitegrid")
# a place to save figures and a
# method to choose formats
save_fig_prefix = "resources/output/"
# the arguments for formatting the image
save_figure_kwargs = {
"fname": None,
"dpi": 300.0,
"format": "jpeg",
"bbox_inches": None,
"pad_inches": 0,
"bbox_inches": 'tight',
"facecolor": 'auto',
"edgecolor": 'auto',
"backend": None,
}
## !! Begin Note book variables !!
# There are two language variants: german and english
# change both: date_lang and language
date_lang = 'de_DE.utf8'
locale.setlocale(locale.LC_ALL, date_lang)
# the date format of the survey data is defined in the module
date_format = featuredata.date_format
# the language setting use lower case: en or de
# changing the language may require changing the unit label
language = "de"
unit_label = "p/100 m"
# the standard date format is "%Y-%m-%d" if your date column is
# not in this format it will not work.
# these dates cover the duration of the IQAASL project
start_date = "2020-03-01"
end_date ="2021-05-31"
start_end = [start_date, end_date]
# the fail rate used to calculate the most common codes is
# 50% it can be changed:
fail_rate = 50
# Changing these variables produces different reports
# Call the map image for the area of interest
bassin_map = "resources/maps/thunerseebrienzersee_city_labels.jpeg"
# the label for the aggregation of all data in the region
top = "Alle Erhebungsgebiete"
# define the feature level and components
# the feature of interest is the Aare (aare) at the river basin (river_bassin) level.
# the label for charting is called 'name'
this_feature = {'slug':'thunerseebrienzersee', 'name':"Thunersee/Brienzersee", 'level':'water_name_slug'}
# the lake is in this survey area
this_bassin = "aare"
# label for survey area
bassin_label = "Erhebungsgebiet Aare"
# these are the smallest aggregated components
# choices are water_name_slug=lake or river, city or location at the scale of a river bassin
# water body or lake maybe the most appropriate
this_level = 'city'
# the doctitle is the unique name for the url of this document
doc_title = "thunerseebrienzersee"
# identify the lakes of interest for the survey area
lakes_of_interest = ["thunersee","brienzersee"]
# !! End note book variables !!
## data
# Survey location details (GPS, city, land use)
dfBeaches = pd.read_csv("resources/beaches_with_land_use_rates.csv")
# set the index of the beach data to location slug
dfBeaches.set_index("slug", inplace=True)
# Survey dimensions and weights
dfDims = pd.read_csv("resources/corrected_dims.csv")
# code definitions
dxCodes = pd.read_csv("resources/codes_with_group_names_2015.csv")
dxCodes.set_index("code", inplace=True)
# columns that need to be renamed. Setting the language will automatically
# change column names, code descriptions and chart annotations
columns={"% to agg":"% agg", "% to recreation": "% recreation", "% to woods":"% woods", "% to buildings":"% buildings", "p/100m":"p/100 m"}
# !key word arguments to construct feature data
# !Note the water type allows the selection of river or lakes
# if None then the data is aggregated together. This selection
# is only valid for survey-area reports or other aggregated data
# that may have survey results from both lakes and rivers.
fd_kwargs ={
"filename": "resources/checked_sdata_eos_2020_21.csv",
"feature_name": this_feature['slug'],
"feature_level": this_feature['level'],
"these_features": ["thunersee","brienzersee"],
"component": this_level,
"columns": columns,
"language": 'de',
"unit_label": unit_label,
"fail_rate": fail_rate,
"code_data":dxCodes,
"date_range": start_end,
"water_type": None,
}
fdx = featuredata.Components(**fd_kwargs)
# call the reports and languages
fdx.adjustForLanguage()
fdx.makeFeatureData()
fdx.locationSampleTotals()
fdx.makeDailyTotalSummary()
fdx.materialSummary()
fdx.mostCommon()
fdx.codeGroupSummary()
# !this is the feature data!
fd = fdx.feature_data
# !keyword args to build period data
# the period data is all the data that was collected
# during the same period from all the other locations
# not included in the feature data. For a survey area
# or river bassin these_features = feature_parent and
# feature_level = parent_level
period_kwargs = {
"period_data": fdx.period_data,
"these_features": ["thunersee","brienzersee"],
"feature_level":this_feature['level'],
"feature_parent":this_bassin,
"parent_level": "river_bassin",
"period_name": bassin_label,
"unit_label": unit_label,
"most_common": fdx.most_common.index
}
period_data = featuredata.PeriodResults(**period_kwargs)
# the rivers are considered separately
# select only the results from rivers
# this can be done by updating the fd_kwargs
fd_rivers = fd_kwargs.update({"water_type":"r"})
fdr = featuredata.Components(**fd_kwargs)
fdr.makeFeatureData()
# collects the summarized values for the feature data
# use this to generate the summary data for the survey area
# and the section for the rivers
admin_kwargs = {
"data":fd,
"dims_data":dfDims,
"label": this_feature["name"],
"feature_component": this_level,
"date_range":start_end,
**{"dfBeaches":dfBeaches}
}
admin_details = featuredata.AdministrativeSummary(**admin_kwargs)
admin_summary = admin_details.summaryObject()
# update the admin kwargs with river data to make the river summary
admin_kwargs.update({"data":fdr.feature_data})
admin_r_details = featuredata.AdministrativeSummary(**admin_kwargs)
admin_r_summary = admin_r_details.summaryObject()
# this defines the css rules for the note-book table displays
header_row = {'selector': 'th:nth-child(1)', 'props': f'background-color: #FFF;text-align:right;'}
even_rows = {"selector": 'tr:nth-child(even)', 'props': f'background-color: rgba(139, 69, 19, 0.08);'}
odd_rows = {'selector': 'tr:nth-child(odd)', 'props': 'background: #FFF;'}
table_font = {'selector': 'tr', 'props': 'font-size: 12px;'}
table_data = {'selector': 'td', 'props': 'padding:6px;'}
table_css_styles = [even_rows, odd_rows, table_font, header_row, table_data]
# this defines the css rules for the note-book table displays
header_row = {'selector': 'th:nth-child(1)', 'props': f'background-color: #FFF;text-align:right;'}
table_font = {'selector': 'tr', 'props': 'font-size: 12px;'}
table_data = {'selector': 'td', 'props': 'padding:6px;'}
heat_map_css_styles = [table_font, header_row, table_data]
# this is the numeric formatting for the dimensions table
dims_table_formatter = {
"Plastik (Kg)": lambda x: featuredata.replaceDecimal(x, language),
"Gesamtgewicht (Kg)": lambda x: featuredata.replaceDecimal(x, language),
"Fläche (m2)": lambda x: featuredata.thousandsSeparator(int(x), language),
"Länge (m)": lambda x: featuredata.thousandsSeparator(int(x), language),
"Erhebungen": lambda x: featuredata.thousandsSeparator(int(x), language),
"Objekte (St.)": lambda x: featuredata.thousandsSeparator(int(x), language)
}
# formatting for mpl charts
months = mdates.MonthLocator(interval=1)
months_fmt = mdates.DateFormatter("%b")
days = mdates.DayLocator(interval=7)
def convertPixelToCm(file_name: str = None):
im = PILImage.open(file_name)
width, height = im.size
dpi = im.info.get("dpi", (72, 72))
width_cm = width / dpi[0] * 2.54
height_cm = height / dpi[1] * 2.54
return width_cm, height_cm
# pdf download is an option
# reportlab is used to produce the document
# the arguments for the document are captured at run time
# capture for pdf content
pdf_link = f'resources/pdfs/{this_feature["slug"]}.pdf'
pdfcomponents = []
# pdf title and map
pdf_title = Paragraph(this_feature["name"], featuredata.title_style)
# map_image = Image(bassin_map, width=cm*19, height=20*cm, kind="proportional", hAlign= "CENTER")
pdfcomponents = featuredata.addToDoc([
pdf_title,
featuredata.small_space,
], pdfcomponents)
glue(f'{this_feature["slug"]}_pdf_link', pdf_link, display=False)
11. Thunersee/Brienzersee#
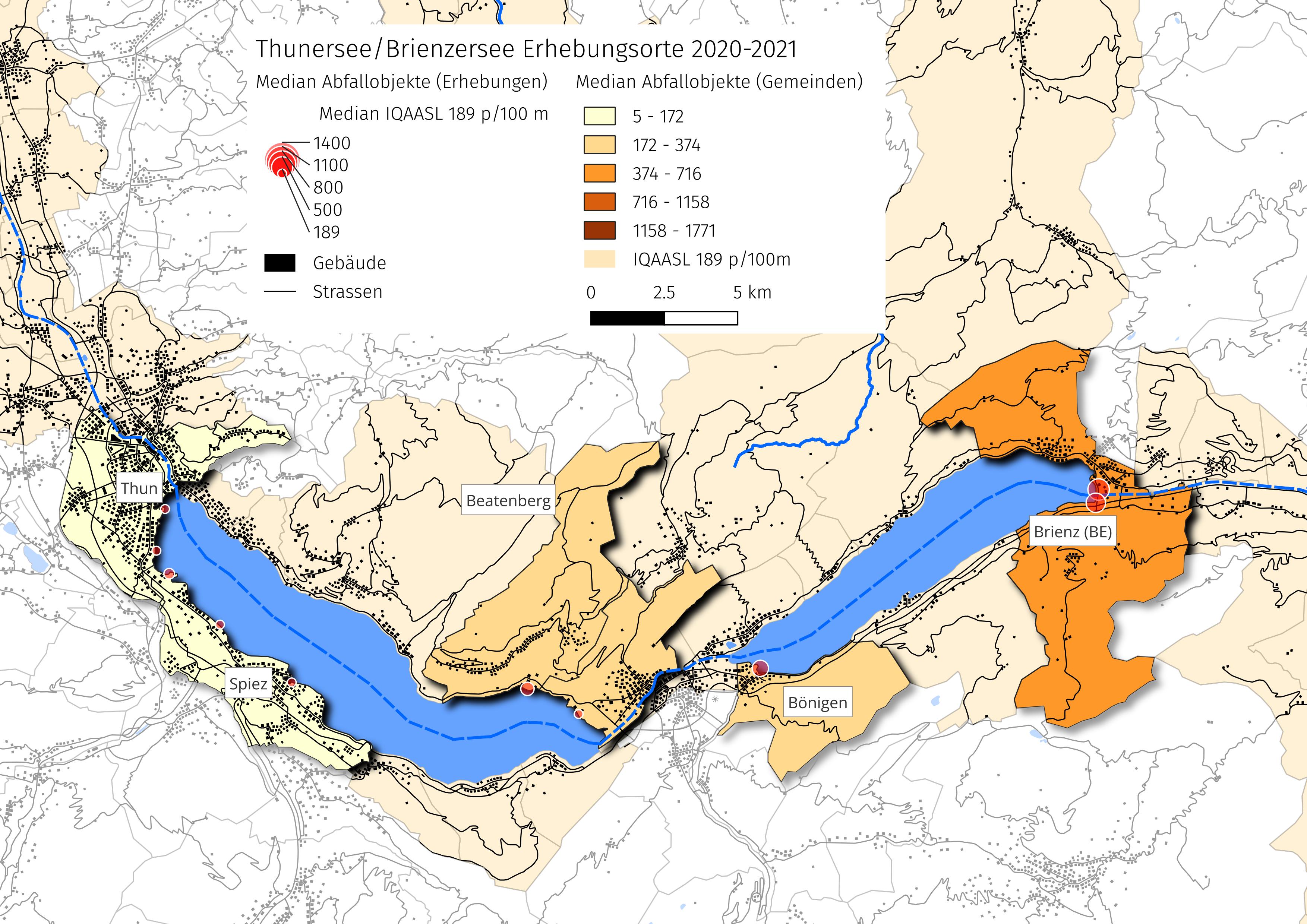
Abb. 11.1 #
Abbildung 11.1: Die Erhebungsorte sind für die Analyse nach Erhebungsgebiet gruppiert. Die Grösse der Markierung gibt einen Hinweis auf die Anzahl Abfallobjekte, die gefunden wurden.
11.1. Erhebungsorte#
Show code cell source
an_admin_summary = featuredata.makeAdminSummaryStateMent(start_date, end_date, this_feature["name"], admin_summary=admin_summary)
# collect component features and land marks
feature_components = featuredata.collectComponentLandMarks(admin_details, language="de")
# markdown output
components_markdown = [f'*{x[0]}*\n\n>{x[1]}\n\n' for x in feature_components]
# add the admin summary to the pdf
pdfcomponents = featuredata.addToDoc([
featuredata.smallest_space,
Paragraph("Erhebungsorte", featuredata.section_title),
featuredata.small_space,
Paragraph(an_admin_summary , featuredata.p_style)
], pdfcomponents)
# put that all together:
lake_string = F"""
{an_admin_summary}
{"".join(components_markdown)}
"""
md(lake_string)
Im Zeitraum von März 2020 bis Mai 2021 wurden im Rahmen von 36 Datenerhebungen insgesamt 3 764 Objekte entfernt und identifiziert. Die Ergebnisse des Thunersee/Brienzersee umfassen 10 Orte, 6 Gemeinden und eine Gesamtbevölkerung von etwa 69 120 Einwohnenden.
Seen
Thunersee, Brienzersee
Gemeinden
Beatenberg, Brienz (BE), Bönigen, Spiez, Thun, Unterseen
11.1.1. Kumulative Gesamtmengen nach Gemeinden#
Show code cell source
# the .pdf output is generated in parallel
# this is the same as if it were on the backend where we would
# have a specific api endpoint for .pdf requests.
dims_table = admin_details.dimensionalSummary()
dims_table.sort_values(by=["quantity"], ascending=False, inplace=True)
# apply language
dims_table.rename(columns=featuredata.dims_table_columns_de, inplace=True)
# convert to kilos
dims_table["Plastik (Kg)"] = dims_table["Plastik (Kg)"]/1000
# save a copy of the dims_table for working
# formattinr to pdf will turn the numerics to strings
# which eliminates any further calclations
dims_df = dims_table.copy()
# these columns need formatting for locale
thousands_separated = ["Fläche (m2)", "Länge (m)", "Erhebungen", "Objekte (St.)"]
replace_decimal = ["Plastik (Kg)", "Gesamtgewicht (Kg)"]
# format the dimensional summary for .pdf and add to components
dims_table[thousands_separated] = dims_table[thousands_separated].applymap(lambda x: featuredata.thousandsSeparator(int(x), "de"))
dims_table[replace_decimal] = dims_table[replace_decimal].applymap(lambda x: featuredata.replaceDecimal(str(round(x,2))))
# a caption for the figure
dims_table_caption = f'{this_feature["name"]}: kumulierten Gewichte und Masse für die Gemeinden'
# pdf components
d_chart = featuredata.aSingleStyledTable(dims_table, colWidths=[3.5*cm, 3*cm, *[2.2*cm]*(len(dims_table.columns)-1)])
d_capt = Paragraph(dims_table_caption, featuredata.caption_style)
a_dims_table = featuredata.tableAndCaption(d_chart, d_capt, [3.5*cm, 3*cm, *[2.2*cm]*(len(dims_table.columns)-2)])
new_components = [
featuredata.smallest_space,
a_dims_table
]
pdfcomponents = featuredata.addToDoc(new_components, pdfcomponents)
# this formats the table through the data frame
dims_df["Plastik (Kg)"] = dims_df["Plastik (Kg)"].round(2)
dims_df["Gesamtgewicht (Kg)"] = dims_df["Gesamtgewicht (Kg)"].round(2)
dims_df[thousands_separated] = dims_df[thousands_separated].astype("int")
# set the index name to None so it doesn't show in the columns
dims_df.index.name = None
dims_df.columns.name = None
# use the caption from the .pdf for the online figure
glue("thunerseebrienzersee_dims_table_caption",dims_table_caption, display=False)
# apply formatting and styles to dataframe
q = dims_df.style.format(formatter=dims_table_formatter).set_table_styles(table_css_styles)
# capture the figure before display and give it a reference number and caption
figure_name=f'{this_feature["slug"]}_dims_table'
glue(figure_name, q, display=False)
| Gesamtgewicht (Kg) | Plastik (Kg) | Fläche (m2) | Länge (m) | Erhebungen | Objekte (St.) | |
|---|---|---|---|---|---|---|
| Thunersee/Brienzersee | 22,25 | 7,86 | 10 656 | 2 396 | 36 | 3 764 |
| Unterseen | 2,19 | 1,18 | 3 728 | 1 045 | 12 | 1 879 |
| Brienz (BE) | 1,86 | 1,61 | 672 | 144 | 3 | 697 |
| Spiez | 14,09 | 1,36 | 3 156 | 871 | 14 | 531 |
| Bönigen | 0,41 | 0,36 | 471 | 86 | 2 | 277 |
| Thun | 3,4 | 3,21 | 1 824 | 206 | 3 | 276 |
| Beatenberg | 0,3 | 0,14 | 805 | 44 | 2 | 104 |
Abb. 11.2 #
Abbildung 11.2: Thunersee/Brienzersee: kumulierten Gewichte und Masse für die Gemeinden
11.1.2. Verteilung der Erhebungsergebnisse#
Show code cell source
# figure caption
sample_total_notes = f'Links: {this_feature["name"]}, {featuredata.dateToYearAndMonth(datetime.strptime(start_date, date_format), lang=date_lang)} bis {featuredata.dateToYearAndMonth(datetime.strptime(end_date, date_format), lang=date_lang)}, n = {admin_summary["loc_date"]}. Rechts: empirische Verteilungsfunktion der Erhebungsergebnisse {this_feature["name"]}.'
glue(f'{this_feature["slug"]}_sample_total_notes', sample_total_notes, display=False)
dx = period_data.parentSampleTotals(parent=False)
# get the monthly or quarterly results for the feature
rsmp = fdx.sample_totals.set_index("date")
resample_plot, rate = featuredata.quarterlyOrMonthlyValues(rsmp, this_feature["name"], vals=unit_label)
fig, axs = plt.subplots(1,2, figsize=(10,5))
# the survey totals by day
ax = axs[0]
# feature surveys
sns.scatterplot(data=dx, x="date", y=unit_label, label=top, color="black", alpha=0.4, ax=ax)
# all other surveys
sns.scatterplot(data=fdx.sample_totals, x="date", y=unit_label, label=this_feature["name"], color="red", s=34, ec="white", ax=ax)
# monthly or quaterly plot
sns.lineplot(data=resample_plot, x=resample_plot.index, y=resample_plot, label=F"{this_feature['name']}: monatlicher Medianwert", color="magenta", ax=ax)
# axis formatting
ax.set_ylabel(unit_label, **featuredata.xlab_k14)
ax.set_xlabel("")
ax.xaxis.set_minor_locator(days)
ax.xaxis.set_major_formatter(months_fmt)
ax.set_ylim(-50, 2000)
# call the legend
ax.legend()
# the cumlative distributions:
axtwo = axs[1]
# the feature of interest
feature_ecd = featuredata.ecdfOfAColumn(fdx.sample_totals, unit_label)
sns.lineplot(x=feature_ecd["x"], y=feature_ecd["y"], color="darkblue", ax=axtwo, label=this_feature["name"])
# the other features
other_features = featuredata.ecdfOfAColumn(dx, unit_label)
sns.lineplot(x=other_features["x"], y=other_features["y"], color="magenta", label=top, linewidth=1, ax=axtwo)
axtwo.set_xlabel(unit_label, **featuredata.xlab_k14)
axtwo.set_ylabel("Verhältnis der Erhebungen", **featuredata.xlab_k14)
axtwo.set_xlim(0, 3000)
axtwo.xaxis.set_major_locator(MultipleLocator(500))
axtwo.xaxis.set_minor_locator(MultipleLocator(100))
axtwo.yaxis.set_major_locator(MultipleLocator(.1))
axtwo.grid(which="minor", visible=True, axis="x", linestyle="--", linewidth=1)
figure_name = "thunerseebrienzersee_sample_totals"
sample_totals_file_name = f'{save_fig_prefix}{figure_name}.jpeg'
save_figure_kwargs.update({"fname":sample_totals_file_name})
plt.tight_layout()
plt.savefig(**save_figure_kwargs)
glue(f'{this_feature["slug"]}_sample_totals', fig, display=False)
plt.close()
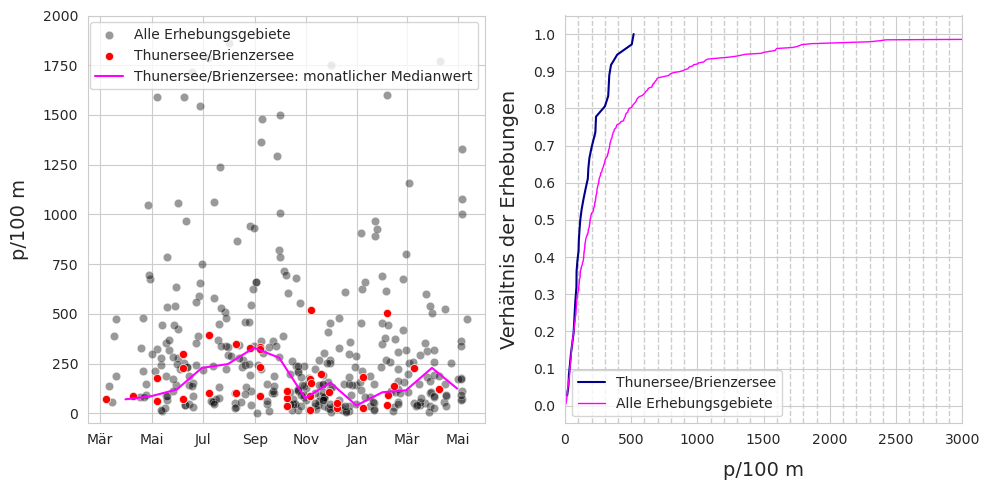
Abb. 11.3 #
Abbildung 11.3: Links: Thunersee/Brienzersee, März 2020 bis Mai 2021, n = 36. Rechts: empirische Verteilungsfunktion der Erhebungsergebnisse Thunersee/Brienzersee.
11.1.3. Zusammengefasste Daten und Materialarten#
Show code cell source
# figure caption
summary_of_survey_totals = f'Zusammenfassung der Daten aller Erhebungen am {this_feature["name"]}. Gefundene Materialarten am {this_feature["name"]} in Stückzahlen und als prozentuale Anteile (stückzahlbezogen).'
# add to pdf
csx = fdx.sample_summary.copy()
combined_summary =[(x, featuredata.thousandsSeparator(int(csx[x]), language)) for x in csx.index]
# the materials table
fd_mat_totals = fdx.material_summary.copy()
fd_mat_totals = featuredata.fmtPctOfTotal(fd_mat_totals, around=0)
# applly new column names for printing
cols_to_use = {"material":"Material","quantity":"Objekte (St.)", "% of total":"Anteil"}
fd_mat_t = fd_mat_totals[cols_to_use.keys()].values
fd_mat_t = [(x[0], featuredata.thousandsSeparator(int(x[1]), language), x[2]) for x in fd_mat_t]
# make tables
fig, axs = plt.subplots(1,2, figsize=(7, len(combined_summary)*.4))
# summary table
# names for the table columns
a_col = [this_feature["name"], "Total"]
axone = axs[0]
sut.hide_spines_ticks_grids(axone)
table_two = sut.make_a_table(axone, combined_summary, colLabels=a_col, colWidths=[.75,.25], bbox=[0,0,1,1], **{"loc":"lower center"})
table_two.get_celld()[(0,0)].get_text().set_text(" ")
table_two.set_fontsize(10)
# material table
axtwo = axs[1]
axtwo.set_xlabel(" ")
sut.hide_spines_ticks_grids(axtwo)
table_three = sut.make_a_table(axtwo, fd_mat_t, colLabels=list(cols_to_use.values()), colWidths=[.4, .4,.2], bbox=[0,0,1,1], **{"loc":"lower center"})
table_three.get_celld()[(0,0)].get_text().set_text(" ")
table_three.set_fontsize(10)
plt.tight_layout()
plt.subplots_adjust(wspace=0.1)
plt.margins(0, 0)
figure_name = f'{this_feature["slug"]}_sample_summaries'
sample_summaries_file_name = f'{save_fig_prefix}{figure_name}.jpeg'
save_figure_kwargs.update({"fname":sample_summaries_file_name})
plt.savefig(**save_figure_kwargs)
glue(f'{this_feature["slug"]}_sample_summaries_caption', summary_of_survey_totals, display=False)
glue(figure_name, fig, display=False)
plt.close()
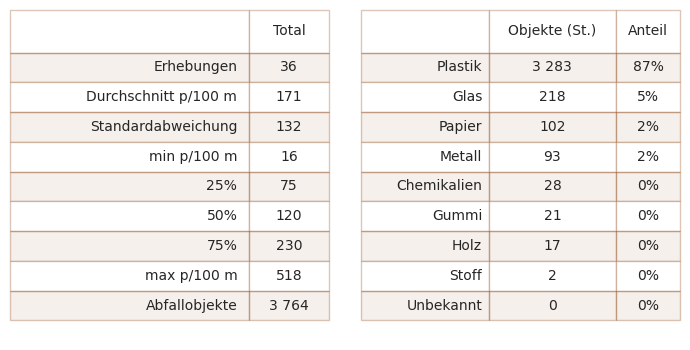
Abb. 11.4 #
Abbildung 11.4: Zusammenfassung der Daten aller Erhebungen am Thunersee/Brienzersee. Gefundene Materialarten am Thunersee/Brienzersee in Stückzahlen und als prozentuale Anteile (stückzahlbezogen).
11.2. Die am häufigsten gefundenen Objekte#
Die am häufigsten gefundenen Objekte sind die zehn mengenmässig am meisten vorkommenden Objekte und/oder Objekte, die in mindestens 50 % aller Datenerhebungen identifiziert wurden (Häufigkeitsrate)
Show code cell source
# add summary tables to pdf
sample_summary_subsection = Paragraph("Verteilung der Erhebungsergebnisse", featuredata.subsection_title)
s_totals = Image(sample_totals_file_name, width=16*cm, height=10*cm, kind="proportional", hAlign= "CENTER")
s_totals_caption = Paragraph(sample_total_notes, featuredata.caption_style)
samp_mat_subsection = Paragraph("Zusammengefasste Daten und Materialarten", featuredata.subsection_title)
samp_material_table = Image(sample_summaries_file_name , width=12*cm, height=10*cm, kind="proportional", hAlign= "CENTER")
samp_material_caption = Paragraph(summary_of_survey_totals, featuredata.caption_style)
o_w, o_h = convertPixelToCm(sample_totals_file_name)
f2cap = Paragraph(sample_total_notes, featuredata.caption_style)
figure_kwargs = {
"image_file":sample_totals_file_name,
"caption": f2cap,
"original_width":o_w,
"original_height":o_h,
"desired_width": 15,
"caption_height":.75,
"hAlign": "CENTER",
}
f2 = featuredata.figureAndCaptionTable(**figure_kwargs)
o_w, o_h = convertPixelToCm(sample_summaries_file_name)
f3cap = Paragraph(summary_of_survey_totals, featuredata.caption_style)
figure_kwargs = {
"image_file":sample_summaries_file_name,
"caption": f3cap,
"original_width":o_w,
"original_height":o_h,
"desired_width": 12,
"caption_height":.75,
"hAlign": "CENTER",
}
f3 = featuredata.figureAndCaptionTable(**figure_kwargs)
new_components = [KeepTogether([
featuredata.small_space,
sample_summary_subsection,
featuredata.small_space,
f2,
featuredata.small_space,
samp_mat_subsection,
featuredata.small_space,
f3,
]), PageBreak()]
pdfcomponents = featuredata.addToDoc(new_components, pdfcomponents)
# the most common results
most_common_display = fdx.most_common
# language appropriate columns
cols_to_use = featuredata.most_common_objects_table_de
cols_to_use.update({unit_label:unit_label})
# data for display
most_common_display.rename(columns=cols_to_use, inplace=True)
most_common_display = most_common_display[cols_to_use.values()].copy()
most_common_display = most_common_display.set_index("Objekte", drop=True)
# .pdf output
data = most_common_display.copy()
data["Anteil"] = data["Anteil"].map(lambda x: f"{int(x)}%")
data['Objekte (St.)'] = data['Objekte (St.)'].map(lambda x:featuredata.thousandsSeparator(x, language))
data['Häufigkeitsrate'] = data['Häufigkeitsrate'].map(lambda x: f"{x}%")
data[unit_label] = data[unit_label].map(lambda x: featuredata.replaceDecimal(round(x,1)))
# make caption
# get percent of total to make the caption string
m_common_percent_of_total = fdx.most_common['Objekte (St.)'].sum()/fdx.code_summary['quantity'].sum()
mc_caption_string = [
f'Häufigste Objekte im {this_feature["name"]}: ',
'd. h. Objekte mit einer Häufigkeitsrate von mindestens 50% und/oder ',
f'Top Ten nach Anzahl. Zusammengenommen machen die häufigsten Objekte {int(m_common_percent_of_total*100)}% ',
f'aller gefundenen Objekte aus. Anmerkung: {unit_label} = Medianwert der Erhebung.'
]
mc_caption_string = "".join(mc_caption_string)
colwidths = [4.5*cm, 2.2*cm, 2*cm, 2.8*cm, 2*cm]
# pdf_mc_table = featuredata.aStyledTable(data, caption=mc_caption_string, colWidths=[4.5*cm, 2.2*cm, 2*cm, 2.8*cm, 2*cm])
d_chart = featuredata.aSingleStyledTable(data, colWidths=colwidths)
d_capt = Paragraph(mc_caption_string, featuredata.caption_style)
mc_table = featuredata.tableAndCaption(d_chart, d_capt, colwidths)
most_common_display.index.name = None
most_common_display.columns.name = None
# set pandas display
aformatter = {
"Anteil":lambda x: f"{int(x)}%",
f"{unit_label}": lambda x: featuredata.replaceDecimal(x, "de"),
"Häufigkeitsrate": lambda x: f"{int(x)}%",
"Objekte (St.)": lambda x: featuredata.thousandsSeparator(int(x), "de")
}
mcd = most_common_display.style.format(aformatter).set_table_styles(table_css_styles)
glue('thunerseebrienzersee_most_common_caption', mc_caption_string, display=False)
glue('thunerseebrienzersee_most_common_tables', mcd, display=False)
| Objekte (St.) | Anteil | Häufigkeitsrate | p/100 m | |
|---|---|---|---|---|
| Zigarettenfilter | 748 | 19% | 88% | 14,0 |
| Fragmentierte Kunststoffe | 515 | 13% | 91% | 17,0 |
| Industriefolie (Kunststoff) | 352 | 9% | 83% | 8,0 |
| Expandiertes Polystyrol | 281 | 7% | 83% | 10,5 |
| Snack-Verpackungen | 228 | 6% | 77% | 5,0 |
| Schaumstoffverpackungen/Isolierung | 158 | 4% | 66% | 2,5 |
| Getränkeflaschen aus Glas, Glasfragmente | 141 | 3% | 72% | 2,5 |
| Industriepellets (Nurdles) | 115 | 3% | 11% | 0,0 |
| Verpackungsfolien, nicht für Lebensmittel | 83 | 2% | 44% | 0,0 |
| Kunststoff-Bauabfälle | 65 | 1% | 50% | 0,5 |
| Wattestäbchen/Tupfer | 35 | 0% | 52% | 1,0 |
Abb. 11.5 #
Abbildung 11.5: Häufigste Objekte im Thunersee/Brienzersee: d. h. Objekte mit einer Häufigkeitsrate von mindestens 50% und/oder Top Ten nach Anzahl. Zusammengenommen machen die häufigsten Objekte 72% aller gefundenen Objekte aus. Anmerkung: p/100 m = Medianwert der Erhebung.
11.2.1. Die am häufigsten gefundenen Objekte nach Gemeinden#
Show code cell source
# add new section to pdf
mc_section_title = Paragraph("Die am häufigsten gefundenen Objekte", featuredata.section_title)
para_g = "Die am häufigsten gefundenen Objekte sind die zehn mengenmässig am meisten vorkommenden Objekte und/oder Objekte, die in mindestens 50 % aller Datenerhebungen identifiziert wurden (Häufigkeitsrate)"
mc_section_para = Paragraph(para_g, featuredata.p_style)
mc_table_cap = Paragraph(mc_caption_string, featuredata.caption_style)
new_components = [
KeepTogether([
mc_section_title,
featuredata.small_space,
mc_section_para,
featuredata.large_space,
mc_table
])
]
pdfcomponents = featuredata.addToDoc(new_components, pdfcomponents)
mc_heat_map_caption = f'Median {unit_label} der häufigsten Objekte am {this_feature["name"]}.'
# calling componentsMostCommon gets the results for the most common codes
# at the component level
components = fdx.componentMostCommonPcsM()
# pivot that and quash the hierarchal column index that is created when the table is pivoted
mc_comp = components[["item", unit_label, "city"]].pivot(columns="city", index="item")
mc_comp.columns = mc_comp.columns.get_level_values(1)
# the aggregated total of the feature is taken from the most common objects table
mc_feature = fdx.most_common[unit_label]
mc_feature = featuredata.changeSeriesIndexLabels(mc_feature, {x:fdx.dMap.loc[x] for x in mc_feature.index})
# aggregated totals of the parent this is derived from the arguments in kwargs
mc_parent = period_data.parentMostCommon(parent=True)
mc_parent = featuredata.changeSeriesIndexLabels(mc_parent, {x:fdx.dMap.loc[x] for x in mc_parent.index})
# the aggregated totals of all the period data
mc_period = period_data.parentMostCommon(parent=False)
mc_period = featuredata.changeSeriesIndexLabels(mc_period, {x:fdx.dMap.loc[x] for x in mc_period.index})
# add the feature, bassin_label and period results to the components table
mc_comp[this_feature["name"]]= mc_feature
mc_comp[bassin_label] = mc_parent
mc_comp[top] = mc_period
caption_prefix = f'Median {unit_label} der häufigsten Objekte am '
col_widths=[4.5*cm, *[1.2*cm]*(len(mc_comp.columns)-1)]
mc_heatmap_title = Paragraph("Die am häufigsten gefundenen Objekte nach Gemeinden", featuredata.subsection_title)
tables = featuredata.splitTableWidth(mc_comp, gradient=True, caption_prefix=caption_prefix, caption=mc_heat_map_caption,
this_feature=this_feature["name"], vertical_header=True, colWidths=col_widths)
# identify the tables variable as either a list or a Flowable:
if isinstance(tables, (list, np.ndarray)):
grouped_pdf_components = [mc_heatmap_title, featuredata.large_space, *tables]
else:
grouped_pdf_components = [mc_heatmap_title, featuredata.large_space, tables]
new_components = [
featuredata.small_space,
KeepTogether(grouped_pdf_components)
]
pdfcomponents = featuredata.addToDoc(new_components, pdfcomponents)
# notebook display style
aformatter = {x: featuredata.replaceDecimal for x in mc_comp.columns}
mcd = mc_comp.style.format(aformatter).set_table_styles(heat_map_css_styles)
mcd = mcd.background_gradient(axis=None, vmin=mc_comp.min().min(), vmax=mc_comp.max().max(), cmap="YlOrBr")
# remove the index name and column name labels
mcd.index.name = None
mcd.columns.name = None
# rotate the text on the header row
# the .applymap_index method in the
# df.styler module is used for this
mcd = mcd.applymap_index(featuredata.rotateText, axis=1)
# display markdown html
glue(f'{this_feature["slug"]}_mc_heat_map_caption', mc_heat_map_caption, display=False)
glue('thunerseebrienzersee_most_common_heat_map', mcd, display=False)
| Beatenberg | Brienz (BE) | Bönigen | Spiez | Thun | Unterseen | Thunersee/Brienzersee | Erhebungsgebiet Aare | Alle Erhebungsgebiete | |
|---|---|---|---|---|---|---|---|---|---|
| Getränkeflaschen aus Glas, Glasfragmente | 2,0 | 0,0 | 0,0 | 13,0 | 0,0 | 2,0 | 2,5 | 3,0 | 3,0 |
| Expandiertes Polystyrol | 18,5 | 22,0 | 6,5 | 6,5 | 16,0 | 10,5 | 10,5 | 4,0 | 5,0 |
| Fragmentierte Kunststoffe | 44,0 | 39,0 | 101,0 | 4,5 | 24,0 | 20,5 | 17,0 | 18,5 | 18,0 |
| Industriefolie (Kunststoff) | 2,5 | 67,0 | 15,0 | 1,5 | 13,0 | 13,0 | 8,0 | 5,0 | 5,0 |
| Industriepellets (Nurdles) | 2,5 | 0,0 | 3,5 | 0,0 | 0,0 | 0,0 | 0,0 | 0,0 | 0,0 |
| Kunststoff-Bauabfälle | 0,0 | 0,0 | 4,5 | 0,0 | 0,0 | 1,5 | 0,5 | 0,0 | 1,0 |
| Schaumstoffverpackungen/Isolierung | 42,5 | 4,0 | 10,0 | 0,0 | 0,0 | 9,0 | 2,5 | 0,0 | 1,0 |
| Snack-Verpackungen | 12,0 | 39,0 | 6,0 | 0,0 | 9,0 | 10,5 | 5,0 | 8,0 | 9,0 |
| Verpackungsfolien, nicht für Lebensmittel | 4,0 | 6,0 | 0,0 | 0,0 | 0,0 | 3,0 | 0,0 | 0,5 | 0,0 |
| Wattestäbchen/Tupfer | 4,5 | 6,0 | 5,5 | 0,0 | 1,0 | 2,0 | 1,0 | 0,0 | 1,0 |
| Zigarettenfilter | 54,5 | 0,0 | 118,5 | 4,5 | 23,0 | 54,5 | 14,0 | 11,0 | 20,0 |
Abb. 11.6 #
Abbildung 11.6: Median p/100 m der häufigsten Objekte am Thunersee/Brienzersee.
11.2.2. Die am häufigsten gefundenen Objekte im monatlichen Durchschnitt#
Show code cell source
# collect the survey results of the most common objects
# and aggregate code with groupname for each sample
agg_pcs_quantity = {unit_label:"sum", "quantity":"sum"}
groups = ["loc_date","date","code", "groupname"]
# use the index from the most common codes to select from the feature data
m_common_m = fd[(fd.code.isin(fdx.most_common.index))].groupby(groups, as_index=False).agg(agg_pcs_quantity)
start_date = "2020-04-01"
end_date = "2021-03-31"
# set the index to the date column
m_common_m.set_index("date", inplace=True)
m_common_m = m_common_m.sort_index().loc[start_date:end_date]
# set the order of the chart, group the codes by groupname columns and collect the respective object codes
an_order = m_common_m.groupby(["code","groupname"], as_index=False).quantity.sum().sort_values(by="groupname")["code"].values
# use the order array and resample each code for the monthly value
# store in a dict
mgr = {}
for a_code in an_order:
# resample by month
a_cell = m_common_m[(m_common_m.code==a_code)][unit_label].resample("M").mean().fillna(0)
a_cell = round(a_cell, 1)
this_group = {a_code:a_cell}
mgr.update(this_group)
# make df form dict and collect the abbreviated month name set that to index
by_month = pd.DataFrame.from_dict(mgr)
by_month["month"] = by_month.index.map(lambda x: get_month_names('abbreviated', locale=date_lang)[x.month])
by_month.set_index('month', drop=True, inplace=True)
# transpose to get months on the columns and set index to the object description
by_month = by_month.T
by_month["Objekt"] = by_month.index.map(lambda x: fdx.dMap.loc[x])
by_month.set_index("Objekt", drop=True, inplace=True)
# pdf components
# gradient background for .pdf table
monthly_heat_map_gradient = featuredata.colorGradientTable(by_month)
# subsection title and figure caption
mc_monthly_title = Paragraph("Die am häufigsten gefundenen Objekte im monatlichen Durchschnitt", featuredata.subsection_title)
monthly_data_caption = f'{this_feature["name"]}, monatliche Durchschnittsergebnisse p/100 m'
col_widths = [4*cm, *[1.15*cm]*(len(mc_comp.columns))]
d_chart = featuredata.aSingleStyledTable(by_month, vertical_header=True, gradient=True, colWidths=col_widths)
d_capt = featuredata.makeAParagraph(monthly_data_caption, style=featuredata.caption_style)
mc_table = featuredata.tableAndCaption(d_chart, d_capt, colwidths)
new_components = [
KeepTogether([
mc_monthly_title,
featuredata.large_space,
mc_table,
PageBreak()
])
]
pdfcomponents = featuredata.addToDoc(new_components, pdfcomponents)
# remove the index names for .html display
by_month.index.name = None
by_month.columns.name = None
aformatter = {x: featuredata.replaceDecimal for x in by_month.columns}
mcdm = by_month.style.format(aformatter).set_table_styles(heat_map_css_styles).background_gradient(axis=None, cmap="YlOrBr", vmin=by_month.min().min(), vmax=by_month.max().max())
glue("thunerseebrienzersee_monthly_results", mcdm, display=False)
| Apr. | Mai | Juni | Juli | Aug. | Sept. | Okt. | Nov. | Dez. | Jan. | Feb. | März | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Wattestäbchen/Tupfer | 0,0 | 2,0 | 3,0 | 1,5 | 2,3 | 3,0 | 0,7 | 2,4 | 0,5 | 0,5 | 2,2 | 1,0 |
| Getränkeflaschen aus Glas, Glasfragmente | 0,0 | 14,0 | 7,0 | 18,5 | 8,0 | 5,0 | 11,7 | 2,4 | 0,5 | 3,0 | 4,5 | 6,0 |
| Snack-Verpackungen | 2,0 | 6,0 | 9,0 | 9,0 | 18,3 | 11,5 | 1,7 | 10,7 | 2,5 | 10,0 | 19,5 | 13,0 |
| Schaumstoffverpackungen/Isolierung | 0,0 | 1,0 | 15,7 | 6,5 | 35,7 | 7,5 | 2,0 | 0,7 | 4,0 | 3,0 | 3,2 | 18,0 |
| Kunststoff-Bauabfälle | 0,0 | 3,0 | 1,7 | 5,0 | 5,0 | 1,8 | 0,7 | 0,0 | 1,5 | 1,0 | 10,2 | 1,0 |
| Expandiertes Polystyrol | 40,0 | 13,5 | 11,7 | 10,0 | 14,0 | 13,5 | 3,3 | 25,4 | 4,0 | 2,0 | 6,0 | 19,0 |
| Industriefolie (Kunststoff) | 2,0 | 8,5 | 9,3 | 21,5 | 11,0 | 25,2 | 1,7 | 13,6 | 1,0 | 20,5 | 39,0 | 15,0 |
| Industriepellets (Nurdles) | 0,0 | 0,0 | 1,7 | 0,0 | 1,7 | 0,5 | 0,0 | 25,6 | 0,0 | 0,0 | 0,0 | 0,0 |
| Fragmentierte Kunststoffe | 12,0 | 15,0 | 25,0 | 25,5 | 31,7 | 53,5 | 8,3 | 29,9 | 4,5 | 13,0 | 20,5 | 37,0 |
| Zigarettenfilter | 2,0 | 29,0 | 75,7 | 77,0 | 66,7 | 44,2 | 20,3 | 17,3 | 5,0 | 10,5 | 11,2 | 57,0 |
| Verpackungsfolien, nicht für Lebensmittel | 0,0 | 0,0 | 0,0 | 0,0 | 1,0 | 2,2 | 1,0 | 3,3 | 2,5 | 8,0 | 4,2 | 14,0 |
Abb. 11.7 #
Abbildung 11.7: Thunersee/Brienzersee, monatliche Durchschnittsergebnisse p/100 m.
11.3. Verwendungszweck der gefundenen Objekte#
Der Verwendungszweck basiert auf der Verwendung des Objekts, bevor es weggeworfen wurde, oder auf der Artikelbeschreibung, wenn die ursprüngliche Verwendung unbestimmt ist. Identifizierte Objekte werden einer der 260 vordefinierten Kategorien zugeordnet. Die Kategorien werden je nach Verwendung oder Artikelbeschreibung gruppiert.
Abwasser: Objekte, die aus Kläranlagen freigesetzt werden, sprich Objekte, die wahrscheinlich über die Toilette entsorgt werden
Mikroplastik (< 5 mm): fragmentierte Kunststoffe und Kunststoffharze aus der Vorproduktion
Infrastruktur: Artikel im Zusammenhang mit dem Bau und der Instandhaltung von Gebäuden, Strassen und der Wasser-/Stromversorgung
Essen und Trinken: alle Materialien, die mit dem Konsum von Essen und Trinken in Zusammenhang stehen
Landwirtschaft: Materialien z. B. für Mulch und Reihenabdeckungen, Gewächshäuser, Bodenbegasung, Ballenverpackungen. Einschliesslich Hartkunststoffe für landwirtschaftliche Zäune, Blumentöpfe usw.
Tabakwaren: hauptsächlich Zigarettenfilter, einschliesslich aller mit dem Rauchen verbundenen Materialien
Freizeit und Erholung: Objekte, die mit Sport und Freizeit zu tun haben, z. B. Angeln, Jagen, Wandern usw.
Verpackungen ausser Lebensmittel und Tabak: Verpackungsmaterial, das nicht lebensmittel- oder tabakbezogen ist
Plastikfragmente: Plastikteile unbestimmter Herkunft oder Verwendung
Persönliche Gegenstände: Accessoires, Hygieneartikel und Kleidung
Im Anhang (Kapitel 3.6.3) befindet sich die vollständige Liste der identifizierten Objekte, einschliesslich Beschreibungen und Gruppenklassifizierung. Das Kapitel 16 Codegruppen beschreibt jede Codegruppe im Detail und bietet eine umfassende Liste aller Objekte in einer Gruppe.
Show code cell source
# the results are a callable for the components
components = fdx.componentCodeGroupResults()
# pivot that and reomve any hierarchal column index
pt_comp = components[["city", "groupname", '% of total' ]].pivot(columns="city", index="groupname")
pt_comp.columns = pt_comp.columns.get_level_values(1)
# the aggregated codegroup results from the feature
pt_feature = fdx.codegroup_summary["% of total"]
pt_comp[this_feature["name"]] = pt_feature
# the aggregated totals for the parent level
pt_parent = period_data.parentGroupTotals(parent=True, percent=True)
pt_comp[bassin_label] = pt_parent
# the aggregated totals for the period
pt_period = period_data.parentGroupTotals(parent=False, percent=True)
pt_comp[top] = pt_period
# caption
code_group_percent_caption = [
'Verwendungszweck oder Beschreibung der identifizierten Objekte in % der ',
f'Gesamtzahl nach Gemeinden im Erhebungsgebiet {this_feature["name"]}. '
'Fragmentierte Objekte, die nicht eindeutig identifiziert werden können, ',
'werden weiterhin nach ihrer Grösse klassifiziert.'
]
code_group_percent_caption = ''.join(code_group_percent_caption)
# format for data frame
pt_comp.index.name = None
pt_comp.columns.name = None
aformatter = {x: '{:.0%}' for x in pt_comp.columns}
ptd = pt_comp.style.format(aformatter).set_table_styles(heat_map_css_styles).background_gradient(axis=None, vmin=pt_comp.min().min(), vmax=pt_comp.max().max(), cmap="YlOrBr")
ptd = ptd.applymap_index(featuredata.rotateText, axis=1)
caption_prefix = 'Verwendungszweck oder Beschreibung der identifizierten Objekte in % der Gesamtzahl nach Gemeinden: '
col_widths = [4.5*cm, *[1.2*cm]*(len(pt_comp.columns)-1)]
cgpercent_tables = featuredata.splitTableWidth(pt_comp.mul(100).astype(int), gradient=True, caption_prefix=caption_prefix, caption= code_group_percent_caption,
this_feature=this_feature["name"], vertical_header=True, colWidths=col_widths)
glue("thunerseebrienzersee_codegroup_percent_caption", code_group_percent_caption, display=False)
glue("thunerseebrienzersee_codegroup_percent", ptd, display=False)
| Beatenberg | Brienz (BE) | Bönigen | Spiez | Thun | Unterseen | Thunersee/Brienzersee | Erhebungsgebiet Aare | Alle Erhebungsgebiete | |
|---|---|---|---|---|---|---|---|---|---|
| Abwasser | 4% | 2% | 2% | 1% | 1% | 2% | 2% | 4% | 5% |
| Essen und Trinken | 12% | 18% | 5% | 30% | 15% | 14% | 16% | 19% | 19% |
| Freizeit und Erholung | 2% | 5% | 2% | 4% | 6% | 4% | 4% | 5% | 4% |
| Infrastruktur | 27% | 14% | 10% | 29% | 14% | 15% | 17% | 13% | 18% |
| Landwirtschaft | 3% | 20% | 5% | 5% | 18% | 10% | 11% | 7% | 6% |
| Mikroplastik (< 5mm) | 1% | 19% | 1% | 1% | 0% | 3% | 5% | 5% | 8% |
| Persönliche Gegenstände | 0% | 1% | 4% | 2% | 3% | 2% | 2% | 3% | 3% |
| Plastikfragmente | 18% | 9% | 32% | 12% | 18% | 12% | 14% | 14% | 14% |
| Tabakwaren | 25% | 1% | 36% | 8% | 16% | 30% | 21% | 20% | 17% |
| Verpackungen ohne Lebensmittel/Tabak | 9% | 5% | 3% | 2% | 8% | 7% | 6% | 7% | 5% |
| nicht klassifiziert | 0% | 6% | 1% | 6% | 0% | 1% | 2% | 1% | 1% |
Abb. 11.8 #
Abbildung 11.8: Verwendungszweck oder Beschreibung der identifizierten Objekte in % der Gesamtzahl nach Gemeinden im Erhebungsgebiet Thunersee/Brienzersee. Fragmentierte Objekte, die nicht eindeutig identifiziert werden können, werden weiterhin nach ihrer Grösse klassifiziert.
Show code cell source
# pivot that
grouppcs_comp = components[["city", "groupname", unit_label ]].pivot(columns="city", index="groupname")
# quash the hierarchal column index
grouppcs_comp.columns = grouppcs_comp.columns.get_level_values(1)
# the aggregated codegroup results from the feature
pt_feature = fdx.codegroup_summary[unit_label]
grouppcs_comp[this_feature["name"]] = pt_feature
# the aggregated totals for the parent level
pt_parent = period_data.parentGroupTotals(parent=True, percent=False)
grouppcs_comp[bassin_label] = pt_parent
# the aggregated totals for the period
pt_period = period_data.parentGroupTotals(parent=False, percent=False)
grouppcs_comp[top] = pt_period
# color gradient of restults
code_group_pcsm_gradient = featuredata.colorGradientTable(grouppcs_comp)
grouppcs_comp.index.name = None
grouppcs_comp.columns.name = None
# pdf and display output
code_group_pcsm_caption = [
f'Verwendungszweck der gefundenen Objekte Median {unit_label} am ',
f'{this_feature["name"]}. Fragmentierte Objekte, die nicht eindeutig ',
'identifiziert werden können, werden weiterhin nach ihrer Grösse klassifiziert.'
]
code_group_pcsm_caption = ''.join(code_group_pcsm_caption)
caption_prefix = f'Verwendungszweck der gefundenen Objekte Median {unit_label} am '
col_widths = [4.5*cm, *[1.2*cm]*(len(grouppcs_comp.columns)-1)]
cgpcsm_tables = featuredata.splitTableWidth(grouppcs_comp, gradient=True, caption_prefix=caption_prefix,
caption=code_group_pcsm_caption, this_feature=this_feature["name"],
vertical_header=True, colWidths=col_widths)
if isinstance(cgpcsm_tables, (list, np.ndarray)):
new_components = [
*cgpercent_tables,
featuredata.larger_space,
*cgpcsm_tables,
featuredata.larger_space
]
else:
new_components = [
cgpercent_tables,
featuredata.larger_space,
cgpcsm_tables,
featuredata.larger_space
]
pdfcomponents = featuredata.addToDoc(new_components, pdfcomponents)
aformatter = {x: featuredata.replaceDecimal for x in grouppcs_comp.columns}
cgp = grouppcs_comp.style.format(aformatter).set_table_styles(heat_map_css_styles).background_gradient(axis=None, vmin=grouppcs_comp.min().min(), vmax=grouppcs_comp.max().max(), cmap="YlOrBr")
cgp= cgp.applymap_index(featuredata.rotateText, axis=1)
glue("thunerseebrienzersee_codegroup_pcsm_caption", code_group_pcsm_caption, display=False)
glue("thunerseebrienzersee_codegroup_pcsm", cgp, display=False)
| Beatenberg | Brienz (BE) | Bönigen | Spiez | Thun | Unterseen | Thunersee/Brienzersee | Erhebungsgebiet Aare | Alle Erhebungsgebiete | |
|---|---|---|---|---|---|---|---|---|---|
| Abwasser | 8,5 | 12,0 | 5,5 | 0,0 | 3,0 | 4,0 | 3,0 | 3,0 | 3,0 |
| Essen und Trinken | 27,5 | 84,0 | 16,5 | 24,5 | 24,0 | 26,5 | 25,0 | 27,0 | 37,0 |
| Freizeit und Erholung | 4,5 | 24,0 | 5,0 | 1,5 | 6,0 | 7,0 | 4,5 | 6,0 | 6,0 |
| Infrastruktur | 67,5 | 71,0 | 30,5 | 13,5 | 21,0 | 27,0 | 22,5 | 15,0 | 20,0 |
| Landwirtschaft | 7,0 | 78,0 | 15,0 | 2,0 | 13,0 | 15,0 | 9,5 | 6,0 | 7,0 |
| Mikroplastik (< 5mm) | 2,5 | 28,0 | 3,5 | 0,0 | 0,0 | 4,5 | 1,0 | 1,0 | 1,0 |
| Persönliche Gegenstände | 0,0 | 0,0 | 11,0 | 0,0 | 3,0 | 4,5 | 2,0 | 4,0 | 6,0 |
| Plastikfragmente | 44,0 | 39,0 | 101,0 | 4,5 | 24,0 | 20,5 | 17,0 | 18,5 | 18,0 |
| Tabakwaren | 59,5 | 7,0 | 118,5 | 4,5 | 25,0 | 58,0 | 14,0 | 15,0 | 25,0 |
| Verpackungen ohne Lebensmittel/Tabak | 21,5 | 14,0 | 9,0 | 1,5 | 8,0 | 8,5 | 4,5 | 7,5 | 9,0 |
| nicht klassifiziert | 0,0 | 2,0 | 2,0 | 2,5 | 0,0 | 0,5 | 0,5 | 0,0 | 0,0 |
Abb. 11.9 #
Abbildung 11.9: Verwendungszweck der gefundenen Objekte Median p/100 m am Thunersee/Brienzersee. Fragmentierte Objekte, die nicht eindeutig identifiziert werden können, werden weiterhin nach ihrer Grösse klassifiziert.
11.4. Anhang#
11.4.1. Schaumstoffe und Kunststoffe nach Grösse#
Die folgende Tabelle enthält die Komponenten «Gfoam» und «Gfrag», die für die Analyse gruppiert wurden. Objekte, die als Schaumstoffe gekennzeichnet sind, werden als Gfoam gruppiert und umfassen alle geschäumten Polystyrol-Kunststoffe > 0,5 cm. Kunststoffteile und Objekte aus kombinierten Kunststoff- und Schaumstoffmaterialien > 0,5 cm werden für die Analyse als Gfrags gruppiert.
Show code cell source
annex_title = Paragraph("Anhang", featuredata.section_title)
frag_sub_title = Paragraph("Schaumstoffe und Kunststoffe nach Grösse", featuredata.subsection_title)
frag_paras = [
"Die folgende Tabelle enthält die Komponenten «Gfoam» und «Gfrag», die für die Analyse gruppiert wurden. ",
"Objekte, die als Schaumstoffe gekennzeichnet sind, werden als Gfoam gruppiert und umfassen alle geschäumten ",
"Polystyrol-Kunststoffe > 0,5 cm. Kunststoffteile und Objekte aus kombinierten Kunststoff - und Schaumstoffmaterialien > 0,5 ",
"cm werden für die Analyse als Gfrags gruppiert."
]
frag_p = "".join(frag_paras)
frag = Paragraph(frag_p, featuredata.p_style)
frag_caption = [
f'Fragmentierte und geschäumte Kunststoffe nach Grösse am {this_feature["name"]}',
f'Median {unit_label}, Anzahl der gefundenen Objekte und Prozent der Gesamtmenge.'
]
frag_captions = ''.join(frag_caption)
# collect the data before aggregating foams for all locations in the survye area
# group by loc_date and code
# Combine the different sizes of fragmented plastics and styrofoam
# the codes for the foams
before_agg = pd.read_csv("resources/checked_before_agg_sdata_eos_2020_21.csv")
some_foams = ["G81", "G82", "G83", "G74"]
before_agg.rename(columns={"p/100m":unit_label}, inplace=True)
# the codes for the fragmented plastics
some_frag_plas = list(before_agg[before_agg.groupname == "plastic pieces"].code.unique())
mask = ((before_agg.code.isin([*some_frag_plas, *some_foams]))&(before_agg.location.isin(admin_summary["locations_of_interest"])))
agg_pcs_median = {unit_label:"median", "quantity":"sum"}
fd_frags_foams = before_agg[mask].groupby(["loc_date","code"], as_index=False).agg(agg_pcs_quantity)
fd_frags_foams = fd_frags_foams.groupby("code").agg(agg_pcs_median)
fd_frags_foams["item"] = fd_frags_foams.index.map(lambda x: fdx.dMap.loc[x])
fd_frags_foams["% of total"] = (fd_frags_foams.quantity/fd.quantity.sum()).round(2)
# table data
data = fd_frags_foams[["item",unit_label, "quantity", "% of total"]]
data.rename(columns={"item":"Objekt", "quantity":"Objekte (St.)", "% of total":"Anteil"}, inplace=True)
data.set_index("Objekt", inplace=True, drop=True)
data.index.name = None
aformatter = {
f"{unit_label}": lambda x: featuredata.replaceDecimal(x, "de"),
"Objekte (St.)": lambda x: featuredata.thousandsSeparator(int(x), "de"),
"Anteil":'{:.0%}',
}
frags_table = data.style.format(aformatter).set_table_styles(table_css_styles)
glue("thunerseebrienzersee_frag_table_caption", frag_captions, display=False)
glue("thunerseebrienzersee_frags_table", frags_table, display=False)
# pdf components
col_widths = [7*cm, *[2*cm]*len(data.columns)]
d_chart = featuredata.aSingleStyledTable(data, colWidths=col_widths)
d_capt = Paragraph(frag_captions, featuredata.caption_style)
a_dims_table = featuredata.tableAndCaption(d_chart, d_capt, col_widths)
new_components = [
KeepTogether([
annex_title,
featuredata.small_space,
frag_sub_title,
featuredata.smaller_space,
frag,
featuredata.small_space
]),
a_dims_table,
]
pdfcomponents = featuredata.addToDoc(new_components, pdfcomponents)
| p/100 m | Objekte (St.) | Anteil | |
|---|---|---|---|
| Schaumstoffverpackungen/Isolierung | 0,0 | 32 | 1% |
| Objekte aus Kunststoff/Polystyrol 0,5 - 2,5 cm | 0,0 | 5 | 0% |
| Objekte aus Kunststoff/Polystyrol 2,5 - 50 cm | 0,0 | 1 | 0% |
| Objekte aus Kunststoff 0,5 - 2,5 cm | 8,0 | 280 | 7% |
| Objekte aus Kunststoff 2,5 - 50 cm | 7,5 | 228 | 6% |
| Objekte aus Kunststoff > 50 cm | 0,0 | 1 | 0% |
| Objekte aus expandiertem Polystyrol 0,5 - 2,5 cm | 5,5 | 174 | 5% |
| Objekte aus expandiertem Polystyrol 2,5 - 50 cm | 2,5 | 107 | 3% |
| Objekte aus expandiertem Polystyrol > 50 cm | 0,0 | 0 | 0% |
Abb. 11.10 #
Abbildung 11.10: Fragmentierte und geschäumte Kunststoffe nach Grösse am Thunersee/BrienzerseeMedian p/100 m, Anzahl der gefundenen Objekte und Prozent der Gesamtmenge.
11.4.2. Die Erhebungsorte#
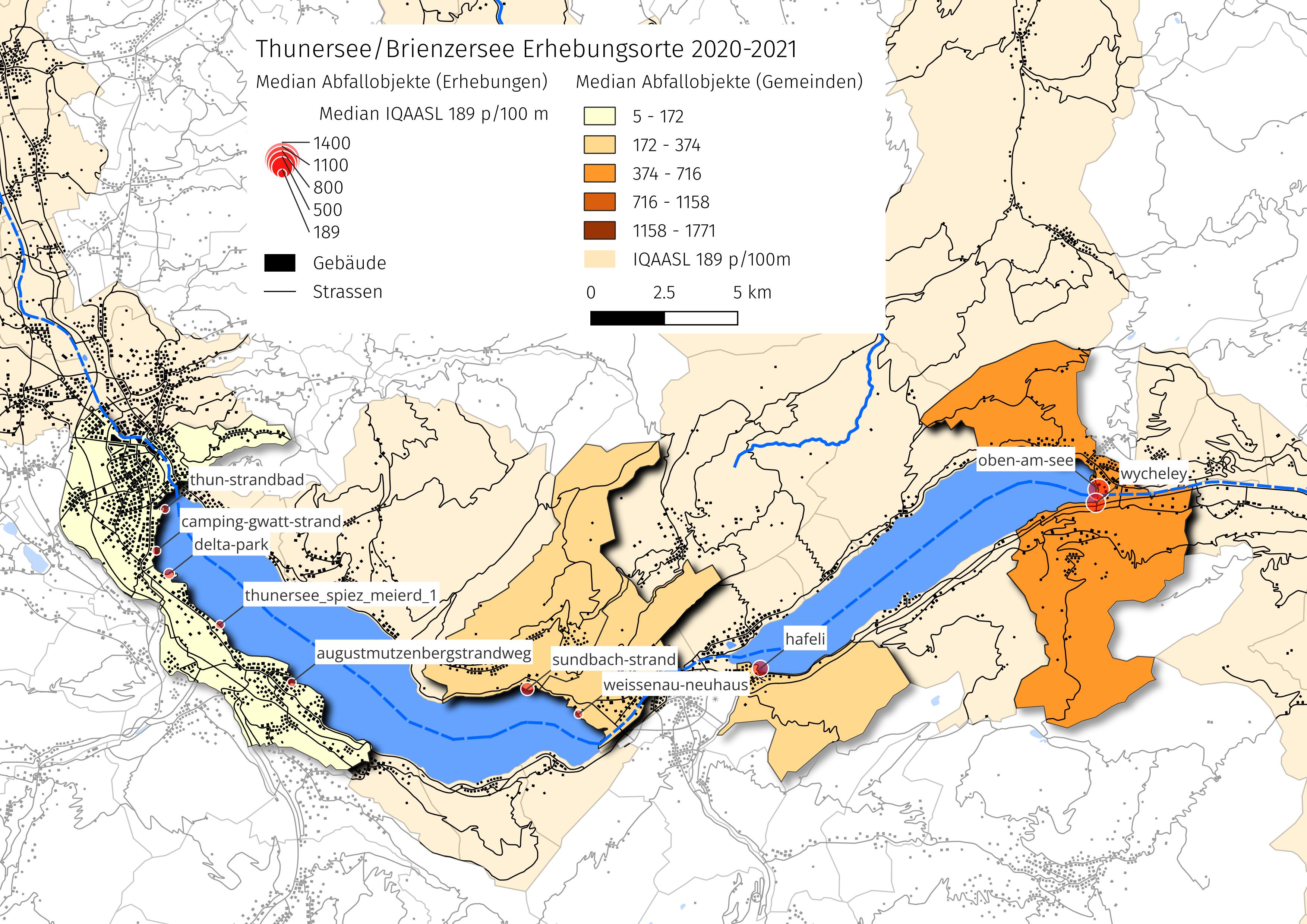
Abb. 11.11 #
Show code cell source
# display the survey locations
disp_columns = ["latitude", "longitude", "city"]
disp_beaches = admin_details.df_beaches.loc[admin_summary["locations_of_interest"]][disp_columns]
disp_beaches.reset_index(inplace=True)
disp_beaches.rename(columns={"city":"stat", "slug":"standort"}, inplace=True)
disp_beaches.set_index("standort", inplace=True, drop=True)
def aStyledTableWithTitleRow(data, header_style: Paragraph = featuredata.styled_table_header, title: str = None,
data_style: Paragraph = featuredata.table_style_centered, colWidths: list = None, style: list = None):
table_data = data.reset_index()
headers = [Paragraph(str(x), header_style) for x in data.columns]
headers = [Paragraph(" ", data_style) , *headers]
if style is None:
style = featuredata.default_table_style
new_rows = []
for a_row in table_data.values.tolist():
if isinstance(a_row[0], str):
row_index = Paragraph(a_row[0], featuredata.table_style_right)
row_data = [Paragraph(str(x), data_style) for x in a_row[1:]]
new_row = [row_index, *row_data]
new_rows.append(new_row)
else:
row_data = [Paragraph(str(x), data_style) for x in a_row[1:]]
new_rows.append(row_data)
table_title_style = [
('FONTNAME', (0,0), (-1,-1), 'Helvetica'),
('FONTSIZE', (0, 0), (-1, -1), 12),
('ROWBACKGROUND', (0,0), (-1,-1), [colors.white]),
('TOPPADDING', (0, 0), (-1, -1), 3),
('BOTTOMPADDING', (0, 0), (-1, -1), 3)
]
table_title = Table([[title]], style=table_title_style, colWidths=sum(colWidths))
new_table = [[table_title], headers, *new_rows]
table = Table(new_table, style=style, colWidths=colWidths, repeatRows=2)
return table
# make this into a pdf table
location_subsection = Paragraph("Die Erhebungsorte und Inventar der Objekte", featuredata.subsection_title)
col_widths = [6*cm, 2.2*cm, 2.2*cm, 3*cm]
pdf_table = aStyledTableWithTitleRow(disp_beaches, title="Die Erhebungsorte", colWidths=col_widths)
disp_beaches
| latitude | longitude | stat | |
|---|---|---|---|
| standort | |||
| weissenau-neuhaus | 46.676583 | 7.817528 | Unterseen |
| thun-strandbad | 46.739939 | 7.633520 | Thun |
| oben-am-see | 46.744451 | 8.049921 | Brienz (BE) |
| thunersee_spiez_meierd_1 | 46.704437 | 7.657882 | Spiez |
| delta-park | 46.720078 | 7.635304 | Spiez |
| sundbach-strand | 46.684386 | 7.794768 | Beatenberg |
| wycheley | 46.740370 | 8.048640 | Brienz (BE) |
| camping-gwatt-strand | 46.727140 | 7.629620 | Thun |
| augustmutzenbergstrandweg | 46.686640 | 7.689760 | Spiez |
| hafeli | 46.690283 | 7.898592 | Bönigen |
11.4.3. Inventar der Objekte#
Show code cell source
pd.set_option("display.max_rows", None)
complete_inventory = fdx.code_summary.copy()
complete_inventory["quantity"] = complete_inventory["quantity"].map(lambda x: featuredata.thousandsSeparator(x, language))
complete_inventory["% of total"] = complete_inventory["% of total"].astype(int)
complete_inventory[unit_label] = complete_inventory[unit_label].astype(int)
complete_inventory.rename(columns=featuredata.inventory_table_de, inplace=True)
# inventory_subsection = Paragraph("Inventar der Objekte", featuredata.subsection_title)
col_widths=[1.2*cm, 5.5*cm, 2.2*cm, 1.5*cm, 1.5*cm, 2.4*cm, 1.5*cm]
inventory_table = aStyledTableWithTitleRow(complete_inventory, title="Inventar der Objekte", colWidths=col_widths)
new_map_image = Image('resources/maps/thunerseebrienzersee_location_labels.jpeg', width=cm*14, height=11*cm, kind="proportional", hAlign= "CENTER")
new_components = [
KeepTogether([
featuredata.large_space,
location_subsection,
featuredata.small_space,
new_map_image,
featuredata.small_space,
pdf_table,
]),
featuredata.large_space,
inventory_table
]
pdfcomponents = featuredata.addToDoc(new_components, pdfcomponents)
complete_inventory.sort_values(by="Objekte (St.)", ascending=False)
| Objekte | Objekte (St.) | Anteil | p/100 m | Häufigkeitsrate | Material | |
|---|---|---|---|---|---|---|
| code | ||||||
| G905 | Haarspangen, Haargummis, persönliche Accessoir... | 9 | 0 | 0 | 16 | Plastik |
| G941 | Verpackungsfolien, nicht für Lebensmittel | 83 | 2 | 0 | 44 | Plastik |
| G22 | Deckel für Chemikalien, Reinigungsmittel (Ohne... | 8 | 0 | 0 | 8 | Plastik |
| G100 | Medizin; Behälter/Röhrchen/Verpackungen | 8 | 0 | 0 | 16 | Plastik |
| G65 | Eimer | 8 | 0 | 0 | 8 | Plastik |
| G48 | Seile, synthetische | 8 | 0 | 0 | 13 | Plastik |
| G928 | Bänder und Schleifen | 8 | 0 | 0 | 8 | Plastik |
| G33 | Einwegartikel; Tassen/Becher & Deckel | 8 | 0 | 0 | 16 | Plastik |
| G27 | Zigarettenfilter | 748 | 19 | 14 | 88 | Plastik |
| G159 | Kork | 7 | 0 | 0 | 16 | Holz |
| G175 | Getränkedosen (Dosen, Getränke) | 7 | 0 | 0 | 13 | Metall |
| G89 | Kunststoff-Bauabfälle | 65 | 1 | 0 | 50 | Plastik |
| G198 | Andere Metallteile < 50 cm | 6 | 0 | 0 | 16 | Metall |
| G73 | Gegenstände aus Schaumstoff & Teilstücke (nich... | 6 | 0 | 0 | 13 | Plastik |
| Gfrags | Fragmentierte Kunststoffe | 515 | 13 | 17 | 91 | Plastik |
| G148 | Kartonkisten und Stücke | 5 | 0 | 0 | 8 | Papier |
| G34 | Besteck, Teller und Tabletts | 5 | 0 | 0 | 13 | Plastik |
| G4 | Kleine Plastikbeutel; Gefrierbeutel, Zippsäckc... | 5 | 0 | 0 | 11 | Plastik |
| G191 | Draht und Gitter | 5 | 0 | 0 | 11 | Metall |
| G155 | Feuerwerkspapierhülsen und -fragmente | 5 | 0 | 0 | 13 | Papier |
| G125 | Luftballons und Luftballonstäbchen | 5 | 0 | 0 | 11 | Gummi |
| G170 | Holz (verarbeitet) | 5 | 0 | 0 | 13 | Holz |
| G931 | (Absperr)band für Absperrungen, Polizei, Baust... | 5 | 0 | 0 | 5 | Plastik |
| G917 | Blähton | 5 | 0 | 0 | 11 | Glas |
| G940 | Schaumstoff EVA (flexibler Kunststoff) | 5 | 0 | 0 | 5 | Plastik |
| G194 | Kabel, Metalldraht oft in Gummi- oder Kunststo... | 4 | 0 | 0 | 8 | Metall |
| G96 | Hygienebinden/Höscheneinlagen/Tampons und Appl... | 4 | 0 | 0 | 11 | Plastik |
| G925 | Pakete: Trockenmittel/Feuchtigkeitsabsorber, m... | 4 | 0 | 0 | 5 | Plastik |
| G59 | Monofile Angelschnur (Angeln) | 4 | 0 | 0 | 8 | Plastik |
| G904 | Feuerwerkskörper; Raketenkappen | 39 | 1 | 0 | 38 | Plastik |
| G21 | Getränke-Deckel, Getränkeverschluss | 38 | 1 | 0 | 38 | Plastik |
| G117 | Styropor < 5mm | 36 | 0 | 0 | 33 | Plastik |
| G67 | Industriefolie (Kunststoff) | 352 | 9 | 8 | 83 | Plastik |
| G95 | Wattestäbchen/Tupfer | 35 | 0 | 1 | 52 | Plastik |
| G156 | Papierfragmente | 35 | 0 | 0 | 22 | Papier |
| G944 | Pelletmasse aus dem Spritzgussverfahren | 34 | 0 | 0 | 8 | Plastik |
| G106 | Kunststofffragmente eckig <5mm | 34 | 0 | 0 | 25 | Plastik |
| G23 | unidentifizierte Deckel | 30 | 0 | 0 | 30 | Plastik |
| G176 | Konservendosen (Lebensmitteldosen) | 3 | 0 | 0 | 5 | Metall |
| G158 | Sonstige Gegenstände aus Papier | 3 | 0 | 0 | 8 | Papier |
| G146 | Papier, Karton | 3 | 0 | 0 | 2 | Papier |
| G913 | Schnuller | 3 | 0 | 0 | 8 | Plastik |
| G165 | Glacestengel (Eisstiele), Zahnstocher, Essstäb... | 3 | 0 | 0 | 8 | Holz |
| G933 | Taschen, Etuis für Zubehör, Brillen, Elektroni... | 3 | 0 | 0 | 8 | Plastik |
| G914 | Büroklammern, Wäscheklammern, Gebrauchsgegenst... | 3 | 0 | 0 | 8 | Plastik |
| G37 | Netzbeutel, Netztasche, Netzsäcke | 3 | 0 | 0 | 8 | Plastik |
| G6 | Flaschen und Behälter aus Kunststoff, nicht fü... | 3 | 0 | 0 | 2 | Plastik |
| G134 | Sonstiges Gummi | 3 | 0 | 0 | 5 | Gummi |
| G921 | Keramikfliesen und Bruchstücke | 3 | 0 | 0 | 8 | Glas |
| Gfoam | Expandiertes Polystyrol | 281 | 7 | 10 | 83 | Plastik |
| G24 | Ringe von Plastikflaschen/Behältern | 28 | 0 | 0 | 36 | Plastik |
| G213 | Paraffinwachs | 27 | 0 | 0 | 33 | Chemikalien |
| G936 | Folien für Gewächshäuser | 26 | 0 | 0 | 22 | Plastik |
| G177 | Verpackungen aus Aluminiumfolie | 26 | 0 | 0 | 36 | Metall |
| G50 | Schnur < 1cm | 25 | 0 | 0 | 33 | Plastik |
| G922 | Etiketten, Strichcodes | 24 | 0 | 0 | 33 | Plastik |
| G30 | Snack-Verpackungen | 228 | 6 | 5 | 77 | Plastik |
| G153 | Papierbecher, Lebensmittelverpackungen aus Pap... | 21 | 0 | 0 | 11 | Papier |
| G186 | Industrieschrott | 20 | 0 | 0 | 25 | Metall |
| G49 | Seile > 1cm | 2 | 0 | 0 | 5 | Plastik |
| G918 | Sicherheitsnadeln, Büroklammern, kleine Gebrau... | 2 | 0 | 0 | 5 | Metall |
| G2 | Säcke, Taschen | 2 | 0 | 0 | 2 | Plastik |
| G174 | Aerosolspraydosen | 2 | 0 | 0 | 5 | Metall |
| G26 | Feuerzeug | 2 | 0 | 0 | 5 | Plastik |
| G103 | Kunststofffragmente rund <5mm | 2 | 0 | 0 | 5 | Plastik |
| G124 | Andere Kunststoff | 2 | 0 | 0 | 5 | Plastik |
| G101 | Robidog Hundekot-Säcklein, andere Hundekotsäck... | 2 | 0 | 0 | 5 | Plastik |
| G133 | Kondome einschließlich Verpackungen | 2 | 0 | 0 | 5 | Gummi |
| G25 | Tabak; Kunststoffverpackungen, Behälter | 19 | 0 | 0 | 27 | Plastik |
| G10 | Lebensmittelbehälter zum einmaligen Gebrauch a... | 18 | 0 | 0 | 27 | Plastik |
| G201 | Gläser, einschliesslich Stücke | 18 | 0 | 0 | 16 | Glas |
| G211 | Sonstiges medizinisches Material | 17 | 0 | 0 | 27 | Plastik |
| G35 | Strohhalme und Rührstäbchen | 17 | 0 | 0 | 30 | Plastik |
| G87 | Abdeckklebeband/Verpackungsklebeband | 16 | 0 | 0 | 19 | Plastik |
| G31 | Schleckstengel, Stengel von Lutscher | 16 | 0 | 0 | 33 | Plastik |
| G32 | Spielzeug und Partyartikel | 16 | 0 | 0 | 25 | Plastik |
| G908 | Klebeband; elektrisch, isolierend | 16 | 0 | 0 | 22 | Plastik |
| G91 | Bio-Filtermaterial / Trägermaterial aus Kunst... | 16 | 0 | 0 | 27 | Plastik |
| G74 | Schaumstoffverpackungen/Isolierung | 158 | 4 | 2 | 66 | Plastik |
| G200 | Getränkeflaschen aus Glas, Glasfragmente | 141 | 3 | 2 | 72 | Glas |
| G66 | Umreifungsbänder; Hartplastik für Verpackung f... | 14 | 0 | 0 | 33 | Plastik |
| G178 | Kronkorken, Lasche von Dose/Ausfreisslachen | 14 | 0 | 0 | 25 | Metall |
| G943 | Zäune Landwirtschaft, Kunststoff | 14 | 0 | 0 | 8 | Plastik |
| G204 | Baumaterial; Ziegel, Rohre, Zement | 14 | 0 | 0 | 16 | Glas |
| G208 | Glas oder Keramikfragmente >2.5 cm | 14 | 0 | 0 | 11 | Glas |
| G927 | Plastikschnur von Rasentrimmern, die zum Schne... | 13 | 0 | 0 | 16 | Plastik |
| G70 | Schrotflintenpatronen | 13 | 0 | 0 | 22 | Plastik |
| G210 | Sonstiges Glas/Keramik Materialien | 12 | 0 | 0 | 5 | Glas |
| G90 | Blumentöpfe aus Plastik | 12 | 0 | 0 | 19 | Plastik |
| G112 | Industriepellets (Nurdles) | 115 | 3 | 0 | 11 | Plastik |
| G942 | Kunststoffspäne von Drehbänken, CNC-Bearbeitung | 11 | 0 | 0 | 11 | Plastik |
| G3 | Einkaufstaschen, Shoppingtaschen | 11 | 0 | 0 | 19 | Plastik |
| G98 | Windeln – Feuchttücher | 10 | 0 | 0 | 19 | Plastik |
| G923 | Taschentücher, Toilettenpapier, Servietten, Pa... | 10 | 0 | 0 | 19 | Papier |
| G149 | Papierverpackungen | 10 | 0 | 0 | 11 | Papier |
| G203 | Geschirr aus Keramik oder Glas, Tassen, Teller... | 10 | 0 | 0 | 11 | Glas |
| G152 | Papier &Karton;Zigarettenschachteln, Papier/Ka... | 10 | 0 | 0 | 16 | Papier |
| G131 | Gummibänder | 10 | 0 | 0 | 19 | Gummi |
| G29 | Kämme, Bürsten und Sonnenbrillen | 1 | 0 | 0 | 2 | Plastik |
| G28 | Stifte, Deckel, Druckbleistifte usw. | 1 | 0 | 0 | 2 | Plastik |
| G43 | Sicherheitsetiketten, Siegel für Fischerei ode... | 1 | 0 | 0 | 2 | Plastik |
| G138 | Schuhe und Sandalen | 1 | 0 | 0 | 2 | Stoff |
| G114 | Folien <5mm | 1 | 0 | 0 | 2 | Plastik |
| G36 | Säcke aus strapazierfähigem Kunststoff für 25 ... | 1 | 0 | 0 | 2 | Plastik |
| G919 | Nägel, Schrauben, Bolzen usw. | 1 | 0 | 0 | 2 | Metall |
| G135 | Kleidung, Fussbekleidung, Kopfbedeckung, Hands... | 1 | 0 | 0 | 2 | Stoff |
| G12 | Kosmetika, Behälter für Körperpflegeprodukte, ... | 1 | 0 | 0 | 2 | Plastik |
| G129 | Schläuche und Gummiplatten | 1 | 0 | 0 | 2 | Gummi |
| G901 | Medizinische Masken, synthetische | 1 | 0 | 0 | 2 | Plastik |
| G64 | Kotflügel | 1 | 0 | 0 | 2 | Plastik |
| G926 | Kaugummi, enthält oft Kunststoffe | 1 | 0 | 0 | 2 | Plastik |
| G71 | Schuhe Sandalen | 1 | 0 | 0 | 2 | Plastik |
| G214 | Öl/Teer | 1 | 0 | 0 | 2 | Chemikalien |
| G11 | Kosmetika für den Strand, z.B. Sonnencreme | 1 | 0 | 0 | 2 | Plastik |
| G938 | Zahnstocher, Zahnseide Kunststoff | 1 | 0 | 0 | 2 | Plastik |
| G182 | Angeln; Haken, Gewichte, Köder, Senkblei, usw. | 1 | 0 | 0 | 2 | Metall |
| G161 | Verarbeitetes Holz | 1 | 0 | 0 | 2 | Holz |
| G939 | Kunststoffblumen, Kunststoffpflanzen | 1 | 0 | 0 | 2 | Plastik |
| G197 | sonstiges Metall | 1 | 0 | 0 | 2 | Metall |
| G111 | Kugelförmige Pellets < 5mm | 1 | 0 | 0 | 2 | Plastik |
| G190 | Farbtöpfe, Farbbüchsen, ( Farbeimer) | 1 | 0 | 0 | 2 | Metall |
| G97 | Behälter von Toilettenerfrischer | 1 | 0 | 0 | 2 | Plastik |
| G167 | Streichhölzer oder Feuerwerke | 1 | 0 | 0 | 2 | Holz |
| G20 | Laschen und Deckel | 1 | 0 | 0 | 2 | Plastik |
| G202 | Glühbirnen | 1 | 0 | 0 | 2 | Glas |
| G930 | Schaumstoff-Ohrstöpsel | 1 | 0 | 0 | 2 | Plastik |
| G93 | Kabelbinder | 1 | 0 | 0 | 2 | Plastik |
| G902 | Medizinische Masken, Stoff | 0 | 0 | 0 | 0 | Stoff |
| G945 | Rasierklingen | 0 | 0 | 0 | 0 | Metall |
| G900 | Handschuhe Latex, persönliche Schutzausrüstung | 0 | 0 | 0 | 0 | Gummi |
| G903 | Behälter und Packungen für Handdesinfektionsmi... | 0 | 0 | 0 | 0 | Plastik |
| G104 | Kunststofffragmente abgerundet / rundlich <5m... | 0 | 0 | 0 | 0 | Plastik |
| G88 | Telefon inkl. Teile | 0 | 0 | 0 | 0 | Plastik |
| G102 | Flip-Flops | 0 | 0 | 0 | 0 | Plastik |
| G9 | Flaschen und Behälter für Reinigungsmittel und... | 0 | 0 | 0 | 0 | Plastik |
| G123 | Polyurethan-Granulat < 5mm | 0 | 0 | 0 | 0 | Plastik |
| G99 | Spritzen - Nadeln | 0 | 0 | 0 | 0 | Plastik |
| G84 | CD oder CD-Hülle | 0 | 0 | 0 | 0 | Plastik |
| G8 | Getränkeflaschen > 0,5L | 0 | 0 | 0 | 0 | Plastik |
| G999 | Keine Gegenstände bei dieser Erhebung/Studie g... | 0 | 0 | 0 | 0 | Unbekannt |
| G713 | Skiförderband | 0 | 0 | 0 | 0 | Plastik |
| G712 | Skihandschuhe | 0 | 0 | 0 | 0 | Stoff |
| G122 | Kunststofffragmente (>1mm) | 0 | 0 | 0 | 0 | Plastik |
| G119 | Folienartiger Kunststoff (>1mm) | 0 | 0 | 0 | 0 | Plastik |
| G105 | Kunststofffragmente subangulär <5mm | 0 | 0 | 0 | 0 | Plastik |
| G108 | Scheibenförmige Pellets <5mm | 0 | 0 | 0 | 0 | Plastik |
| G711 | Handwärmer | 0 | 0 | 0 | 0 | Plastik |
| G929 | Elektronik und Teile; Sensoren, Headsets usw. | 0 | 0 | 0 | 0 | Metall |
| G113 | Fäden <5mm | 0 | 0 | 0 | 0 | Plastik |
| G932 | Bio-Beads, Mikroplastik für die Abwasserbehand... | 0 | 0 | 0 | 0 | Plastik |
| G109 | Flache Pellets <5mm | 0 | 0 | 0 | 0 | Plastik |
| G934 | Sandsäcke, Kunststoff für Hochwasser- und Eros... | 0 | 0 | 0 | 0 | Plastik |
| G935 | Gummi-Puffer für Geh- und Wanderstöcke und Tei... | 0 | 0 | 0 | 0 | Plastik |
| G92 | Köderbehälter | 0 | 0 | 0 | 0 | Plastik |
| G115 | Schaumstoff <5mm | 0 | 0 | 0 | 0 | Plastik |
| G906 | Kaffeekapseln Aluminium | 0 | 0 | 0 | 0 | Metall |
| G937 | Pheromonköder für Weinberge | 0 | 0 | 0 | 0 | Plastik |
| G116 | Granulat <5mm | 0 | 0 | 0 | 0 | Plastik |
| G916 | Bleistifte und Bruchstücke | 0 | 0 | 0 | 0 | Holz |
| G915 | Reflektoren, Mobilitätsartikel aus Kunststoff | 0 | 0 | 0 | 0 | Plastik |
| G118 | Kleine Industrielle Kügelchen <5mm | 0 | 0 | 0 | 0 | Plastik |
| G94 | Tischtuch | 0 | 0 | 0 | 0 | Plastik |
| G107 | Zylindrische Pellets <5mm | 0 | 0 | 0 | 0 | Plastik |
| G907 | Kaffeekapseln aus Kunststoff | 0 | 0 | 0 | 0 | Plastik |
| G162 | Kisten | 0 | 0 | 0 | 0 | Holz |
| G62 | Schwimmer für Netze | 0 | 0 | 0 | 0 | Plastik |
| G710 | Ski / Snowboards (Ski, Befestigungen und ander... | 0 | 0 | 0 | 0 | Plastik |
| G709 | Teller von Skistock (runder Teil aus Plastik u... | 0 | 0 | 0 | 0 | Plastik |
| G141 | Teppiche | 0 | 0 | 0 | 0 | Stoff |
| G142 | Seil, Schnur oder Netze | 0 | 0 | 0 | 0 | Stoff |
| G143 | Segel und Segeltuch | 0 | 0 | 0 | 0 | Stoff |
| G144 | Tampons | 0 | 0 | 0 | 0 | Stoff |
| G207 | Tonkrüge zum Fangen von Kraken | 0 | 0 | 0 | 0 | Glas |
| G205 | Leuchtstoffröhren | 0 | 0 | 0 | 0 | Glas |
| G145 | Andere Textilien | 0 | 0 | 0 | 0 | Stoff |
| G199 | Andere Metallteile > 50 cm | 0 | 0 | 0 | 0 | Metall |
| G147 | Papiertragetaschen, (Papiertüten) | 0 | 0 | 0 | 0 | Papier |
| G196 | Grosse metallische Gegenstände | 0 | 0 | 0 | 0 | Metall |
| G195 | Batterien (Haushalt) | 0 | 0 | 0 | 0 | Metall |
| G193 | Teile von Autos und Autobatterien | 0 | 0 | 0 | 0 | Metall |
| G150 | Milchkartons, Tetrapack | 0 | 0 | 0 | 0 | Papier |
| G19 | Autoteile | 0 | 0 | 0 | 0 | Plastik |
| G188 | Andere Kanister/Behälter < 4 L | 0 | 0 | 0 | 0 | Metall |
| G151 | Tetrapack, Kartons | 0 | 0 | 0 | 0 | Papier |
| G185 | Behälter mittlerer Grösse | 0 | 0 | 0 | 0 | Metall |
| G183 | Teile von Angelhaken | 0 | 0 | 0 | 0 | Metall |
| G181 | Geschirr aus Metall, Tassen, Besteck usw. | 0 | 0 | 0 | 0 | Metall |
| G180 | Haushaltsgeräte | 0 | 0 | 0 | 0 | Metall |
| G179 | Einweg Grill | 0 | 0 | 0 | 0 | Metall |
| G154 | Zeitungen oder Zeitschriften | 0 | 0 | 0 | 0 | Papier |
| G157 | Papier | 0 | 0 | 0 | 0 | Papier |
| G160 | Paletten | 0 | 0 | 0 | 0 | Holz |
| G173 | Sonstiges | 0 | 0 | 0 | 0 | Holz |
| G172 | Sonstiges Holz > 50 cm | 0 | 0 | 0 | 0 | Holz |
| G171 | Sonstiges Holz < 50cm | 0 | 0 | 0 | 0 | Holz |
| G17 | Kartuschen von Kartuschen-spritzpistolen | 0 | 0 | 0 | 0 | Plastik |
| G168 | Holzbretter | 0 | 0 | 0 | 0 | Holz |
| G140 | Sack oder Beutel (Tragetasche), Jute oder Hanf | 0 | 0 | 0 | 0 | Stoff |
| G14 | Flaschen für Motoröl (Motorölflaschen) | 0 | 0 | 0 | 0 | Plastik |
| G139 | Rucksäcke | 0 | 0 | 0 | 0 | Stoff |
| G61 | Sonstiges Angelzubehör | 0 | 0 | 0 | 0 | Plastik |
| G708 | Skistöcke | 0 | 0 | 0 | 0 | Metall |
| G707 | Skiausrüstungsetikett | 0 | 0 | 0 | 0 | Plastik |
| G706 | Skiabonnement | 0 | 0 | 0 | 0 | Plastik |
| G705 | Schrauben und Bolzen | 0 | 0 | 0 | 0 | Metall |
| G704 | Seilbahnbürsten | 0 | 0 | 0 | 0 | Plastik |
| G703 | Pistenmarkierungspfosten (Plastik) | 0 | 0 | 0 | 0 | Plastik |
| G702 | Pistenmarkierungspfosten (Holz) | 0 | 0 | 0 | 0 | Holz |
| G7 | Getränkeflaschen < = 0,5 l | 0 | 0 | 0 | 0 | Plastik |
| G68 | Fiberglas-Fragmente | 0 | 0 | 0 | 0 | Plastik |
| G126 | Bälle | 0 | 0 | 0 | 0 | Gummi |
| G128 | Reifen und Antriebsriemen | 0 | 0 | 0 | 0 | Gummi |
| G63 | Bojen | 0 | 0 | 0 | 0 | Plastik |
| G166 | Farbpinsel | 0 | 0 | 0 | 0 | Holz |
| G60 | Lichtstab, Knicklicht, Glow-sticks | 0 | 0 | 0 | 0 | Plastik |
| G137 | Kleidung, Handtücher und Lappen | 0 | 0 | 0 | 0 | Stoff |
| G13 | Flaschen, Behälter, Fässer zum Transportieren ... | 0 | 0 | 0 | 0 | Plastik |
| G56 | Verhedderte Netze | 0 | 0 | 0 | 0 | Plastik |
| G55 | Angelschnur (verwickelt) | 0 | 0 | 0 | 0 | Plastik |
| G53 | Netze und Teilstücke < 50cm | 0 | 0 | 0 | 0 | Plastik |
| G52 | Netze und Teilstücke | 0 | 0 | 0 | 0 | Plastik |
| G51 | Fischernetz | 0 | 0 | 0 | 0 | Plastik |
| G5 | Plastiksäcke/ Plastiktüten | 0 | 0 | 0 | 0 | Plastik |
| G132 | Schwimmer (Angeln) | 0 | 0 | 0 | 0 | Gummi |
| G41 | Handschuhe Industriell/Professionell | 0 | 0 | 0 | 0 | Plastik |
| G40 | Handschuhe Haushalt/Garten | 0 | 0 | 0 | 0 | Plastik |
| G39 | Handschuhe | 0 | 0 | 0 | 0 | Plastik |
| G38 | Abdeckungen; Kunststoffverpackungen, Folien zu... | 0 | 0 | 0 | 0 | Plastik |
| G136 | Schuhe | 0 | 0 | 0 | 0 | Stoff |
| G1 | Sixpack-Ringe | 0 | 0 | 0 | 0 | Plastik |