
Show code cell source
# -*- coding: utf8 -*-
# This is a report using the data from IQAASL.
# IQAASL was a project funded by the Swiss Confederation
# It produces a summary of litter survey results for a defined region.
# These charts serve as the models for the development of plagespropres.ch
# The data is gathered by volunteers.
# Please remember all copyrights apply, please give credit when applicable
# The repo is maintained by the community effective January 01, 2022
# There is ample opportunity to contribute, learn and teach
# contact dev@hammerdirt.ch
# Dies ist ein Bericht, der die Daten von IQAASL verwendet.
# IQAASL war ein von der Schweizerischen Eidgenossenschaft finanziertes Projekt.
# Es erstellt eine Zusammenfassung der Ergebnisse der Littering-Umfrage für eine bestimmte Region.
# Diese Grafiken dienten als Vorlage für die Entwicklung von plagespropres.ch.
# Die Daten werden von Freiwilligen gesammelt.
# Bitte denken Sie daran, dass alle Copyrights gelten, bitte geben Sie den Namen an, wenn zutreffend.
# Das Repo wird ab dem 01. Januar 2022 von der Community gepflegt.
# Es gibt reichlich Gelegenheit, etwas beizutragen, zu lernen und zu lehren.
# Kontakt dev@hammerdirt.ch
# Il s'agit d'un rapport utilisant les données de IQAASL.
# IQAASL était un projet financé par la Confédération suisse.
# Il produit un résumé des résultats de l'enquête sur les déchets sauvages pour une région définie.
# Ces tableaux ont servi de modèles pour le développement de plagespropres.ch
# Les données sont recueillies par des bénévoles.
# N'oubliez pas que tous les droits d'auteur s'appliquent, veuillez indiquer le crédit lorsque cela est possible.
# Le dépôt est maintenu par la communauté à partir du 1er janvier 2022.
# Il y a de nombreuses possibilités de contribuer, d'apprendre et d'enseigner.
# contact dev@hammerdirt.ch
# sys, file and nav packages:
import datetime as dt
import locale
# math packages:
import pandas as pd
import numpy as np
from scipy import stats
import statsmodels.api as sm
from statsmodels.distributions.empirical_distribution import ECDF
from statsmodels.stats.stattools import medcouple
from scipy.optimize import newton
from scipy.special import digamma
import math
# charting:
import matplotlib as mpl
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
from matplotlib import ticker
from matplotlib.gridspec import GridSpec
import seaborn as sns
# home brew utitilties
import resources.chart_kwargs as ck
import resources.sr_ut as sut
# build report
import reportlab
from reportlab.platypus.flowables import Flowable
from reportlab.platypus import SimpleDocTemplate, Paragraph,PageBreak, KeepTogether
from reportlab.lib.pagesizes import A4
from reportlab.lib.units import cm
from reportlab.platypus import Table, TableStyle
# the module that has all the methods for handling the data
import resources.featuredata as featuredata
from resources.featuredata import makeAList, small_space, large_space, aSingleStyledTable, smallest_space
from resources.featuredata import caption_style, subsection_title, title_style, block_quote_style
from resources.featuredata import figureAndCaptionTable, tableAndCaption, aStyledTableWithTitleRow
from resources.featuredata import sectionParagraphs, section_title, addToDoc, makeAParagraph, bold_block
# images and display
import IPython
from IPython.display import HTML
import matplotlib.image as mpimg
from myst_nb import glue
loc = locale.getlocale()
lang = "de_CH.utf8"
locale.setlocale(locale.LC_ALL, lang)
# set some parameters:
start_date = '2020-03-01'
end_date ='2021-05-31'
# name of the output folder:
name_of_project = 'threshold_values'
save_fig_prefix = "resources/output/"
save_figure_kwargs = {
"fname": None,
"dpi": 300.0,
"format": "jpeg",
"bbox_inches": None,
"pad_inches": 0,
"bbox_inches": 'tight',
"facecolor": 'auto',
"edgecolor": 'auto',
"backend": None,
}
# the scale for pieces per meter and the column and chart label for the units
reporting_unit = 100
unit_label = 'p/100 m'
# get your data:
survey_data = pd.read_csv('resources/checked_sdata_eos_2020_21.csv')
dfBeaches = pd.read_csv("resources/beaches_with_land_use_rates.csv")
dfCodes = pd.read_csv("resources/codes_with_group_names_2015.csv")
dfDims = pd.read_csv("resources/corrected_dims.csv")
# set the index of the beach data to location slug
dfBeaches.set_index('location', inplace=True)
# index the code data
dfCodes.set_index("code", inplace=True)
# make a map to the code descriptions
code_description_map = dfCodes.description
# make a map to the code descriptions
code_material_map = dfCodes.material
# this defines the css rules for the note-book table displays
header_row = {'selector': 'th:nth-child(1)', 'props': f'background-color: #FFF; font-size:20px; text-align:left;'}
even_rows = {"selector": 'tr:nth-child(even)', 'props': f'background-color: rgba(139, 69, 19, 0.08);'}
odd_rows = {'selector': 'tr:nth-child(odd)', 'props': 'background: #FFF;'}
table_font = {'selector': 'tr', 'props': 'font-size: 20px;'}
table_data = {'selector': 'td', 'props': 'padding:6px;'}
table_css_styles = [even_rows, odd_rows, table_font, header_row, table_data]
14. Basiswerte für Abfallobjekte an Gewässern#
Basiswerte (BVs), die auch als Benchmarks bezeichnet werden, sind die Mengen oder Werte, die zur statistischen Definition einer Situation verwendet werden. Die BVs beziehen sich auf eine Reihe von Daten, die sowohl zeitlich als auch geografisch begrenzt sind und auch als Referenzpunkt oder Basisperiode bezeichnet werden. BVs sind die Grössen, an denen der Fortschritt gemessen wird. In dieser Hinsicht sind die BVs eng mit den Daten und den zu ihrer Erhebung verwendeten Methoden verbunden.
14.1. Zählen von Abfallobjekten am Strand: ein Überblick#
Der erste internationale Leitfaden zur Erfassung von Abfallobjekten am Strand wurde 2008 vom Umweltprogramm der Vereinten Nationen (UNEP) und der Zwischenstaatlichen Ozeanographischen Kommission (IOC) veröffentlicht [eall09]. Auf der Grundlage der gesammelten Arbeit vieler Forschenden wurde diese Methode 2010 von der OSPAR-Kommission übernommen [OSP17], 2013 veröffentlichte die EU einen Leitfaden für die Überwachung mariner Abfallobjekte an den europäischen Meeren (the guide) [Han13]. Die Schweiz ist Mitglied von OSPAR und hat über 1000 Proben nach den im the guide beschriebenen Methoden genommen.
Auf the guide folgte 2016 Riverine Litter Monitoring - Options and Recommendations [HGFT+17], der die zunehmende Erkenntnis widerspiegelt, dass Flüsse wichtige Quellen für Haushaltsabfälle in Küstenregionen sind. Zu diesem Zeitpunkt war das erste Projekt zur Überwachung von Abfallobjekten am Genfer See bereits abgeschlossen und die Vorbereitungen für ein einjähriges nationales Projekt in der Schweiz, das von STOPPP initiiert und von WWF-Freiwilligen unterstützt wurde, liefen an, siehe Vergleich der Datenerhebungen seit 2018.
2019 veröffentlichte das Joint Research Centre (JRC) eine Analyse eines europäischen Datensatzes zu Abfallobjekten am Strand aus den Jahren 2012–2016, ein technisches Dokument, in dem die Methoden und verschiedenen Szenarien zur Berechnung von Basiswerten von Abfallobjekten am Strand detailliert beschrieben werden. Von besonderem Interesse für das JRC war die Robustheit der Methoden gegenüber Extremwerten und die Transparenz der Berechnungsmethode.[HG19]
Im September 2020 schliesslich legte die EU Basis- und Zielwerte auf der Grundlage der 2015–2016 erhobenen Daten fest. Die Zielwerte beziehen sich auf den guten Umweltzustand der Meeresgewässer, der in der Meeresstrategie-Rahmenrichtlinie (MSRL) beschrieben wird. Die Basiswerte wurden anhand der in der Veröffentlichung von 2019 beschriebenen Methoden berechnet.[VLW20]

Abb. 14.1 #
Abbildung 14.1: Zählen von Abfallobjekten am 18.05.2020 am Zürichsee, Richterswil; 3,49 Objekte pro Meter
14.1.1. Schweiz 2020#
Das IQAASL-Projekt begann im März 2020. Erhebungsorte in den definierten Erhebungsgebieten wurden 2017 beprobt oder neu eingerichtet. Ähnlich wie die Erhebungsergebnisse in der Meeresumwelt sind die Daten über Ufer-Abfallobjekte in der Schweiz sehr unterschiedlich. Die Werte reichen von Null bis zu Tausenden von Objekten und Fragmenten innerhalb von 100 m Distanz entlang von Fluss- oder Seeufer.
14.1.2. Das Sammeln von Daten#
The guide ist die Referenz für dieses Projekt. Die Geographie der Schweiz besteht jedoch nicht aus langen, homogenen Küstenabschnitten. Daher müssen bestimmte Empfehlungen in den Kontext der lokalen Topographie gestellt werden:
Die empfohlene Länge bleibt bei 100 m, je nach Region ist dies jedoch nicht immer möglich.
14.1.2.1. Festlegung des Erhebungsgebiets#
Ein Vermessungsgebiet wird durch den GPS-Punkt und die aufgezeichneten Vermessungsmasse definiert. Die Mindestbreite ist der Abstand zwischen der Wasserkante und der Uferlinie. In einigen Fällen können die Uferlinie und der hintere Teil des Ufers identisch sein. Für weitere Informationen darüber, wie die Vermessungsflächen gemessen werden, siehe Das Landnutzungsprofil.

Abb. 14.2 #
Abbildung 14.2: Die Datenerhebungen finden in der Stadt, auf dem Land und in der Agglomeration statt.
Die Länge und Breite des Erhebungsgebiets wird bei jeder Datenerhebung gemessen. So kann die Anzahl der Objekte in einer Standardeinheit unabhängig von den Erhebungsorten angegeben werden. In diesem Bericht wird die von der EU empfohlene Standard-Berichtseinheit verwendet: Abfallobjekte pro 100 Meter.
14.1.2.2. Zählen von Objekten#
Alle sichtbaren Objekte innerhalb eines Untersuchungsgebiets werden gesammelt, klassifiziert und gezählt. Das Gesamtgewicht von Material und Plastik wird ebenfalls erfasst. Die Objekte werden anhand von Code-Definitionen klassifiziert, die auf einer Masterliste von Codes in the guide basieren. Spezielle Objekte, die von lokalem Interesse sind, wurden unter G9xx und G7xx hinzugefügt.

Abb. 14.3 #
Abbildung 14.3: Zählen und Klassifizieren einer Probe. Die Objekte werden nach dem Sammeln sortiert und gezählt. Die ursprüngliche Zählung wird in einem Notizbuch festgehalten, und die Daten werden in die Anwendung plages-propres eingegeben, wenn der Erheber es wünscht.
14.2. Berechnung der Basislinien#
Die in den Abschnitten 3 und 4 von A European Threshold Value and Assessment Method for Macro litter on Coastlines und den Abschnitten 6, 7 und 8 von Analysis of a pan-European 2012-2016 beach litter data set beschriebenen Methoden werden auf die Ergebnisse der vorliegenden Untersuchung angewendet.
Die verschiedenen Optionen für die Berechnung von Basislinien, die Bestimmung von Konfidenzintervallen und die Identifizierung von Extremwerten werden erläutert und mit Beispielen versehen.
Annahmen:
Je mehr Abfallobjekte auf dem Boden liegen, desto grösser ist die Wahrscheinlichkeit, dass eine Person sie findet.
Die Erhebungsergebnisse stellen die Mindestmenge an Abfallobjekten an diesem Ort dar.
Für jede Datenerhebung: Das Auffinden eines Objekts hat keinen Einfluss auf die Wahrscheinlichkeit, ein weiteres zu finden.
14.2.1. Die Daten#
Nur Datenerhebungen mit einer Länge von mehr als zehn Metern und weniger als 100 Metern werden in die Berechnung der Basislinie einbezogen. Die folgenden Objekte wurden ausgeschlossen:
Objekte kleiner als 2,5 cm
Paraffin, Wachs, Öl und andere Chemikalien
Show code cell source
# define the final survey data set here:
a_data = survey_data.copy()
a_data = a_data[a_data.river_bassin != 'les-alpes']
# make a loc_date column from the survey data
# before converting to timestamp
a_data['loc_date']=tuple(zip(a_data.location, a_data.date))
# convert string dates from .csv to timestamp
a_data['date']=pd.to_datetime(a_data['date'], format='%Y-%m-%d')
# slice by start - end date
a_data = a_data[(a_data.date >= start_date)&(a_data.date <= end_date)]
# combine lugano and maggiore
# if the river bassin name does not equal tresa leave it, else change it to ticino
a_data['river_bassin'] = a_data.river_bassin.where(a_data.river_bassin != 'tresa', 'ticino' )
# assign the reporting value
a_data[unit_label] = (a_data.pcs_m * reporting_unit).round(2)
# save the data before aggregating to test
before_agg = a_data.copy()
# !! Remove the objects less than 2.5cm and chemicals !!
codes_todrop = ['G81', 'G78', 'G212', 'G213', 'G214']
a_data = a_data[~a_data.code.isin(codes_todrop)]
# use the code groups to get rid of all objects less than 5mm
a_data = a_data[a_data.groupname != 'micro plastics (< 5mm)']
# match records to survey data
fd_dims= dfDims[(dfDims.location.isin(a_data.location.unique()))&(dfDims.date >= start_date)&(dfDims.date <= end_date)].copy()
# make a loc_date column and get the unique values
fd_dims['loc_date'] = list(zip(fd_dims.location, fd_dims.date))
# map the survey area name to the dims data record
a_map = fd_dims[['loc_date', 'area']].set_index('loc_date')
l_map = fd_dims[['loc_date', 'length']].set_index('loc_date')
# map length and area from dims to survey data
for a_survey in fd_dims.loc_date.unique():
a_data.loc[a_data.loc_date == a_survey, 'length'] = l_map.loc[[a_survey], 'length'][0]
a_data.loc[a_data.loc_date == a_survey, 'area'] = a_map.loc[[a_survey], 'area'][0]
# exclude surveys less 10 meters or less
gten_lhun = a_data.loc[(a_data.length > 10)].copy()
# this is a common aggregation
agg_pcs_quantity = {unit_label:'sum', 'quantity':'sum'}
# survey totals by location
dt_all = gten_lhun.groupby(['loc_date','location','river_bassin', 'water_name_slug','date'], as_index=False).agg(agg_pcs_quantity)
# palettes and labels
bassin_pallette = {'rhone':'dimgray', 'aare':'salmon', 'linth':'tan', 'ticino':'steelblue', 'reuss':'purple'}
comp_labels = {"linth":"Linth/Limmat", "rhone":"Rhône", 'aare':"Aare", "ticino":"Ticino/Cerisio", "reuss":"Reuss"}
comp_palette = {"Linth/Limmat":"dimgray", "Rhône":"tan", "Aare":"salmon", "Ticino/Cerisio":"steelblue", "Reuss":"purple"}
# months locator, can be confusing
# https://matplotlib.org/stable/api/dates_api.html
months = mdates.MonthLocator(interval=1)
months_fmt = mdates.DateFormatter('%b')
days = mdates.DayLocator(interval=7)
fig = plt.figure(figsize=(10,5))
gs = GridSpec(1,8)
ax = fig.add_subplot(gs[:,0:4])
axtwo = fig.add_subplot(gs[:, 4:])
# scale the chart as needed to accomodate for extreme values
scale_back = 98
# the results gets applied to the y_limit function in the chart
the_90th = np.percentile(dt_all[unit_label], scale_back)
# the survey totals
sns.scatterplot(data=dt_all, x='date', y=unit_label, hue='river_bassin', palette=bassin_pallette, alpha=1, ax=ax)
# set params on ax:
ax.set_ylim(0,the_90th )
ax.set_ylabel(unit_label, **ck.xlab_k14)
ax.set_xlabel("")
ax.xaxis.set_minor_locator(days)
ax.xaxis.set_major_formatter(months_fmt)
h,l = ax.get_legend_handles_labels()
ax.legend(h, l)
# axtwo
a_color = "dodgerblue"
# get the basic statistics from pd.describe
cs = dt_all[unit_label].describe().round(2)
# change the names
csx = sut.change_series_index_labels(cs, featuredata.createSummaryTableIndex(unit_label, language="de"))
# combined_summary = csx.apply(lambda x: featuredata.thousandsSeparator(int(x)))
# csx.loc["max p/100 m "] = featuredata.thousandsSeparator(csx.loc["max p/100 m"])
combined_summary = [(x, featuredata.thousandsSeparator(int(csx.loc[x]))) for x in csx.index]
sut.hide_spines_ticks_grids(axtwo)
a_table = sut.make_a_table(axtwo, combined_summary, colLabels=["Stat", unit_label], colWidths=[.6,.4], bbox=[0, 0, 1, 1])
a_table.get_celld()[(0,0)].get_text().set_text(" ")
axtwo.tick_params(which='both', axis='both', labelsize=14)
ax.tick_params(which='both', axis='both', labelsize=14)
ax.grid(visible=True, which='major', axis='y', linestyle='-', linewidth=1, c='black', alpha=.1, zorder=0)
plt.tight_layout()
figure_name = f"baseline_sample_totals"
sample_totals_file_name = f'{save_fig_prefix}{figure_name}.jpeg'
save_figure_kwargs.update({"fname":sample_totals_file_name})
plt.savefig(**save_figure_kwargs)
# figure caption
sample_total_notes = [
"Erhebungsergebnisse und zusammenfassende Statistiken: ",
"Proben grösser als 10m und ohne Objekte kleiner als 2,5cm und Chemikalien, n=372"
]
sample_total_notes = ''.join(sample_total_notes)
glue("baseline_sample_total_notes", sample_total_notes, display=False)
glue("baseline_sample_totals", fig, display=False)
plt.close()
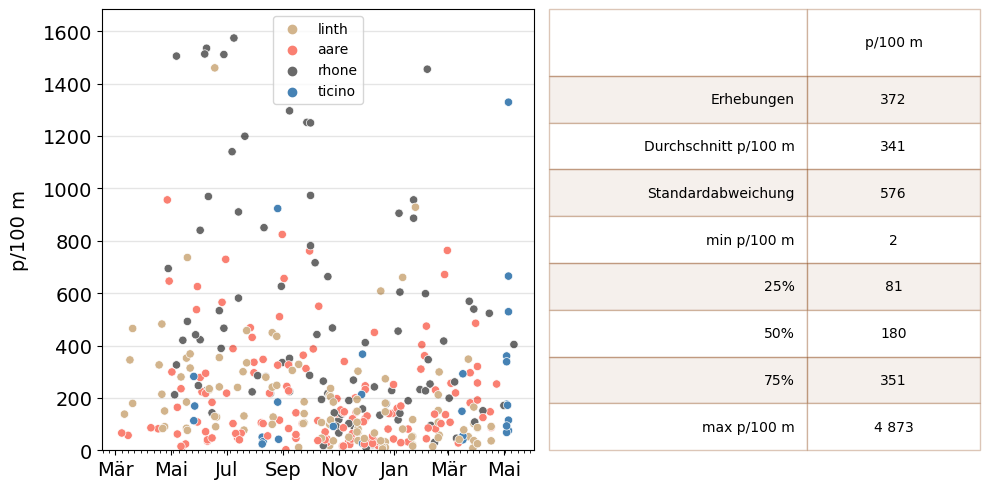
Abb. 14.4 #
Abbildung 14.4: Erhebungsergebnisse und zusammenfassende Statistiken: Proben grösser als 10m und ohne Objekte kleiner als 2,5cm und Chemikalien, n=372
Show code cell source
# percentile rankings 1, 5, 10, 15, 20
these_vals = []
for element in [.01,.05,.10,.15,.20, .5, .9 ]:
a_val = np.quantile(dt_all[unit_label].to_numpy(), element)
these_vals.append((F"{int(element*100)}.",F"{int(a_val)}"))
fig = plt.figure(figsize=(10,5))
gs = GridSpec(1,5)
ax = fig.add_subplot(gs[:,0:3])
axtwo = fig.add_subplot(gs[:, 3:])
ax.grid(visible=True, which='major', axis='y', linestyle='-', linewidth=1, c='black', alpha=.1, zorder=0)
sns.histplot(data=dt_all, x=unit_label, stat='count', ax=ax, alpha=0.6)
ax.axvline(x=dt_all[unit_label].median(), c='magenta', label='Median')
ax.axvline(x=dt_all[unit_label].mean(), c='red', label='Durchschnitt')
ax.legend()
sut.hide_spines_ticks_grids(axtwo)
table_two = sut.make_a_table(axtwo, these_vals, colLabels=('ranking', unit_label), colWidths=[.5,.5], bbox=[0, 0, 1, 1])
table_two.get_celld()[(0,0)].get_text().set_text("ranking")
table_two.set_fontsize(14)
axtwo.tick_params(which='both', axis='both', labelsize=14)
ax.tick_params(which='both', axis='both', labelsize=14)
figure_name = f"empirical_dist_rankings_baseline"
empirical_dist_file_name = f'{save_fig_prefix}{figure_name}.jpeg'
save_figure_kwargs.update({"fname":empirical_dist_file_name})
plt.savefig(**save_figure_kwargs)
# figure caption
empirical_dist_notes = [
"Verteilung der Datenerhebungen und Perzentilwerte: alle Erhebungen. Beachten Sie, dass der ",
"Mittelwert (341p/100m) grösser ist als der Median (180p/100m)."
]
empirical_dist_notes = ''.join(empirical_dist_notes)
glue("empirical_dist_rankings_baseline_notes", empirical_dist_notes, display=False)
glue("empirical_dist_rankings_baseline", fig, display=False)
plt.close()
Abb. 14.5 #
Abbildung 14.5: Verteilung der Datenerhebungen und Perzentilwerte: alle Erhebungen. Beachten Sie, dass der Mittelwert (341p/100m) grösser ist als der Median (180p/100m).
14.2.2. Die Bewertungsmetrik#
Die Berechnung von Basiswerten erfordert die Aggregation von Erhebungsergebnissen auf verschiedenen zeitlichen und geografischen Ebenen. Das ist die beste Methode:
Robust in Bezug auf Ausreisser
Einfach zu berechnen
Weithin verstanden
Die beiden gebräuchlichsten Teststatistiken, die zum Vergleich von Daten verwendet werden, sind der Mittelwert und der Median. Der Mittelwert ist der beste Prädiktor für die zentrale Tendenz, wenn die Daten ungefähr normal verteilt sind. Die Ergebnisse der Untersuchungen von Strand-Abfallaufkommen weisen jedoch eine hohe Varianz im Verhältnis zum Mittelwert auf. Es können Methoden auf die Daten angewendet werden, um die Auswirkungen der hohen Varianz bei der Berechnung des Mittelwerts zu verringern:
getrimmter Mittelwert: entfernt einen kleinen, festgelegten Prozentsatz der grössten und kleinsten Werte, bevor der Mittelwert berechnet wird
tri-Mittelwert: der gewichtete Durchschnitt des Medians und des oberen und unteren Quartils \((Q1 + 2Q2 + Q3)/4\)
mittleres Scharnier: \((Q1 + Q3)/2\)
Die bisherigen Methoden sind zwar wirksam, um die Auswirkungen von Ausreissern zu reduzieren, aber sie sind nicht so einfach zu berechnen wie der Mittelwert oder der Median, so dass die Signifikanz der Ergebnisse möglicherweise nicht richtig verstanden wird.
Der Median (50. Perzentil) ist ein ebenso guter Prädiktor für die zentrale Tendenz, wird aber im Vergleich zum Mittelwert viel weniger von Extremwerten beeinflusst. Je mehr sich ein Datensatz einer Normalverteilung nähert, desto näher kommen sich Median und Mittelwert. Der Median und die dazugehörigen Perzentil-Funktionen sind in den meisten Tabellenkalkulationsprogrammen verfügbar.
Aus den oben genannten Gründen wird der Medianwert einer Mindestanzahl von Proben, die während eines Probenahmezeitraums in einem Erhebungsgebiet gesammelt wurden, als statistisch geeignet für die Bewertung von Strand-Abfallobjekten angesehen. Für die Meeresumwelt beträgt die Mindestanzahl der Proben 40 pro Unterregion und der Probenahmezeitraum 6 Jahre. [HG19]
14.2.3. Konfidenzintervalle (KIs)#
Konfidenzintervalle (KIs) helfen dabei, die Unsicherheit der Ergebnisse von Strand-Abfallobjekten im Hinblick auf allgemeine Schlussfolgerungen über die Häufigkeit von Strand-Abfallobjekten in einer Region zu vermitteln. Das KI gibt den unteren und oberen Bereich der Schätzung der Teststatistik angesichts der Stichprobendaten an.
Der beste Weg, die Unsicherheit zu verringern, ist eine angemessene Anzahl von Proben für die Region oder das Gebiet von Interesse zu erheben. Strand-Abfallerhebungen weisen jedoch eine hohe Varianz auf und jede Schätzung eines Gesamtwerts sollte diese Varianz oder Unsicherheit widerspiegeln. kIs geben einen wahrscheinlichen Wertebereich angesichts der Unsicherheit/Varianz der Daten an.[HG19]
Bei dieser Methode werden die Daten NICHT von den Basisberechnungen und Konfidenzintervallen ausgeschlossen.
Man einigte sich darauf, die extremen Ergebnisse im Datensatz zu belassen, gleichzeitig aber die Notwendigkeit zu betonen, extreme Daten von Fall zu Fall zu überprüfen und den Median für die Berechnung von Durchschnittswerten zu verwenden. Auf diese Weise können alle Daten verwendet werden, ohne dass die Ergebnisse durch einzelne aussergewöhnlich hohe Abfallaufkommen verzerrt werden. [VLW20]
14.2.3.1. Bootstrap-Methoden:#
Bootstrapping ist eine Methode zur Wiederholung von Stichproben, bei der Zufallsstichproben mit Ersetzung verwendet werden, um den Stichprobenprozess zu wiederholen oder zu simulieren. Bootstrapping ermöglicht die Schätzung der Stichprobenverteilung von Stichprobenstatistiken unter Verwendung von Zufallsstichprobenverfahren. [Wika] [JLGC19] [Sta21b]
Bootstrap-Methoden werden verwendet, um das KI der Teststatistiken zu berechnen, indem der Stichprobenprozess wiederholt wird und der Median bei jeder Wiederholung ausgewertet wird. Der Wertebereich, der durch die mittleren 95 % der Bootstrap-Ergebnisse beschrieben wird, ist das KI für die beobachtete Teststatistik.
Es stehen mehrere Berechnungsmethoden zur Auswahl, z. B. Perzentil, BCa und Student’s t. Für dieses Beispiel wurden zwei Methoden getestet:
Perzentil-Bootstrap
Bias-korrigiertes beschleunigtes Bootstrap-Konfidenzintervall (BCa)
Die Perzentil-Methode berücksichtigt nicht die Form der zugrundeliegenden Verteilung, was zu Konfidenzintervallen führen kann, die nicht mit den Daten übereinstimmen. Die Bca-Methode korrigiert dies. Die Implementierung dieser Methoden ist mit den bereits zitierten Paketen einfach zu bewerkstelligen. [Efr87] [dry20] [Boi19]
14.2.4. Vergleich der Bootstrap-KIs#
Show code cell source
# this code was modified from this source:
# http://bebi103.caltech.edu.s3-website-us-east-1.amazonaws.com/2019a/content/recitations/bootstrapping.html
# if you want to get the confidence interval around another point estimate use np.percentile
# and add the percentile value as a parameter
def draw_bs_sample(data):
"""Draw a bootstrap sample from a 1D data set."""
return np.random.choice(data, size=len(data))
def compute_jackknife_reps(data, statfunction=None, stat_param=False):
'''Returns jackknife resampled replicates for the given data and statistical function'''
# Set up empty array to store jackknife replicates
jack_reps = np.empty(len(data))
# For each observation in the dataset, compute the statistical function on the sample
# with that observation removed
for i in range(len(data)):
jack_sample = np.delete(data, i)
if not stat_param:
jack_reps[i] = statfunction(jack_sample)
else:
jack_reps[i] = statfunction(jack_sample, stat_param)
return jack_reps
def compute_a(jack_reps):
'''Returns the acceleration constant a'''
mean = np.mean(jack_reps)
try:
a = sum([(x**-(i+1)- (mean**-(i+1)))**3 for i,x in enumerate(jack_reps)])
b = sum([(x**-(i+1)-mean-(i+1))**2 for i,x in enumerate(jack_reps)])
c = 6*(b**(3/2))
data = a/c
except:
print(mean)
return data
def bootstrap_replicates(data, n_reps=1000, statfunction=None, stat_param=False):
'''Computes n_reps number of bootstrap replicates for given data and statistical function'''
boot_reps = np.empty(n_reps)
for i in range(n_reps):
if not stat_param:
boot_reps[i] = statfunction(draw_bs_sample(data))
else:
boot_reps[i] = statfunction(draw_bs_sample(data), stat_param)
return boot_reps
def compute_z0(data, boot_reps, statfunction=None, stat_param=False):
'''Computes z0 for given data and statistical function'''
if not stat_param:
s = statfunction(data)
else:
s = statfunction(data, stat_param)
return stats.norm.ppf(np.sum(boot_reps < s) / len(boot_reps))
def compute_bca_ci(data, alpha_level, n_reps=1000, statfunction=None, stat_param=False):
'''Returns BCa confidence interval for given data at given alpha level'''
# Compute bootstrap and jackknife replicates
boot_reps = bootstrap_replicates(data, n_reps, statfunction=statfunction, stat_param=stat_param)
jack_reps = compute_jackknife_reps(data, statfunction=statfunction, stat_param=stat_param)
# Compute a and z0
a = compute_a(jack_reps)
z0 = compute_z0(data, boot_reps, statfunction=statfunction, stat_param=stat_param)
# Compute confidence interval indices
alphas = np.array([alpha_level/2., 1-alpha_level/2.])
zs = z0 + stats.norm.ppf(alphas).reshape(alphas.shape+(1,)*z0.ndim)
avals = stats.norm.cdf(z0 + zs/(1-a*zs))
ints = np.round((len(boot_reps)-1)*avals)
ints = np.nan_to_num(ints).astype('int')
# Compute confidence interval
boot_reps = np.sort(boot_reps)
ci_low = boot_reps[ints[0]]
ci_high = boot_reps[ints[1]]
return (ci_low, ci_high)
quantiles = [.1, .2, .5, .9]
q_vals = {x:dt_all[unit_label].quantile(x) for x in quantiles}
the_bcas = {}
for a_rank in quantiles:
an_int = int(a_rank*100)
a_result = compute_bca_ci(dt_all[unit_label].to_numpy(), .05, n_reps=5000, statfunction=np.percentile, stat_param=an_int)
observed = np.percentile(dt_all[unit_label].to_numpy(), an_int)
the_bcas.update({F"{int(a_rank*100)}":{'2.5% ci':a_result[0], "Beobachtung": observed, '97.5% ci': a_result[1]}})
bca_cis = pd.DataFrame(the_bcas)
bca_cis[['10', '20', '50', '90']] = bca_cis[['10', '20', '50', '90']].astype('int')
bca_cis['b-method'] = 'BCa'
bca_d = bca_cis.copy()
bca_d.rename(columns={"b-method":"Methode"}, inplace=True)
styled_table_bca = bca_d.style.set_table_styles(table_css_styles)
bcas = bca_cis.reset_index()
# bcas[['10', '20', '50', '90']] = bcas[['10', '20', '50', '90']].astype('int')
# bcas['b-method'] = 'BCa'
# bootstrap percentile confidence intervals
# resample the survey totals for n times to help
# define the range of the sampling statistic
# the number of reps
n=5000
# keep the observed values
observed_median = dt_all[unit_label].median()
observed_tenth = dt_all[unit_label].quantile(.15)
the_cis = {}
for a_rank in quantiles:
# for the median
sim_ptile = []
# for the tenth percentile
sim_ten = []
for element in np.arange(n):
less = dt_all[unit_label].sample(n=len(dt_all), replace=True)
a_ptile = less.quantile(a_rank)
sim_ptile.append(a_ptile)
# get the upper and lower range of the test statistic disrtribution:
a_min = np.percentile(sim_ptile, 2.5)
a_max = np.percentile(sim_ptile, 97.5)
# add the observed value and update the dict
the_cis.update({F"{int(a_rank*100)}":{'2.5% ci':a_min, "Beobachtung": q_vals[a_rank], '97.5% ci': a_max}})
# make df
p_cis = pd.DataFrame(the_cis)
p_cis = p_cis.astype("int")
p_cis['b-method'] = '%'
p_cd = p_cis.copy()
p_cd.rename(columns={"b-method":"Methode"}, inplace=True)
styled_table = p_cd.style.set_table_styles(table_css_styles)
p_cis.reset_index(inplace=True)
fig, axs = plt.subplots(figsize=(6,4))
axone = axs
data = p_cis.values
sut.hide_spines_ticks_grids(axone)
colLabels = [F"{x}." for x in p_cis.columns[:-1]]
colLabels.append('Methode')
table_one = sut.make_a_table(axone, data, colLabels=colLabels, colWidths=[.25,*[.15]*5], bbox=[0, 0, 1, 1])
table_one.set_fontsize(12)
table_one.get_celld()[(0,0)].get_text().set_text("Perzentile")
plt.tight_layout()
figure_name = f"ci_percentile_bootstrap"
ci_percentile_bootstrap_file_name = f'{save_fig_prefix}{figure_name}.jpeg'
save_figure_kwargs.update({"fname":ci_percentile_bootstrap_file_name})
plt.savefig(**save_figure_kwargs)
# figure caption
ci_percentile_bootstrap_notes = [
"Konfidenzintervalle, die durch eine 5.000-fache Wiederholungsstichprobe der ",
"Umfrageergebnisse für jede Bedingung berechnet wurden"
]
ci_percentile_bootstrap_notes = ''.join(ci_percentile_bootstrap_notes)
glue("ci_percentile_bootstrap_notes", ci_percentile_bootstrap_notes, display=False)
glue("ci_percentile_bootstrap", styled_table, display=False)
plt.close()
| 10 | 20 | 50 | 90 | Methode | |
|---|---|---|---|---|---|
| 2.5% ci | 29 | 48 | 147 | 598 | % |
| Beobachtung | 36 | 64 | 180 | 727 | % |
| 97.5% ci | 43 | 81 | 213 | 909 | % |
Abb. 14.6 #
Abbildung 14.6: Konfidenzintervalle, die durch eine 5.000-fache Wiederholungsstichprobe der Umfrageergebnisse für jede Bedingung berechnet wurden
Show code cell source
fig, axs = plt.subplots(figsize=(6,4))
axtwo = axs
# styled_table = bcas.style.set_table_styles(table_css_styles)
# data = p_cis.values
sut.hide_spines_ticks_grids(axtwo)
colLabels = [F"{x}." for x in p_cis.columns[:-1]]
colLabels.append('Methode')
table_two = sut.make_a_table(axtwo, bcas.values, colLabels=colLabels, colWidths=[.25,*[.15]*5], bbox=[0, 0, 1, 1])
table_two.set_fontsize(12)
table_two.get_celld()[(0,0)].get_text().set_text("BCa")
plt.tight_layout()
figure_name = f"bca_bootstrap"
bca_bootstrap_file_name = f'{save_fig_prefix}{figure_name}.jpeg'
save_figure_kwargs.update({"fname":bca_bootstrap_file_name})
plt.savefig(**save_figure_kwargs)
# figure caption
bca_bootstrap_notes = [
"Die gleichen Intervalle unter Verwendung der verzerrungskorrigierten Methode."
]
bca_bootstrap_notes = ''.join(bca_bootstrap_notes)
glue("bca_bootstrap_notes", bca_bootstrap_notes, display=False)
glue("bca_bootstrap", styled_table_bca, display=False)
plt.close()
| 10 | 20 | 50 | 90 | Methode | |
|---|---|---|---|---|---|
| 2.5% ci | 28 | 48 | 147 | 596 | BCa |
| Beobachtung | 36 | 64 | 180 | 727 | BCa |
| 97.5% ci | 42 | 78 | 213 | 909 | BCa |
Abb. 14.7 #
Abbildung 14.7: Die gleichen Intervalle unter Verwendung der verzerrungskorrigierten Methode.

Abb. 14.8 #
Abbildung 14.8: Beispiel für das Konfidenzintervall: Das Ergebnis der Datenerhebungen in Biel am 31.01.2021 war grösser als der Medianwert für alle Datenerhebungen. Es wurden 123 Objekte (p) über 40 Meter (m) Uferlinie gesammelt. Zunächst wird der Wert der Datenerhebungen in Abfallobjekte pro Meter (p/m) umgerechnet und dann mit der erforderlichen Anzahl von Metern (100) multipliziert: \((pcs/m)*100 = (123_{pcs} / 40_m)*100 m \approxeq \text{313 p/100 m}\)
14.2.5. Basiswerte#
Für diesen Datensatz sind die Unterschiede zwischen den mit der Bca-Methode oder der Perzentilmethode berechneten KIs minimal. Die Bca-Methode wird verwendet, um die Basiswerte und KIs anzugeben.
14.2.5.1. Basismedianwert aller Erhebungsergebnisse#
Wenn man nur Datenerhebungen mit einer Länge von mehr als 10 Metern berücksichtigt und Objekte mit einer Grösse von weniger als 2,5 cm ausschliesst, lag der Medianwert aller Daten bei 181 p/100 m mit einem KI von 147 p/100 m – 213 p/100 m. Der gemeldete Medianwert für die EU lag bei 133 p/100 m und damit im Bereich des KI der IQAASL-Erhebungsergebnisse. Während der Medianwert in der Schweiz höher ist, liegt der Mittelwert der EU-Studie bei 504 p/100 m gegenüber 341 p/100 m in der Schweiz.[HG19]
Das deutet darauf hin, dass die höheren Extremwerte in der Meeresumwelt wahrscheinlicher waren, aber der erwartete Medianwert beider Datensätze ist ähnlich.
14.2.5.2. Median-Basislinie und KI pro Erhebungsgebiet#
In der vorliegenden Studie wurden in drei von vier Erhebungsgebieten mehr als 40 Erhebungen durchgeführt.
Show code cell source
bassins = ["linth", "aare", "rhone"]
the_sas = {}
for a_bassin in bassins:
an_int = int(a_rank*100)
a_result = compute_bca_ci(dt_all[dt_all.river_bassin == a_bassin][unit_label].to_numpy(), .05, n_reps=5000, statfunction=np.percentile, stat_param=50)
observed = np.percentile(dt_all[dt_all.river_bassin == a_bassin][unit_label].to_numpy(), 50)
the_sas.update({a_bassin:{'2.5% ci':a_result[0], "Beobachtung": observed, '97.5% ci': a_result[1]}})
sas = pd.DataFrame(the_sas)
new_colnames = {
"linth":"Linth",
"rhone": "Rhône",
"aare":"Aare",
"b-method": "Methode"
}
sas['b-method'] = 'bca'
sas.rename(columns=new_colnames, inplace=True)
sas["Linth"] = sas["Linth"].apply(lambda x: featuredata.thousandsSeparator(int(x)))
sas["Aare"] = sas["Aare"].apply(lambda x: featuredata.thousandsSeparator(int(x)))
sas["Rhône"] = sas["Rhône"].apply(lambda x: featuredata.thousandsSeparator(int(x)))
sas_d = sas.copy()
styled_table = sas.style.set_table_styles(table_css_styles)
sas = sas.reset_index()
fig, axs = plt.subplots(figsize=(7,4))
data = sas.values
sut.hide_spines_ticks_grids(axs)
table_one = sut.make_a_table(axs, data, colLabels=sas.columns, colWidths=[.25,*[.15]*5], bbox=[0, 0, 1, 1])
table_one.get_celld()[(0,0)].get_text().set_text(" ")
figure_name = "ci_survey_area"
ci_survey_area_file_name = f'{save_fig_prefix}{figure_name}.jpeg'
save_figure_kwargs.update({"fname":ci_survey_area_file_name})
plt.savefig(**save_figure_kwargs)
# figure caption
ci_survey_area_notes = [
"Der Median und das 95-Prozent-Konfidenzintervall der Erhebungsgebiete Linth, Aare ",
"und Rhône. Das Erhebungsgebiet Tessin ist mangels ausreichender Anzahl von Datenerhebungen ",
"nicht enthalten."
]
ci_survey_area_notes = ''.join(ci_survey_area_notes)
glue("ci_survey_area_notes", ci_survey_area_notes, display=False)
glue("ci_survey_area", styled_table, display=False)
plt.close()
| Linth | Aare | Rhône | Methode | |
|---|---|---|---|---|
| 2.5% ci | 99 | 102 | 264 | bca |
| Beobachtung | 127 | 140 | 396 | bca |
| 97.5% ci | 152 | 169 | 467 | bca |
Abb. 14.9 #
Abbildung 14.9: Der Median und das 95-Prozent-Konfidenzintervall der Erhebungsgebiete Linth, Aare und Rhône. Das Erhebungsgebiet Tessin ist mangels ausreichender Anzahl von Datenerhebungen nicht enthalten.
14.3. Extremwerte#
Wie bereits erwähnt, werden Extremwerte (EVs) oder Ausreisser bei der Berechnung von Basislinien oder CIs nicht aus den Daten ausgeschlossen. Die Identifizierung von EVs und wo und wann sie auftreten, ist jedoch ein wesentlicher Bestandteil des Überwachungsprozesses.
Das Auftreten von Extremwerten kann den Durchschnitt der Daten und die Interpretation der Erhebungsergebnisse beeinflussen. Laut dem GFS-Bericht:
Die Methodik zur Identifizierung von Extremwerten kann entweder auf einem Expertenurteil beruhen oder auf statistischen und modellierenden Ansätzen, wie der Anwendung von Tukey’s Box Plots zur Erkennung potenzieller Ausreisser. Für schiefe Verteilungen ist der angepasste Boxplot besser geeignet. [HG19]
14.3.1. Extremwerte definieren#
Die Referenzen geben keine Hinweise auf den numerischen Wert eines EV. Im Gegensatz zu dem Zielwert von 20 p/100 m oder dem 15. Perzentil bleibt die Definition eines EV der Person überlassen, die die Daten interpretiert. Die Obergrenze von Tukeys Boxplot (unangepasst) ist ungefähr das 90. Perzentil der Daten. Diese Methode ist mit der Bewertungsmetrik kompatibel, und Boxplots lassen sich visuell relativ leicht auflösen.
14.3.1.1. Angepasste Boxplots#
Tukeys Boxplot wird verwendet, um die Verteilung eines univariaten Datensatzes zu visualisieren. Die Proben, die innerhalb des ersten Quartils (25 %) und des dritten Quartils (75 %) liegen, werden als innerhalb des inneren Quartilsbereichs (IQR) betrachtet. Punkte, die ausserhalb des inneren Quartils liegen, werden als Ausreisser betrachtet, wenn ihr Wert grösser oder kleiner als einer der beiden Grenzwerte ist:
Untere Grenze = \(Q_1 - (1.5*IQR)\)
Obergrenze = \(Q_3 + (1.5*IQR)\)
Die Grenzen werden erweitert oder reduziert, um der Form der Daten besser zu entsprechen. Infolgedessen repräsentieren die oberen und unteren Grenzen einen grösseren Wertebereich in Bezug auf das Perzentil-Ranking als bei der unangepassten Version.[HV08] [SP]
Die neue Berechnung sieht wie folgt aus:
Untere Grenze = \(Q_1 - (1.5e^{-4MC}*IQR)\)
Obergrenze = \(Q_3 + (1.5e^{3MC}*IQR)\)
Die Grenzen werden erweitert oder reduziert, um der Form der Daten besser zu entsprechen. Infolgedessen repräsentieren die oberen und unteren Grenzen einen grösseren Wertebereich in Bezug auf das Perzentil-Ranking als bei der unangepassten Version.
Show code cell source
# implementation of medcouple
a_whis = medcouple(dt_all[unit_label].to_numpy())
# get the ecdf
ecdf = ECDF(dt_all[unit_label].to_numpy())
# quantiles and IQR of the data
q1 = dt_all[unit_label].quantile(0.25)
q3 =dt_all[unit_label].quantile(0.75)
iqr = q3 - q1
# the upper and lower limit of extreme values unadjusted:
limit_lower = q1 - 1.5*iqr
limit_upper = q3 + 1.5*iqr
# the upper and lower limit of extreme values adjusted:
a_fence = q1 - (1.5*(math.exp((-4*a_whis))))*iqr
a_2fence = q3 + (1.5*(math.exp((3*a_whis))))*iqr
fig, ax = plt.subplots(figsize=(4,6))
box_props = {
'boxprops':{'facecolor':'none', 'edgecolor':'magenta'},
'medianprops':{'color':'magenta'},
'whiskerprops':{'color':'magenta'},
'capprops':{'color':'magenta'}
}
sns.stripplot(data=dt_all, y=unit_label, ax=ax, zorder=1, color='black', jitter=.35, alpha=0.3, s=8)
sns.boxplot(data=dt_all, y=unit_label, ax=ax, zorder=3, orient='v', showfliers=False, **box_props)
ax.axhline(y=a_2fence, xmin=.25, xmax=.75, c='magenta', zorder=3,)
ax.set_ylabel(unit_label, **ck.xlab_k14)
ax.tick_params(which='both', axis='both', labelsize=14)
ax.tick_params(which='both', axis='x', bottom=False)
ax.set_ylim(0, a_2fence+200)
ax.annotate("bereinigt",
xy=(0, a_2fence), xycoords='data',
xytext=(.2,a_2fence-200), textcoords='data',
size=14, va="center", ha="center",
bbox=dict(boxstyle="round4", fc="w", alpha=0.5),
arrowprops=dict(arrowstyle="-|>",
connectionstyle="arc3,rad=-0.2",
fc="black"),)
ax.annotate("nicht bereinigt",
xy=(0, limit_upper), xycoords='data',
xytext=(-.2,limit_upper+400), textcoords='data',
size=14, va="center", ha="center",
bbox=dict(boxstyle="round4", fc="w",alpha=0.5),
arrowprops=dict(arrowstyle="-|>",
connectionstyle="arc3,rad=-0.2",
fc="black"),)
ax.grid(visible=True, which='major', axis='y', linestyle='-', linewidth=1, c='black', alpha=.1, zorder=0)
figure_name = "tukeys_example"
tukeys_example_file_name = f'{save_fig_prefix}{figure_name}.jpeg'
save_figure_kwargs.update({"fname":tukeys_example_file_name})
plt.savefig(**save_figure_kwargs)
# figure caption
tukeys_caption = [
"Die Grenze, ab der eine Datenerhebung als extrem gilt, erstreckt sich auf das 98. ",
"Perzentil, wenn die Boxplots angepasst werden, im Gegensatz zum 90. Perzentil, ",
"wenn die Konstante bei 1,5 belassen wird. ",
"Der Unterschied zwischen bereinigten und normalen Boxplots. Bereinigt = 1’507 p/100, m",
"nicht bereinigt = 755 p/100 m."
]
tukeys_example_notes = ''.join(tukeys_caption)
glue("tukeys_example_notes", tukeys_example_notes, display=False)
glue("tukeys_example", fig, display=False)
plt.close()
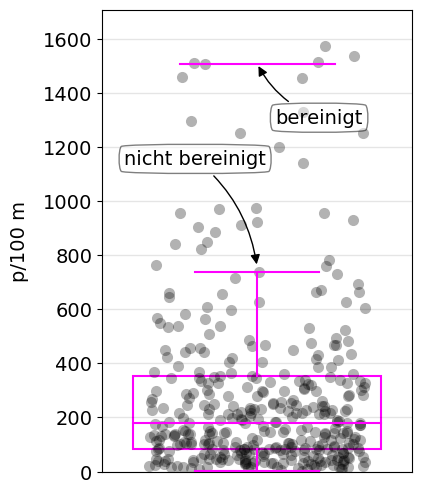
Abb. 14.10 #
Abbildung 14.10: Die Grenze, ab der eine Datenerhebung als extrem gilt, erstreckt sich auf das 98. Perzentil, wenn die Boxplots angepasst werden, im Gegensatz zum 90. Perzentil, wenn die Konstante bei 1,5 belassen wird. Der Unterschied zwischen bereinigten und normalen Boxplots. Bereinigt = 1’507 p/100, mnicht bereinigt = 755 p/100 m.
Der Unterschied zwischen bereinigten und normalen Boxplots. Bereinigt = 1507 p/100 m, nicht bereinigt = 755 p/100 m.
Bei Verwendung der bereinigten Boxplots steigt die Extremwertschwelle (EVT) auf über 1600 p/100 m. Die unbereinigten Boxplots liegen jedoch innerhalb des KI des erwarteten Perzentils der Erhebungsdaten.

Abb. 14.11 #
Abbildung 14.11: Beispiel für bereinigte Extremwerte: St. Gingolph, 12.08.2020. Es wurden 514 Objekte (p) über 31 Meter (m) Uferlinie gesammelt. Zuerst wird der Wert der Datenerhebungen in Abfallobjekte pro Meter (p/m) umgerechnet und dann mit der erforderlichen Anzahl von Metern (100) multipliziert: \((pcs/m)*100 = (514_{pcs} / 31_m)*100m \approxeq \text{1'652 p/100 m}\)
14.3.1.2. Modellierung#
Extremwerte können identifiziert werden, indem man davon ausgeht, dass die Daten zu einer zugrundeliegenden bekannten statistischen Verteilung gehören. Im Allgemeinen wird davon ausgegangen, dass Zähldaten eine Poisson-Verteilung oder eine sehr ähnliche Form aufweisen. Bei der Poisson-Verteilung wird angenommen, dass der Mittelwert gleich der Varianz ist. Die vorliegenden Daten und Strandabfalldaten im Allgemeinen weisen eine hohe Varianz auf, die in der Regel grösser als der Mittelwert ist.
Für die negative Binomialverteilung (NB) gilt diese Anforderung nicht. Die NB ist eine Poisson-Verteilung mit dem Parameter λ, wobei λ selbst nicht fest ist, sondern eine Zufallsvariable, die einer Gamma-Verteilung folgt. [CT99] [Wei20] [nbi]
Der Modellierungsansatz zur Identifizierung von Extremwerten erfolgt dann durch Anpassung der NB-Verteilung an die Daten mittels maximaler Wahrscheinlichkeit (MLE) und Kennzeichnung aller Werte im rechten Schwanz als potenziell extreme Werte, wenn die Wahrscheinlichkeit, dass sie zur angepassten NB-Verteilung gehören, kleiner als z.B. 0,001 ist. [VLW20]
Der MLE ist eine der beiden empfohlenen Methoden zur Modellierung oder Anpassung von Datenwerten an eine angenommene Verteilung:
Methode der Momente (MOM)
MLE: Maximum-Likelihood-Schätzung
14.3.1.2.1. Methode der Momente (MOM)#
Die Methode der Momente geht davon aus, dass die aus der Stichprobe abgeleiteten Parameter den Populationsparametern nahekommen oder gleich sind. Im Falle von Strand-Abfallerhebungen bedeutet dies, dass der Median, der Mittelwert und die Varianz der Stichprobe als gute Annäherung an die tatsächlichen Werte angesehen werden können, wenn alle Strände an allen Seen und Fliessgewässern untersucht werden.
Konkret werden die Parameter eines wahrscheinlichen Verteilungsmodells geschätzt, indem sie aus den Beispieldaten berechnet werden. Diese Methode ist einfach anzuwenden, da die meisten Parameterberechnungen für die gängigsten Verteilungen gut bekannt sind. [MDG18] [VGO+20] [SO]
14.3.1.2.2. Maximum-Likelihood-Schätzung (MLE)#
MLE ist eine Methode zur Schätzung der Parameter eines statistischen Modells bei gegebenen Daten. In dieser Hinsicht unterscheidet sie sich nicht von der MOM. Der Unterschied besteht darin, dass bei der MOM die Modellparameter aus den Daten berechnet werden, während bei der MLE die Parameter so gewählt werden, dass die Daten angesichts des statistischen Modells am wahrscheinlichsten sind.
Diese Methode ist rechenintensiver als die MOM, hat aber einige Vorteile:
Wenn das Modell korrekt angenommen wird, ist MLE die effizienteste Schätzung.
MLE führt zu unverzerrten Schätzungen in grösseren Stichproben.
Show code cell source
# implementaion of MLE
# https://github.com/pnxenopoulos/negative_binomial/blob/master/negative_binomial/core.py
def r_derv(r_var, vec):
''' Function that represents the derivative of the negbinomial likelihood
'''
total_sum = 0
obs_mean = np.mean(vec) # Save the mean of the data
n_pop = float(len(vec)) # Save the length of the vector, n_pop
for obs in vec:
total_sum += digamma(obs + r_var)
total_sum -= n_pop*digamma(r_var)
total_sum += n_pop*math.log(r_var / (r_var + obs_mean))
return total_sum
def p_equa(r_var, vec):
''' Function that represents the equation for p in the negbin likelihood
'''
data_sum = sum(vec)
n_pop = float(len(vec))
p_var = 1 - (data_sum / (n_pop * r_var + data_sum))
return p_var
def neg_bin_fit(vec, init=0.0001):
''' Function to fit negative binomial to data
vec: the data vector used to fit the negative binomial distribution
'''
est_r = newton(r_derv, init, args=(vec,))
est_p = p_equa(est_r, vec)
return est_r, est_p
# the data to model
vals = dt_all[unit_label].to_numpy()
# the variance
var = np.var(vals)
# the average
mean = np.mean(vals)
# dispersion
p = (mean/var)
n = (mean**2/(var-mean))
# implementation of method of moments
r = stats.nbinom.rvs(n,p, size=len(vals))
# format data for charting
df = pd.DataFrame({unit_label:vals, 'group':"Beobachtung"})
df = pd.concat([df, pd.DataFrame({unit_label:r, 'group':'MOM'})])
scp = df[df.group == 'MOM'][unit_label].to_numpy()
obs = df[df.group == "Beobachtung"][unit_label].to_numpy()
scpsx = [{unit_label:x, 'model':'MOM'} for x in scp]
obsx = [{unit_label:x, 'model':"Beobachtung"} for x in obs]
# ! implementation of MLE
estimated_r, estimated_p = neg_bin_fit(obs, init = 0.0001)
# ! use the MLE estimators to generate data
som_data = stats.nbinom.rvs(estimated_r, estimated_p, size=len(dt_all))
som_datax = pd.DataFrame([{unit_label:x, 'model':'MLE'} for x in som_data])
# combined the different results in to one df
data = pd.concat([pd.DataFrame(scpsx), pd.DataFrame(obsx), pd.DataFrame(som_datax)])
data.reset_index(inplace=True)
# the 90th
ev = data.groupby('model', as_index=False)[unit_label].quantile(.9)
xval={'MOM':0, 'Beobachtung':1, 'MLE':2}
ev['x'] = ev.model.map(lambda x: xval[x])
box_palette = {'MOM':'salmon', 'MLE':'magenta', 'Beobachtung':'dodgerblue'}
fig, axs = plt.subplots(1,2, figsize=(10,6))
ax=axs[0]
axone=axs[1]
bw=80
sns.histplot(data=data, x=unit_label, ax=ax, hue='model', zorder=2, palette=box_palette, binwidth=bw, element='bars', multiple='stack', alpha=0.4)
# sns.histplot(data=data, x=unit_label, ax=ax, hue='model')
box_props = {
'boxprops':{'facecolor':'none', 'edgecolor':'black'},
'medianprops':{'color':'black'},
'whiskerprops':{'color':'black'},
'capprops':{'color':'black'}
}
sns.boxplot(data=data, x='model', y=unit_label, ax=axone, zorder=5, palette=box_palette, showfliers=False, dodge=False, **box_props)
sns.stripplot(data=data, x='model', y=unit_label, hue='model', zorder=0,palette=box_palette, ax=axone, s=8, alpha=0.2, dodge=False, jitter=0.4)
axone.scatter(x=ev.x.values, y=ev[unit_label].values, label="90%", color='black', s=60)
axone.set_ylim(0,np.percentile(r, 95))
ax.get_legend().remove()
ax.set_ylabel("# der Erhebungen", **ck.xlab_k14)
axone.set_ylabel(unit_label, **ck.xlab_k14)
handles, labels = axone.get_legend_handles_labels()
axone.get_legend().remove()
h3=handles[:3]
hlast= handles[-1:]
axone.set_xlabel("")
axone.tick_params(which='both', axis='both', labelsize=14)
ax.tick_params(which='both', axis='both', labelsize=14)
l3 = labels[:3]
llast = labels[-1:]
ax.grid(visible=True, which='major', axis='y', linestyle='-', linewidth=1, c='black', alpha=.2, zorder=0)
axone.grid(visible=True, which='major', axis='y', linestyle='-', linewidth=1, c='black', alpha=.2, zorder=0)
fig.legend([*h3, *hlast], [*l3, *llast], bbox_to_anchor=(.48, .96), loc='upper right', fontsize=14)
plt.tight_layout()
figure_name = "models_compare"
models_compare_file_name = f'{save_fig_prefix}{figure_name}.jpeg'
save_figure_kwargs.update({"fname":models_compare_file_name})
plt.savefig(**save_figure_kwargs)
# figure caption
models_compare_caption = [
"<b>Anpassen der Daten an die zugrundeliegende NB-Verteilung.</b> Die beobachteten Erhebungsergebnisse werden ",
"mit den geschätzten Datenerhebungen unter Verwendung der Methode der Momente und der Maximum-Likelihood-Schätzung ",
"verglichen. <b>Links:</b> Histogramm der Ergebnisse im Vergleich zu den beobachteten Daten. <b>Rechts:</b> Verteilung ",
"der Ergebnisse im Vergleich zu den beobachteten Daten mit 90. Perzentil. 90% p/100m: MLE=825, Observed=727, MOM=888"
]
models_compare_notes = ''.join(models_compare_caption)
glue("models_compare", fig, display=False)
plt.close()
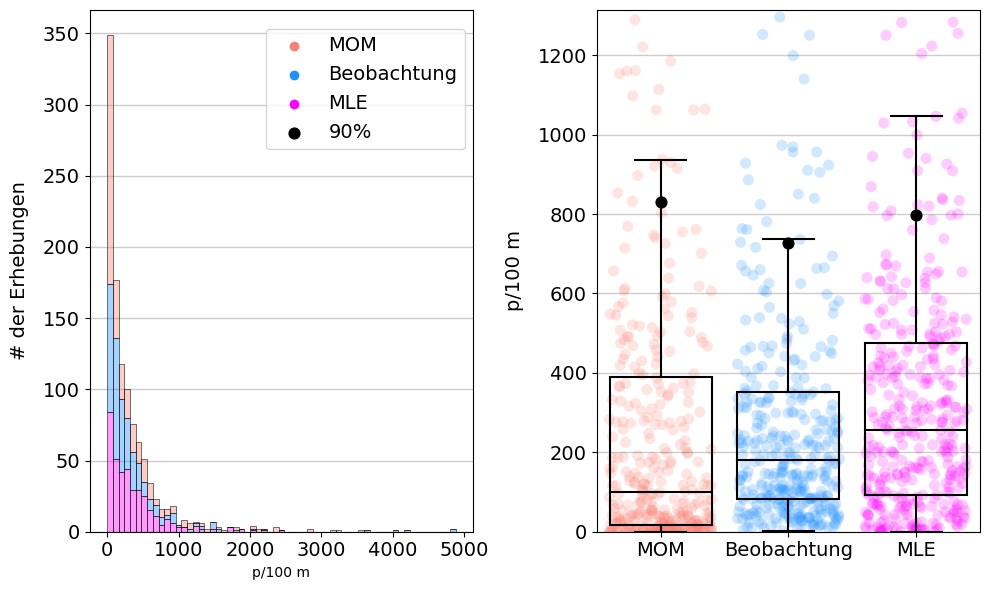
Abb. 14.12 #
Abbildung 14.12: Anpassen der Daten an die zugrundeliegende NB-Verteilung. Die beobachteten Erhebungsergebnisse werden mit den geschätzten Datenerhebungen unter Verwendung der Methode der Momente und der Maximum-Likelihood-Schätzung verglichen. Links: Histogramm der Ergebnisse im Vergleich zu den beobachteten Daten. Rechts: Verteilung der Ergebnisse im Vergleich zu den beobachteten Daten mit 90. Perzentil.
14.4. Umsetzung#
Die vorgeschlagenen Bewertungsmassstäbe und -methoden für die Ergebnisse der Untersuchungen der Strand-Abfallaufkommen sind ähnlich und kompatibel mit den zuvor in der Schweiz angewandten Methoden. Diese erste Analyse hat gezeigt:
dass die von der EU vorgeschlagenen Methoden zur Überwachung von Abfallobjekten in der Schweiz anwendbar sind,
dass Konfidenzintervalle und Basislinien für verschiedene Erhebungsgebiete berechnet werden können und
dass aggregierte Ergebnisse zwischen Regionen verglichen werden können.
Sobald der BV für ein Erhebungsgebiet berechnet ist, können alle Proben, die innerhalb dieses Erhebungsgebiets durchgeführt werden, direkt mit diesem verglichen werden. Es zeigt sich, dass die Erhebungsgebiete in der Schweiz unterschiedliche Median-Basislinien haben. Diese Situation ist mit der EU vergleichbar, was die Unterschiede zwischen den verschiedenen Regionen und Verwaltungsgebieten betrifft.
Durch die Anwendung der vorgeschlagenen Methoden auf die aktuellen Ergebnisse von IQAASL können die zu untersuchenden Objekte für jedes Untersuchungsgebiet identifiziert werden.
| Aare | Linth | Rhone | Ticino | Alle Erhebungsgebiete | |
|---|---|---|---|---|---|
| Getränkeflaschen aus Glas, Glasfragmente | 3,0 | 4,0 | 2,0 | 8,0 | 3,0 |
| Expandiertes Polystyrol | 4,0 | 3,0 | 17,5 | 6,0 | 5,0 |
| Fragmentierte Kunststoffe | 18,5 | 10,5 | 48,0 | 9,5 | 18,0 |
| Industriefolie (Kunststoff) | 5,0 | 2,0 | 9,0 | 3,5 | 5,0 |
| Industriepellets (Nurdles) | 0,0 | 0,0 | 0,0 | 0,0 | 0,0 |
| Kronkorken, Lasche von Dose/Ausfreisslachen | 0,0 | 1,0 | 3,0 | 1,0 | 1,0 |
| Kunststoff-Bauabfälle | 0,0 | 0,0 | 5,5 | 2,5 | 1,0 |
| Schaumstoffverpackungen/Isolierung | 0,0 | 0,0 | 7,0 | 3,0 | 1,0 |
| Snack-Verpackungen | 8,0 | 6,0 | 19,0 | 4,0 | 9,0 |
| Styropor < 5mm | 0,0 | 0,0 | 0,0 | 0,0 | 0,0 |
| Wattestäbchen/Tupfer | 0,0 | 0,0 | 10,5 | 0,0 | 1,0 |
| Zigarettenfilter | 11,0 | 23,0 | 41,5 | 15,5 | 20,0 |
Abb. 14.13 #
Abbildung 14.13: Vergleich der BVs der häufigsten Objekte. Alle Datenerhebungen 2020–2021. Das Erhebungsgebiet Ticino/Ceresio hat weniger als 100 Datenerhebungen.
Der erwartete Medianwert pro Datenerhebung und der Medianwert der häufigsten Objekte pro Erhebung ist im Erhebungsgebiet Rhône höher. Wenn der Medianwert verwendet wird, zeigt der BV auch, dass 2/12 der häufigsten Objekte in weniger als 50 % der Datenerhebungen landesweit gefunden wurden, nämlich diejenigen mit einem Medianwert von Null.
Die Methode kann vertikal skaliert werden, um eine detailliertere Ansicht eines Erhebungsgebiets zu erhalten. Die Berechnungsmethode bleibt dieselbe, daher sind Vergleiche vom See bis zur nationalen Ebene möglich.
| Aare | Nidau-Büren-Kanal | Bielersee | Brienzersee | Emme | La Thièle | Neuenburgersee | Schüss | Thunersee | Erhebungsgebiet Aare | Alle Erhebungsgebiete | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Getränkeflaschen aus Glas, Glasfragmente | 0,0 | 3,0 | 5,5 | 0,0 | 0,0 | 0,0 | 5,0 | 15,0 | 3,0 | 3,0 | 3,0 |
| Expandiertes Polystyrol | 0,0 | 0,0 | 5,5 | 15,0 | 0,0 | 10,0 | 3,0 | 0,0 | 10,0 | 4,0 | 5,0 |
| Fragmentierte Kunststoffe | 0,0 | 4,0 | 53,0 | 53,0 | 2,0 | 0,0 | 15,0 | 6,0 | 12,0 | 18,5 | 18,0 |
| Industriefolie (Kunststoff) | 0,0 | 0,0 | 18,0 | 47,0 | 22,0 | 5,0 | 2,0 | 0,0 | 5,0 | 5,0 | 5,0 |
| Industriepellets (Nurdles) | 0,0 | 0,0 | 2,5 | 2,0 | 0,0 | 0,0 | 0,0 | 0,0 | 0,0 | 0,0 | 0,0 |
| Schaumstoffverpackungen/Isolierung | 0,0 | 0,0 | 1,0 | 5,0 | 0,0 | 0,0 | 0,5 | 0,0 | 2,0 | 0,0 | 1,0 |
| Snack-Verpackungen | 2,0 | 1,0 | 21,0 | 27,0 | 2,0 | 5,0 | 7,0 | 8,5 | 4,0 | 8,0 | 9,0 |
| Styropor < 5mm | 0,0 | 0,0 | 0,0 | 0,0 | 0,0 | 16,0 | 0,0 | 0,0 | 0,0 | 0,0 | 0,0 |
| Verpackungen aus Aluminiumfolie | 0,0 | 0,0 | 2,5 | 0,0 | 2,0 | 0,0 | 1,0 | 2,0 | 0,0 | 1,0 | 0,0 |
| Verpackungsfolien, nicht für Lebensmittel | 0,0 | 0,0 | 9,5 | 0,0 | 11,0 | 0,0 | 1,0 | 3,0 | 0,0 | 0,5 | 0,0 |
| Zigarettenfilter | 2,0 | 28,0 | 9,0 | 6,0 | 7,0 | 5,0 | 17,0 | 27,0 | 16,0 | 11,0 | 20,0 |
Abb. 14.14 #
Abbildung 14.14: Vergleich der Basiswerte der häufigsten Objekte. Erhebungsgebiet Aare, Seen und Fliessgewässer 2020–2021. Orte mit mehr als 30 Datenerhebungen: Bielersee, Neuenburgersee und Thunersee.
Die empfohlene Mindestanzahl von Datenerhebungen (40) pro Probenahmezeitraum soll sicherstellen, dass die BV-Berechnungen auf einer ausreichenden Anzahl von Stichproben basieren. Dies ist wegen der hohen Variabilität der Untersuchungen der Strand-Abfallobjekte wichtig.
Die Probenahmen für IQAASL haben im Zeitraum von April 2020 bis Mai 2021 stattgefunden. Unter Berücksichtigung der Mindestanzahl der Proben gibt es drei Basiswerte für das Erhebungsgebiet Aare:
Bielersee
Neuenburgersee
Erhebungsgebiet Aare
Für Bewertungszwecke bedeutet dies, dass eine Stichprobe als Stichprobenbewertung dienen kann und die Ergebnisse direkt mit einer der regionalen Basislinien verglichen werden können, was ein sofortiges Feedback ermöglicht. Diese Art der Bewertung vereinfacht den Prozess und versetzt die lokalen Akteure in die Lage, unabhängige Bewertungen vorzunehmen, Schlussfolgerungen zu ziehen und auf der Grundlage der Ergebnisse der festgelegten BVs für das Erhebungsgebiet Minderungsstrategien festzulegen.
In den vorherigen Beispielen sind keine Schwellenwerte oder Extremwerte angegeben. Werte, die grösser als Null sind, entsprechen dem erwarteten Medianwert des Objekts für jede gemessene Einheit. Ein Nullwert bedeutet, dass das Objekt in weniger als 50 % der Datenerhebungen gefunden wurde. Der Perzentil-Rang für ein bestimmtes Objekt lässt sich ableiten, indem die Wertetabelle in horizontaler Richtung gelesen wird.
Wie aussagekräftig diese Ergebnisse für die Bewertung von Minderungsstrategien sind, hängt von der Anzahl und Qualität der Proben ab. Interessengruppen auf kommunaler oder lokaler Ebene benötigen detaillierte Daten über bestimmte Objekte. Nationale und internationale Stakeholder hingegen tendieren dazu, breitere, aggregierte Gruppen zu verwenden.
Die Qualität der Daten steht in direktem Zusammenhang mit der Ausbildung und Unterstützung der Personen, die die Datenerhebung durchführen. Der Identifizierungsprozess erfordert ein gewisses Mass an Fachwissen, da viele Objekte und Materialien dem Durchschnittsbürger nicht bekannt sind. Ein Kernteam von erfahrenen Personen, die bei der Entwicklung und Schulung helfen, stellt sicher, dass die Datenerhebungen im Laufe der Zeit konsistent durchgeführt werden.
Das Monitoring-Programm in der Schweiz hat es geschafft, mit den Entwicklungen auf dem Kontinent Schritt zu halten, es gibt jedoch viele Bereiche, die verbessert werden können:
Festlegung einer standardisierten Methode zur Berichterstattung für kommunale, kantonale und nationale Akteure
Definition von Monitoring- oder Bewertungszielen
Formalisierung des Datenspeichers und der Methode zur Implementierung auf verschiedenen Verwaltungsebenen
Aufbau eines Netzwerks von Verbänden, die sich die Verantwortung und die Ressourcen für die Vermessung des Gebiets teilen
Entwicklung und Implementierung eines formellen Schulungsprogramms für die Personen, welche die Datenerhebung ausführen
Ermittlung der idealen Stichproben-Szenarien und des Forschungsbedarfs mit akademischen Partnern
Entwicklung einer Finanzierungsmethode zur Durchführung der empfohlenen Mindestanzahl von Erhebungen (40) pro Erhebungszeitraum und Erhebungsgebiet, um sicherzustellen, dass genaue Bewertungen vorgenommen werden können und die Forschungsanforderungen erfüllt werden.
Veränderungen in den Ergebnissen von Strand-Abfalluntersuchungen sind Signale, und die Verwendung von Basiswerten hilft, das Ausmass dieser Signale zu erkennen. Ohne Kontext oder zusätzliche Informationen können diese Signale jedoch zufällig erscheinen.
Zum Expertenwissen gehört die Fähigkeit, Erhebungsergebnisse in den Kontext lokaler Ereignisse und der Topographie einzuordnen. Dieses Urteilsvermögen in Bezug auf die Daten und die Umgebung ist für die Identifizierung potenzieller Quellen und Prioritäten von wesentlicher Bedeutung.