
Show code cell source
# -*- coding: utf-8 -*-
# This is a report using the data from IQAASL.
# IQAASL was a project funded by the Swiss Confederation
# It produces a summary of litter survey results for a defined region.
# These charts serve as the models for the development of plagespropres.ch
# The data is gathered by volunteers.
# Please remember all copyrights apply, please give credit when applicable
# The repo is maintained by the community effective January 01, 2022
# There is ample opportunity to contribute, learn and teach
# contact dev@hammerdirt.ch
# Dies ist ein Bericht, der die Daten von IQAASL verwendet.
# IQAASL war ein von der Schweizerischen Eidgenossenschaft finanziertes Projekt.
# Es erstellt eine Zusammenfassung der Ergebnisse der Littering-Umfrage für eine bestimmte Region.
# Diese Grafiken dienten als Vorlage für die Entwicklung von plagespropres.ch.
# Die Daten werden von Freiwilligen gesammelt.
# Bitte denken Sie daran, dass alle Copyrights gelten, bitte geben Sie den Namen an, wenn zutreffend.
# Das Repo wird ab dem 01. Januar 2022 von der Community gepflegt.
# Es gibt reichlich Gelegenheit, etwas beizutragen, zu lernen und zu lehren.
# Kontakt dev@hammerdirt.ch
# Il s'agit d'un rapport utilisant les données de IQAASL.
# IQAASL était un projet financé par la Confédération suisse.
# Il produit un résumé des résultats de l'enquête sur les déchets sauvages pour une région définie.
# Ces tableaux ont servi de modèles pour le développement de plagespropres.ch
# Les données sont recueillies par des bénévoles.
# N'oubliez pas que tous les droits d'auteur s'appliquent, veuillez indiquer le crédit lorsque cela est possible.
# Le dépôt est maintenu par la communauté à partir du 1er janvier 2022.
# Il y a de nombreuses possibilités de contribuer, d'apprendre et d'enseigner.
# contact dev@hammerdirt.ch
# sys, file and nav packages:
import datetime as dt
from datetime import date, datetime, time
from babel.dates import format_date, format_datetime, format_time, get_month_names
import locale
# math packages:
import pandas as pd
import numpy as np
from math import pi
# charting:
import matplotlib as mpl
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
from matplotlib import ticker
from matplotlib.ticker import MultipleLocator
import seaborn as sns
from matplotlib import colors as mplcolors
# build report
import reportlab
from reportlab.platypus.flowables import Flowable
from reportlab.platypus import SimpleDocTemplate, Paragraph, Spacer, PageBreak, KeepTogether
from reportlab.lib.pagesizes import A4
from reportlab.lib.units import cm
from reportlab.platypus import Table, TableStyle
# the module that has all the methods for handling the data
import resources.featuredata as featuredata
from resources.featuredata import makeAList, small_space, large_space, aSingleStyledTable, smallest_space
from resources.featuredata import caption_style, subsection_title, title_style, block_quote_style
from resources.featuredata import figureAndCaptionTable, tableAndCaption, aStyledTableWithTitleRow
from resources.featuredata import sectionParagraphs, section_title, addToDoc, makeAParagraph, bold_block
# the module that has all the methods for handling the data
import resources.featuredata as featuredata
from resources.featuredata import makeAList
# home brew utitilties
import resources.chart_kwargs as ck
import resources.sr_ut as sut
# images and display
from PIL import Image as PILImage
from IPython.display import Markdown as md
from myst_nb import glue
# chart style
sns.set_style("whitegrid")
# colors for gradients
cmap2 = ck.cmap2
colors_palette = ck.colors_palette
# border and row shading for tables
a_color = "saddlebrown"
table_row = "saddlebrown"
# a place to save figures and a
# method to choose formats
save_fig_prefix = "resources/output/"
# the arguments for formatting the image
save_figure_kwargs = {
"fname": None,
"dpi": 300.0,
"format": "jpeg",
"bbox_inches": None,
"pad_inches": 0,
"bbox_inches": 'tight',
"facecolor": 'auto',
"edgecolor": 'auto',
"backend": None,
}
## !! Begin Note book variables !!
# There are two language variants: german and english
# change both: date_lang and language
date_lang = 'de_DE.utf8'
locale.setlocale(locale.LC_ALL, date_lang)
# the date format of the survey data is defined in the module
date_format = featuredata.date_format
# the language setting use lower case: en or de
# changing the language may require changing the unit label
language = "de"
unit_label = "p/100 m"
# the standard date format is "%Y-%m-%d" if your date column is
# not in this format it will not work.
# these dates cover the duration of the IQAASL project
start_date = "2020-03-01"
end_date ="2021-05-31"
start_end = [start_date, end_date]
# the fail rate used to calculate the most common codes is
# 50% it can be changed:
fail_rate = 50
# Changing these variables produces different reports
# Call the map image for the area of interest
bassin_map = "resources/maps/bielersee_city_labels.jpeg"
# the label for the aggregation of all data in the region
top = "Alle Erhebungsgebiete"
# define the feature level and components
# the feature of interest is the aare (aare) at the river basin (river_bassin) level.
# the label for charting is called 'name'
this_feature = {'slug':'aare', 'name':"Erhebungsgebiet Aare", 'level':'river_bassin'}
# the lake is in this survey area
this_bassin = "aare"
# label for survey area
bassin_label = "Erhebungsgebiet Aare"
# these are the smallest aggregated components
# choices are water_name_slug=lake or river, city or location at the scale of a river bassin
# water body or lake maybe the most appropriate
this_level = 'water_name_slug'
# the doctitle is the unique name for the url of this document
doc_title = "key_indicators"
# identify the lakes of interest for the survey area
lakes_of_interest = ["neuenburgersee", "thunersee", "bielersee", "brienzersee"]
# !! End note book variables !!
## data
# Survey location details (GPS, city, land use)
dfBeaches = pd.read_csv("resources/beaches_with_land_use_rates.csv")
# set the index of the beach data to location slug
dfBeaches.set_index("slug", inplace=True)
# Survey dimensions and weights
dfDims = pd.read_csv("resources/corrected_dims.csv")
# code definitions
dxCodes = pd.read_csv("resources/codes_with_group_names_2015.csv")
dxCodes.set_index("code", inplace=True)
# columns that need to be renamed. Setting the language will automatically
# change column names, code descriptions and chart annotations
columns={"% to agg":"% agg", "% to recreation": "% recreation", "% to woods":"% woods", "% to buildings":"% buildings", "p/100m":"p/100 m"}
# !key word arguments to construct feature data
# !Note the water type allows the selection of river or lakes
# if None then the data is aggregated together. This selection
# is only valid for survey-area reports or other aggregated data
# that may have survey results from both lakes and rivers.
fd_kwargs ={
"filename": "resources/checked_sdata_eos_2020_21.csv",
"feature_name": this_feature['slug'],
"feature_level": this_feature['level'],
"these_features": this_feature['slug'],
"component": this_level,
"columns": columns,
"language": 'de',
"unit_label": unit_label,
"fail_rate": fail_rate,
"code_data":dxCodes,
"date_range": start_end,
"water_type": None,
}
fdx = featuredata.Components(**fd_kwargs)
# call the reports and languages
fdx.adjustForLanguage()
fdx.makeFeatureData()
fdx.locationSampleTotals()
fdx.makeDailyTotalSummary()
fdx.materialSummary()
fdx.mostCommon()
fdx.codeGroupSummary()
# !this is the feature data!
fd = fdx.feature_data
# !keyword args to build period data
# the period data is all the data that was collected
# during the same period from all the other locations
# not included in the feature data. For a survey area
# or river bassin these_features = feature_parent and
# feature_level = parent_level
period_kwargs = {
"period_data": fdx.period_data,
"these_features": this_feature['slug'],
"feature_level":this_feature['level'],
"feature_parent":this_bassin,
"parent_level": "river_bassin",
"period_name": bassin_label,
"unit_label": unit_label,
"most_common": fdx.most_common.index
}
period_data = featuredata.PeriodResults(**period_kwargs)
# the rivers are considered separately
# select only the results from rivers
# this can be done by updating the fd_kwargs
fd_rivers = fd_kwargs.update({"water_type":"r"})
fdr = featuredata.Components(**fd_kwargs)
fdr.makeFeatureData()
# collects the summarized values for the feature data
# use this to generate the summary data for the survey area
# and the section for the rivers
admin_kwargs = {
"data":fd,
"dims_data":dfDims,
"label": this_feature["name"],
"feature_component": this_level,
"date_range":start_end,
**{"dfBeaches":dfBeaches}
}
admin_details = featuredata.AdministrativeSummary(**admin_kwargs)
admin_summary = admin_details.summaryObject()
# update the admin kwargs with river data to make the river summary
admin_kwargs.update({"data":fdr.feature_data})
admin_r_details = featuredata.AdministrativeSummary(**admin_kwargs)
admin_r_summary = admin_r_details.summaryObject()
# this defines the css rules for the note-book table displays
# this defines the css rules for the note-book table displays
header_row = {'selector': 'th:nth-child(1)', 'props': f'background-color: #FFF;text-align:right;'}
even_rows = {"selector": 'tr:nth-child(even)', 'props': f'background-color: rgba(139, 69, 19, 0.08);'}
odd_rows = {'selector': 'tr:nth-child(odd)', 'props': 'background: #FFF;'}
table_font = {'selector': 'tr', 'props': 'font-size: 12px;'}
table_data = {'selector': 'td', 'props': 'padding:6px;'}
table_css_styles = [even_rows, odd_rows, table_font, header_row]
def convertPixelToCm(file_name: str = None):
im = PILImage.open(file_name)
width, height = im.size
dpi = im.info.get("dpi", (72, 72))
width_cm = width / dpi[0] * 2.54
height_cm = height / dpi[1] * 2.54
return width_cm, height_cm
# pdf download is an option
# reportlab is used to produce the document
# the arguments for the document are captured at run time
# capture for pdf content
pdf_link = f'resources/pdfs/key_indicators.pdf'
glue("blank_caption", " ", display=False)
pdfcomponents = []
# this defines the css rules for the note-book table displays
header_row = {'selector': 'th:nth-child(1)', 'props': f'background-color: #FFF;text-align:right;'}
even_rows = {"selector": 'tr:nth-child(even)', 'props': f'background-color: rgba(139, 69, 19, 0.08);'}
odd_rows = {'selector': 'tr:nth-child(odd)', 'props': 'background: #FFF;'}
table_font = {'selector': 'tr', 'props': 'font-size: 12px;'}
table_data = {'selector': 'td', 'props': 'padding:6px;'}
table_css_styles = [even_rows, odd_rows, table_font, header_row, table_data]
# this defines the css rules for the note-book table displays
header_row = {'selector': 'th:nth-child(1)', 'props': f'background-color: #FFF;text-align:right;'}
table_font = {'selector': 'tr', 'props': 'font-size: 14px;'}
table_data = {'selector': 'td', 'props': 'padding:7px;'}
heat_map_css_styles = [table_font, header_row, table_data]
15. Statistische Schlüsselindikatoren#
Die Schlüsselindikatoren sind einfach zu berechnen und werden direkt aus den Erhebungsergebnissen entnommen. Sie sind für die Identifizierung von Akkumulationszonen im Wassereinzugsgebiet unerlässlich. Wenn sie im Rahmen eines Abfallüberwachungsprogramms verwendet und mit spezifischen Kenntnissen über die Umgebung kombiniert werden, helfen die Schlüsselindikatoren, potenzielle Abfallquellen zu identifizieren. [Han13]
Auswertungen von Untersuchungen des Strand-Abfallaufkommens beschreiben den Ort, die Häufigkeit und die Zusammensetzung der gefundenen Objekte [HG19]. Die Schlüsselindikatoren beantworten die folgenden Fragen:
Welche Objekte werden gefunden?
Wie viel wird gefunden? (Gesamtgewichte und Anzahl der Artikel)
Wie oft werden diese Objekte gefunden?
Wo sind diese Objekte in den grössten Konzentrationen zu finden?
Ähnlich wie bei der Zählung von Vögeln oder Wildblumen muss eine Person die Erhebung durchführen, um die Zielobjekte zu finden und dann zu identifizieren. Dieser Prozess ist gut dokumentiert und wurde unter vielen Bedingungen getestet.[Rya15] [RMCP+15]
15.1. Indikatoren für die am häufigsten gestellten Fragen#
Die Schlüsselindikatoren geben Antworten auf die am häufigsten gestellten Fragen zum Zustand der Abfälle in der natürlichen Umwelt. Die Schlüsselindikatoren sind:
Anzahl der Erhebungen
Bestehens- und Misserfolgsquote (Häufigkeitsrate)
Anzahl der Objekte pro Meter (p/m oder p/m²)
Zusammensetzung (prozentualer Anteil an der Gesamtmenge)
15.1.1. Annahmen zu den Schlüsselindikatoren#
Die Zuverlässigkeit dieser Indikatoren beruht auf den folgenden Annahmen:
Je mehr Abfallobjekte auf dem Boden liegen, desto grösser ist die Wahrscheinlichkeit, dass eine Person sie findet.
Die gefundenen Objekte stellen die Mindestmenge an Abfallobjekten an diesem Erhebungsort dar.
Die Erhebenden befolgen das Protokoll und zeichnen die Ergebnisse genau auf.
Für jede Datenerhebung: Das Auffinden eines Artikels hat keinen Einfluss auf die Wahrscheinlichkeit, einen anderen zu finden.[Sta21a]
15.1.2. Verwendung der Schlüsselindikatoren#
Die Schlüsselindikatoren der häufigsten Objekte werden mit jeder Datenzusammenfassung auf jeder Aggregationsebene angegeben. Wenn die vorherigen Annahmen beibehalten werden, sollte die Anzahl der Proben in der Region von Interesse immer als Mass für die Unsicherheit betrachtet werden. Je mehr Proben innerhalb definierter geografischer und zeitlicher Grenzen liegen, desto grösser ist das Vertrauen in die numerischen Ergebnisse, die aus Ergebnissen innerhalb dieser Grenzen gewonnen werden.
15.2. Definition: Die am häufigsten gefundenen Objekte#
Die am häufigsten vorkommenden Objekte haben eine Häufigkeitsrate von mindestens 50% und/oder befinden sich in einem bestimmten geografischen Gebiet unter den Top Ten nach Menge oder Stückzahl/m.
15.3. Die wichtigsten Indikatoren#
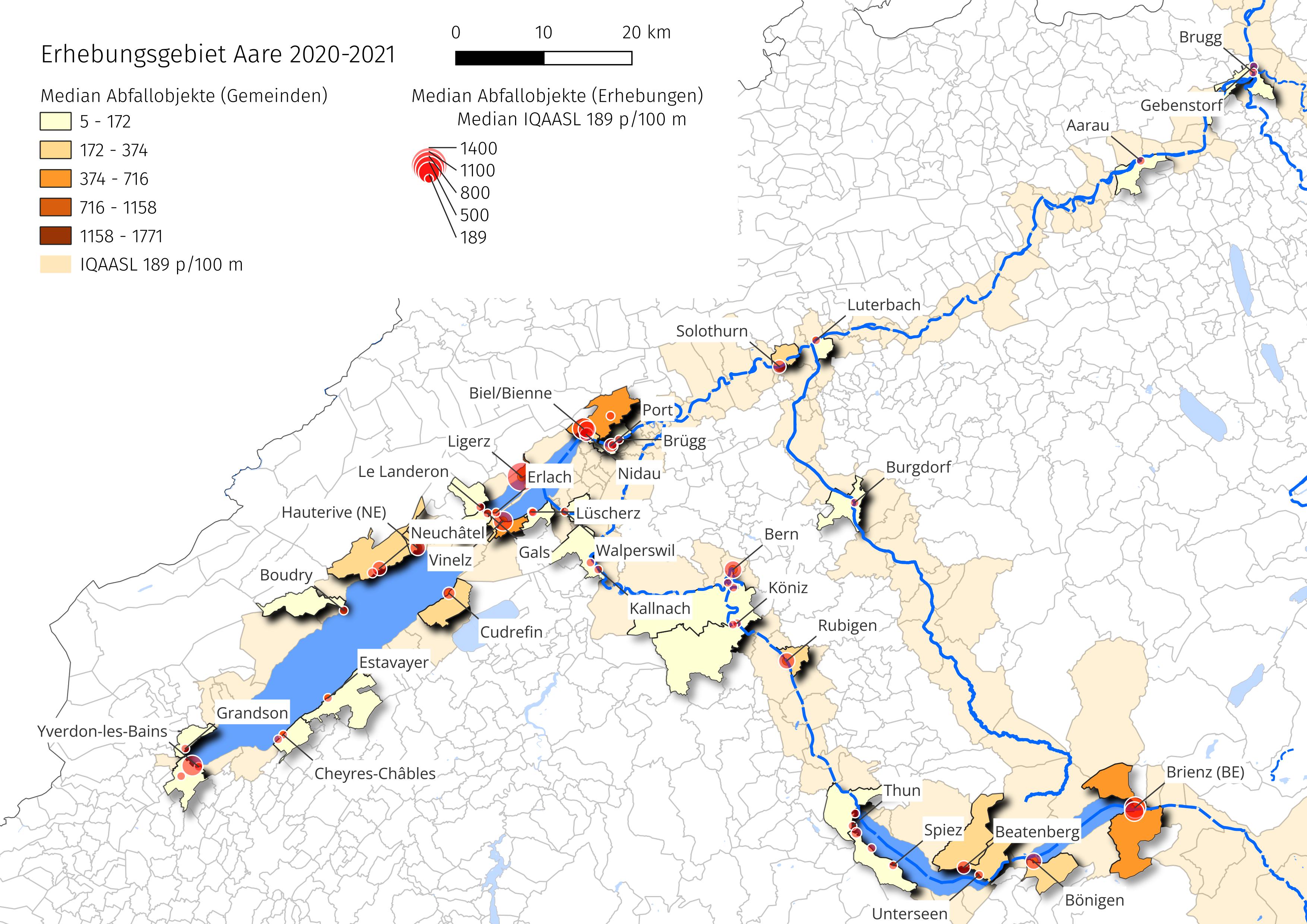
Abb. 15.1 #
Abbildung 15.1: Im Zeitraum von März 2020 und bis Mai 2021 wurden bei 140 Erhebungen im Aare-Erhebungsgebiet 13 847 Objekte gesammelt.
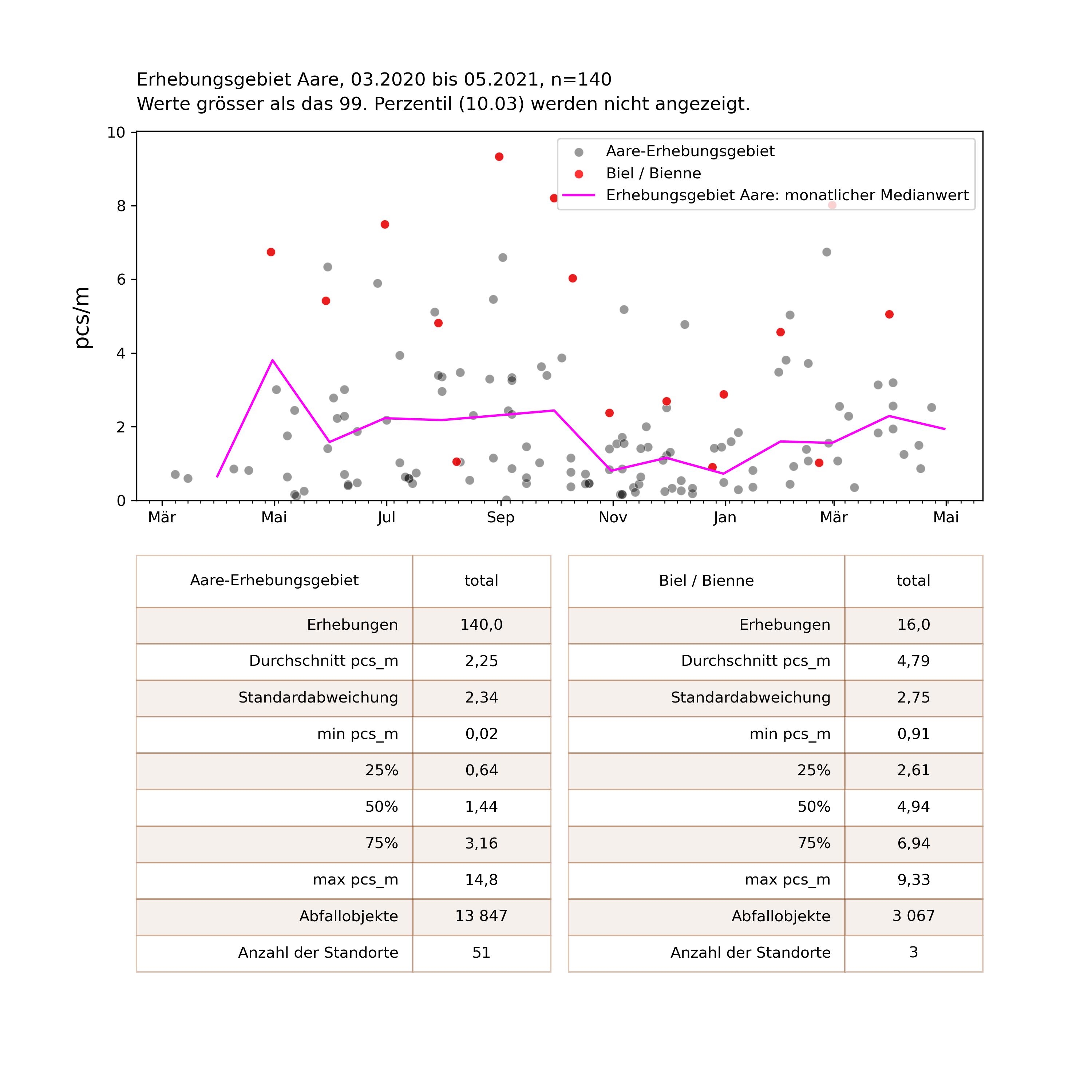
Abb. 15.2 #
Abbildung 15.2: Die Resultate des Erhebungsgebiets Aare, mit Ausschnitt Biel/Bienne und Monatsmedian. links: Zusammenfassende Statistik für das Erhebungsgebiet Aare. Rechts: Zusammenfassende Statistik Biel/Bienne.
15.3.1. Die Anzahl der Proben#
Die Anzahl der Proben bezieht sich auf die Anzahl der Proben innerhalb eines geografischen und zeitlichen Bereichs. Wie bereits erwähnt, kann den Ergebnissen der Analyse umso mehr Vertrauen geschenkt werden, je mehr Proben innerhalb eines bestimmten Gebiets und Zeitraums vorhanden sind.
15.3.2. Die Häufikeitsrate#
Die Häufigkeitsrate ist die Anzahl der Fälle, in denen ein Objekt mindestens einmal gefunden wurde, geteilt durch die Anzahl der Datenerhebungen.
Was bedeutet das? Die Häufigkeitsrate beschreibt den Prozentsatz der Fälle, in denen eine Kategorie im Verhältnis zur Anzahl der durchgeführten Datenerhebungen identifiziert wurde. Hinweis: Die Häufigkeitsrate gibt keinen Hinweis auf die Menge.
Die Häufigkeitsrate ist zu verwenden, um festzustellen, wie häufig ein Objekt innerhalb eines geografischen Bereichs gefunden wurde. Objekte können nach Häufigkeitsrate unterschieden werden. Die Häufigkeitsrate und p/m ist zu verwenden, um Objekte zu identifizieren, die nur selten, aber in grossen Mengen gefunden werden.
Unterschiedliche Häufigkeitsraten auf verschiedenen Ebenen
Die Häufigkeitsrate wird auf jeder Aggregationsebene berechnet. Daher ändert sich die Häufigkeitsrate für ein bestimmtes Objekt je nach den geografischen Grenzen, die die Aggregationsebene definieren. Für das Erhebungsgebiet Aare sind alle Objekte mit einer Häufigkeitsrate von mindestens 50 % zu betrachten.
Show code cell source
# identify the most common and the most abundant objects in the river bassin
fd["fail"] = fd.quantity > 0
trb = fd.copy()
trb_mc = trb.groupby(['loc_date','code'], as_index=False).agg({'fail':'sum', 'quantity':'sum', unit_label:'sum'})
trb_mcom = trb_mc.groupby('code', as_index=False).agg({'fail':'sum', 'quantity':'sum', unit_label:'median'})
trb_total = trb.quantity.sum()
# get the fail rate and separate the data into most common and most abundant
trb_mcom['f_r'] = trb_mcom.fail/trb.loc_date.nunique()
# joint list
thecommon = fdx.most_common.index
trbx = trb_mcom[trb_mcom.code.isin(thecommon)][["code", "f_r"]]
trbx.rename(columns={"f_r":"Erhebungsgebiet Aare"}, inplace=True)
biel = trb[(trb.city == 'Biel/Bienne')&(trb.code.isin(thecommon))&(trb.w_t == "l")].copy()
biel_total = biel.quantity.sum()
biel_mc = biel.groupby(['loc_date','code'], as_index=False).agg({'fail':'sum','quantity':'sum',unit_label:'sum'})
biel = biel_mc.groupby('code', as_index=False).agg({'fail':'sum', 'quantity':'sum', unit_label:'median'})
biel['f_r'] = biel.fail/biel_mc.loc_date.nunique()
bielx = biel[["code", "f_r"]].copy()
bielx.rename(columns={"f_r":'Biel/Bienne'}, inplace=True)
biel_see = trb[(trb.water_name_slug == 'bielersee')&(trb.code.isin(thecommon))].copy()
biel_see_total = biel_see.quantity.sum()
biel_see_mc = biel_see.groupby(['loc_date','code'], as_index=False).agg({'fail':'sum', 'quantity':'sum', unit_label:'sum'})
biel_see = biel_see_mc.groupby('code', as_index=False).agg({'fail':'sum', 'quantity':'sum', unit_label:'median'})
biel_see['f_r'] = biel_see.fail/biel_see_mc.loc_date.nunique()
biel_seex = biel_see[["code", "f_r"]].copy()
biel_seex.rename(columns={"f_r":"Bielersee"}, inplace=True)
pdata = period_data.period_data.copy()
pdata_total = pdata.quantity.sum()
pdata["fail"] = pdata.quantity > 0
period_see = pdata[(pdata.code.isin(thecommon))].copy()
period_see_mc = period_see.groupby(['loc_date','code'], as_index=False).agg({'fail':'sum', 'quantity':'sum', unit_label:'sum'})
period_see = period_see_mc.groupby('code', as_index=False).agg({'fail':'sum', 'quantity':'sum', unit_label:'median'})
period_see['f_r'] = period_see.fail/period_see_mc.loc_date.nunique()
period_seex = period_see[["code", "f_r"]].copy()
period_seex.rename(columns={"f_r":"Alle Erhebungsgebiete"}, inplace=True)
fail_rates = bielx.merge(biel_seex, on="code")
fail_rate = fail_rates.merge(trbx, on="code")
fail_rate = fail_rate.merge(period_seex, on="code")
fail_rate.set_index("code", inplace=True)
fail_rate = fail_rate.round(2)
fail_rate = fail_rate.sort_values(by="Bielersee", ascending=False)
fail_rate.index = fail_rate.index.map(lambda x: fdx.dMap.loc[x])
fail_ratex = fail_rate * 100
# notebook display style
aformatter = {x: featuredata.replaceDecimal for x in fail_rate.columns}
mcd = fail_ratex.style.format(precision=0).set_table_styles(heat_map_css_styles)
mcd = mcd.background_gradient(axis=None, vmin=fail_ratex.min().min(), vmax=fail_ratex.max().max(), cmap="YlOrBr")
# remove the index name and column name labels
mcd.index.name = None
mcd.columns.name = None
# rotate the text on the header row
# the .applymap_index method in the
# df.styler module is used for this
mcd = mcd.applymap_index(featuredata.rotateText, axis=1)
glue("fail_rate", mcd, display=False)
| Biel/Bienne | Bielersee | Erhebungsgebiet Aare | Alle Erhebungsgebiete | |
|---|---|---|---|---|
| Fragmentierte Kunststoffe | 100 | 97 | 89 | 86 |
| Industriefolie (Kunststoff) | 93 | 89 | 74 | 70 |
| Snack-Verpackungen | 93 | 87 | 82 | 85 |
| Zigarettenfilter | 100 | 79 | 84 | 88 |
| Getränkeflaschen aus Glas, Glasfragmente | 71 | 68 | 68 | 65 |
| Verpackungsfolien, nicht für Lebensmittel | 64 | 63 | 50 | 39 |
| Expandiertes Polystyrol | 100 | 63 | 65 | 69 |
| Industriepellets (Nurdles) | 79 | 61 | 33 | 31 |
| Verpackungen aus Aluminiumfolie | 100 | 61 | 51 | 47 |
| Schaumstoffverpackungen/Isolierung | 93 | 50 | 49 | 53 |
| Styropor < 5mm | 71 | 34 | 28 | 26 |
Abb. 15.3 #
Abbildung 15.3: Die Häufigkeitsraten der am meisten gefundenen Objekte aus dem Erhebungsgebiet Aare bei verschiedenen Aggregationsstufen.
Mit Ausnahme von Industriefolien und Kunststofffragmenten war die Häufigkeitsrate in Biel/Bienne höher als in allen anderen Untersuchungsgebieten. Das bedeutet, dass die Wahrscheinlichkeit, diese Objekte zu finden, in Biel pro Untersuchung grösser war als an den meisten anderen Orten.
Die Häufigkeitsrate ist die wahrscheinlichste Schätzung (MLE) der Wahrscheinlichkeit, mindestens ein Objekt zu finden [CP17]. Wenn das Objekt in allen vorherigen Stichproben identifiziert wurde und sich Präventionsmassnahmen nicht geändert haben, kann man davon ausgehen, dass auch in den folgenden Stichproben mindestens ein Objekt zu finden sein wird.
15.3.3. Objekte pro Meter#
Objekte pro Meter (p/m) ist die Anzahl der bei jeder Untersuchung gefundenen Objekte geteilt durch die Länge der untersuchten Uferlinie.
Was bedeutet das? p/m beschreibt die Menge eines Objekts, das pro Meter gefunden wurde. Es handelt sich um eine Methode zur Normalisierung der Daten aus allen Vermessungen, damit sie verglichen werden können.
P/m ist zu verwenden um die Objekte zu finden, die in den grössten Mengen gefunden wurden. Mit p/m können Zonen der Anhäufung identifiziert werden.
Warum nicht die Fläche verwenden? Der EU-Standard empfiehlt, die Ergebnisse als Anzahl der Objekte pro Länge der untersuchten Küstenlinie anzugeben, normalerweise 100 Meter [HG19]. Die Fläche wurde für 99 % aller Erhebungen in IQAASL berechnet. Die Ergebnisse für diese Analyse werden in p/m angegeben.
Show code cell source
cols = ["code", unit_label]
trb_pcs = trb_mcom[cols].copy()
trb_pcs.rename(columns={unit_label:"Erhebungsgebiet Aare"}, inplace=True)
biel_pcs = biel[cols].copy()
biel_pcs.rename(columns={unit_label: "Biel/Bienne"}, inplace=True)
bielsee_pcs = biel_see[cols].copy()
bielsee_pcs.rename(columns={unit_label:"Bielersee"}, inplace=True)
periodsee_pcs = period_see[cols].copy()
periodsee_pcs.rename(columns={unit_label:"Alle Erhebungsgebiete"}, inplace=True)
pcs_m = biel_pcs.merge(bielsee_pcs, on="code")
pcs_m = pcs_m.merge(trb_pcs, on="code")
pcs_m = pcs_m.merge(periodsee_pcs, on="code")
pcs_m.set_index("code", drop=True, inplace=True)
pcs_m.index = pcs_m.index.map(lambda x: fdx.dMap.loc[x])
pcs_m = pcs_m.round(1)
pcs_b = pcs_m.style.format(aformatter).set_table_styles(heat_map_css_styles)
pcs_b = pcs_b.background_gradient(axis=None, vmin=pcs_m.min().min(), vmax=pcs_m.max().max(), cmap="YlOrBr")
# remove the index name and column name labels
pcs_b.index.name = None
pcs_b.columns.name = None
# rotate the text on the header row
# the .applymap_index method in the
# df.styler module is used for this
pcs_b = pcs_b.applymap_index(featuredata.rotateText, axis=1)
glue("pcs_m", pcs_b, display=False)
| Biel/Bienne | Bielersee | Erhebungsgebiet Aare | Alle Erhebungsgebiete | |
|---|---|---|---|---|
| Industriepellets (Nurdles) | 4,5 | 2,5 | 0,0 | 0,0 |
| Styropor < 5mm | 8,0 | 0,0 | 0,0 | 0,0 |
| Verpackungen aus Aluminiumfolie | 6,5 | 2,5 | 1,0 | 0,0 |
| Getränkeflaschen aus Glas, Glasfragmente | 2,5 | 5,5 | 3,0 | 3,0 |
| Zigarettenfilter | 118,5 | 9,0 | 11,0 | 20,0 |
| Snack-Verpackungen | 41,5 | 21,0 | 8,0 | 9,0 |
| Industriefolie (Kunststoff) | 20,5 | 18,0 | 5,0 | 5,0 |
| Schaumstoffverpackungen/Isolierung | 7,5 | 1,0 | 0,0 | 1,0 |
| Verpackungsfolien, nicht für Lebensmittel | 10,5 | 9,5 | 0,5 | 0,0 |
| Expandiertes Polystyrol | 19,0 | 5,5 | 4,0 | 5,0 |
| Fragmentierte Kunststoffe | 50,5 | 53,0 | 18,5 | 18,0 |
Abb. 15.4 #
Abbildung 15.4: Der Median (p/m) der häufigsten Objekte im Erhebungsgebiet Aare.
Der angegebene Wert ist der Median der Erhebungsergebnisse für diese Aggregationsebene und dieses Objekt. Ein Medianwert von Null bedeutet, dass das Objekt in weniger als 1/2 der Erhebungen für diese Aggregationsebene identifiziert wurde. Betrachten wir zum Beispiel die Ergebnisse für Dämmstoffe, einschliesslich Spritzschäumen: Der Medianwert für das Erhebungsgebiet Aare ist gleich Null. Betrachtet man jedoch nur die Ergebnisse vom Bielersee oder jene aus Biel/Bienne, ist der Medianwert grösser als Null. Dies deutet darauf hin, dass am Bielersee und speziell in Biel/Bienne mehr Dämmstoffe gefunden wurden als im übrigen Aaregebiet.
15.3.4. Prozentsatz der Gesamtmenge#
Der prozentuale Anteil an der Gesamtzahl ist die Menge eines gefundenen Objekts geteilt durch die Gesamtzahl aller gefundenen Objekte für eine(n) bestimmte(n) Ort/Region und einen bestimmten Datumsbereich.
Was bedeutet das? Der prozentuale Anteil an der Gesamtmenge beschreibt die Zusammensetzung der gefundenen Abfallobjekte.
Der prozentuale Anteil an der Gesamtmenge ist zu verwenden, um die wichtigsten Abfallobjekten zu definieren. Mit dem prozentualen Anteil können Prioritäten auf regionaler Ebene ermittelt werden.
Ähnlich wie bei den Objekten pro Meter ist ein Objekt mit einer niedrigen Häufigkeitsrate und einem hohen Prozentsatz an der Gesamtzahl ein Signal dafür, dass Objekte möglicherweise in unregelmässigen Abständen in grossen Mengen deponiert werden: Verklappung oder Unfälle.
Show code cell source
cols = ["code", "quantity"]
trb_pcnt = trb_mcom[trb_mcom.code.isin(thecommon)][cols].copy()
trb_pcnt["Erhebungsgebiet Aare"] = trb_pcnt.quantity/trb_total
trb_pcnt = trb_pcnt[["code", "Erhebungsgebiet Aare"]].copy()
biel_pcnt = biel[cols].copy()
biel_pcnt["Biel/Bienne"] = biel_pcnt.quantity/trb[(trb.city == 'Biel/Bienne')].quantity.sum()
biel_pcnt = biel_pcnt[["code", "Biel/Bienne"]].copy()
bielsee_pcnt = biel_see[cols].copy()
bielsee_pcnt["Bielersee"] = bielsee_pcnt.quantity/trb[(trb.water_name_slug == 'bielersee')].quantity.sum()
bielsee_pcnt = bielsee_pcnt[["code", "Bielersee"]].copy()
periodsee_pcnt = period_see[cols].copy()
periodsee_pcnt["Alle Erhebungsgebiete"] = periodsee_pcnt.quantity/pdata_total
periodsee_pcnt = periodsee_pcnt[["code", "Alle Erhebungsgebiete"]].copy()
pcnts = biel_pcnt.merge(bielsee_pcnt, on="code")
pcnts = pcnts.merge(trb_pcnt, on="code")
pcnts = pcnts.merge(periodsee_pcnt, on="code")
pcnts.set_index("code", drop=True, inplace=True)
pcnts.index = pcnts.index.map(lambda x: fdx.dMap.loc[x])
pccnts_out = pcnts.copy()
pcnts = (pcnts * 100).round(0)
pcnt_b = pcnts.style.format(precision=0).set_table_styles(heat_map_css_styles)
pcnt_b = pcnt_b.background_gradient(axis=None, vmin=pcnts.min().min(), vmax=pcnts.max().max(), cmap="YlOrBr")
# remove the index name and column name labels
pcnt_b.index.name = None
pcnt_b.columns.name = None
# rotate the text on the header row
# the .applymap_index method in the
# df.styler module is used for this
pcnt_b = pcnt_b.applymap_index(featuredata.rotateText, axis=1)
glue("pcnts", pcnt_b, display=False)
| Biel/Bienne | Bielersee | Erhebungsgebiet Aare | Alle Erhebungsgebiete | |
|---|---|---|---|---|
| Industriepellets (Nurdles) | 1 | 2 | 2 | 4 |
| Styropor < 5mm | 2 | 2 | 2 | 2 |
| Verpackungen aus Aluminiumfolie | 2 | 1 | 1 | 1 |
| Getränkeflaschen aus Glas, Glasfragmente | 3 | 4 | 5 | 4 |
| Zigarettenfilter | 22 | 17 | 18 | 15 |
| Snack-Verpackungen | 7 | 7 | 6 | 6 |
| Industriefolie (Kunststoff) | 5 | 7 | 6 | 5 |
| Schaumstoffverpackungen/Isolierung | 2 | 2 | 2 | 3 |
| Verpackungsfolien, nicht für Lebensmittel | 3 | 4 | 3 | 2 |
| Expandiertes Polystyrol | 5 | 4 | 6 | 10 |
| Fragmentierte Kunststoffe | 12 | 17 | 14 | 14 |
Abb. 15.5 #
Abbildung 15.5: Die häufigsten Objekte im Erhebungsgebiet Aare machen rund 66 % (2022) der Gesamtzahl der erfassten Objekte (3067) an den drei Erhebungsorten in Biel/Bienne aus.
15.4. Diskussion#
Zwischen April 2020 und Mai 2021 wurden 16 Datenerhebungen an 3 verschiedenen Orten in Biel/Bienne durchgeführt, bei denen 3067 Objekte identifiziert werden konnten. Die häufigsten Objekte aus dem Erhebungsgebiet Aare machen 66 % aller in Biel identifizierten Objekte aus. Objekte, die in direktem Zusammenhang mit dem Konsum stehen (Lebensmittel, Getränke, Tabak), werden in einer Häufigkeit gefunden, die über dem Median des Erhebungsgebiets liegt, den diese Objekte stellen rund 34 % der gesammelten Abfallobjekte in Biel/Bienne dar, im Vergleich zu 25 % für alle Untersuchungsgebiete.
Objekte, die nicht direkt mit Konsumverhalten in Verbindung stehen, wie zerbrochene Kunststoffe, Industriefolien, expandiertes Polystyrol oder Industriepellets, werden in grösseren Mengen gefunden als im übrigen Erhebungsgebiet Aare. Expandiertes Polystyrol wird als äussere Isolierhülle für Gebäude (Neubauten und Renovierungen) und zum Schutz von Bauteilen beim Transport verwendet. Biel hat eine starke industrielle Basis und eine aktive Bau- und Produktionsbasis. Zusammengenommen machen diese Objekte 30 % der insgesamt gesammelten Objekte aus.
15.4.1. Anwendung#
Bei den Schlüsselindikatoren handelt es sich um einfache Kennzahlen, die direkt aus den Erhebungsergebnissen übernommen wurden. Änderungen in der Grössenordnung dieser Verhältnisse signalisieren Änderungen in der relativen Menge bestimmter Objekte. Wenn die Schlüsselindikatoren im Rahmen eines Überwachungsprogramms verwendet werden, ermöglichen sie die Identifizierung wahrscheinlicher Anreicherungszonen.
15.4.2. Praktische Übung#
Industrielle Kunststoffgranulate (GPI) sind das wichtigste Material zur Herstellung von Kunststoffgegenständen, die in der Schweiz in grossem Umfang verwendet werden. Sie sind scheiben- oder pelletförmig und haben einen Durchmesser von ungefähr 5 mm.
Beantworten Sie anhand der folgenden Erhebungsergebnisse, der Karte mit den Erhebungsorten und unter Beibehaltung der zu Beginn dieses Artikels dargestellten Annahmen die folgenden Fragen:
Wo besteht die grösste Wahrscheinlichkeit, mindestens ein Vorkommen des Abfallobjekts zu finden?
Wie gross ist die wahrscheinliche Mindestmenge an Pellets, die Sie bei einer Untersuchung von 50 Metern finden würden?
Warum haben Sie sich für diesen Ort oder diese Orte entschieden? Wie sicher sind Sie sich bei Ihrer Wahl?
Show code cell source
aggs = {'loc_date':'nunique', 'fail':'sum', 'pcs_m':'mean', "quantity":"sum"}
new_col_names = {"loc_date":"Anzahl Proben", "fail":"Anzahl der Fälle", "pcs_m":"Median p/m", "quantity":"Gefunden"}
biel_g95 = fd[(fd.water_name_slug == 'bielersee')&(fd.code == 'G112')].groupby(['location']).agg(aggs)
biel_g95.rename(columns=new_col_names, inplace=True)
biel_g95["Median p/m"] = biel_g95["Median p/m"].round(3)
biel_g95.index.name = None
dims_table_caption = [
""
]
# pdf table out
dims_table_caption = ''.join(dims_table_caption)
col_widths = [4.2*cm, 2.5*cm, 2.5*cm, 2.5*cm, 2.5*cm]
dims_pdf_table = featuredata.aSingleStyledTable(biel_g95, colWidths=col_widths, style=featuredata.default_table_style)
dims_pdf_table_caption = Paragraph(dims_table_caption, style=caption_style)
pdf_table_and_caption = featuredata.tableAndCaption(dims_pdf_table, dims_pdf_table_caption,col_widths)
header_row = {'selector': 'th:nth-child(1)', 'props': f'background-color: #FFF;'}
even_rows = {"selector": 'tr:nth-child(even)', 'props': f'background-color: rgba(139, 69, 19, 0.08);'}
odd_rows = {'selector': 'tr:nth-child(odd)', 'props': 'background: #FFF;'}
table_font = {'selector': 'tr', 'props': 'font-size: 12px;'}
table_css_styles = [even_rows, odd_rows, table_font, header_row]
formatter = {
"Median p/m": lambda x: featuredata.replaceDecimal(round(x,3), "de"),
}
mcc = biel_g95.style.format(formatter).set_table_styles(table_css_styles)
mcc
| Anzahl Proben | Anzahl der Fälle | Median p/m | Gefunden | |
|---|---|---|---|---|
| bielersee_vinelz_fankhausers | 12 | 9 | 0,128 | 22 |
| camp-des-peches | 1 | 0 | 0,0 | 0 |
| erlach-camping-strand | 1 | 0 | 0,0 | 0 |
| gals-reserve | 2 | 0 | 0,0 | 0 |
| ligerz-strand | 2 | 0 | 0,0 | 0 |
| luscherz-plage | 4 | 2 | 0,015 | 3 |
| luscherz-two | 1 | 0 | 0,0 | 0 |
| mullermatte | 12 | 9 | 0,073 | 37 |
| nidau-strand | 1 | 1 | 0,08 | 2 |
| strandboden-biel | 2 | 2 | 0,065 | 7 |
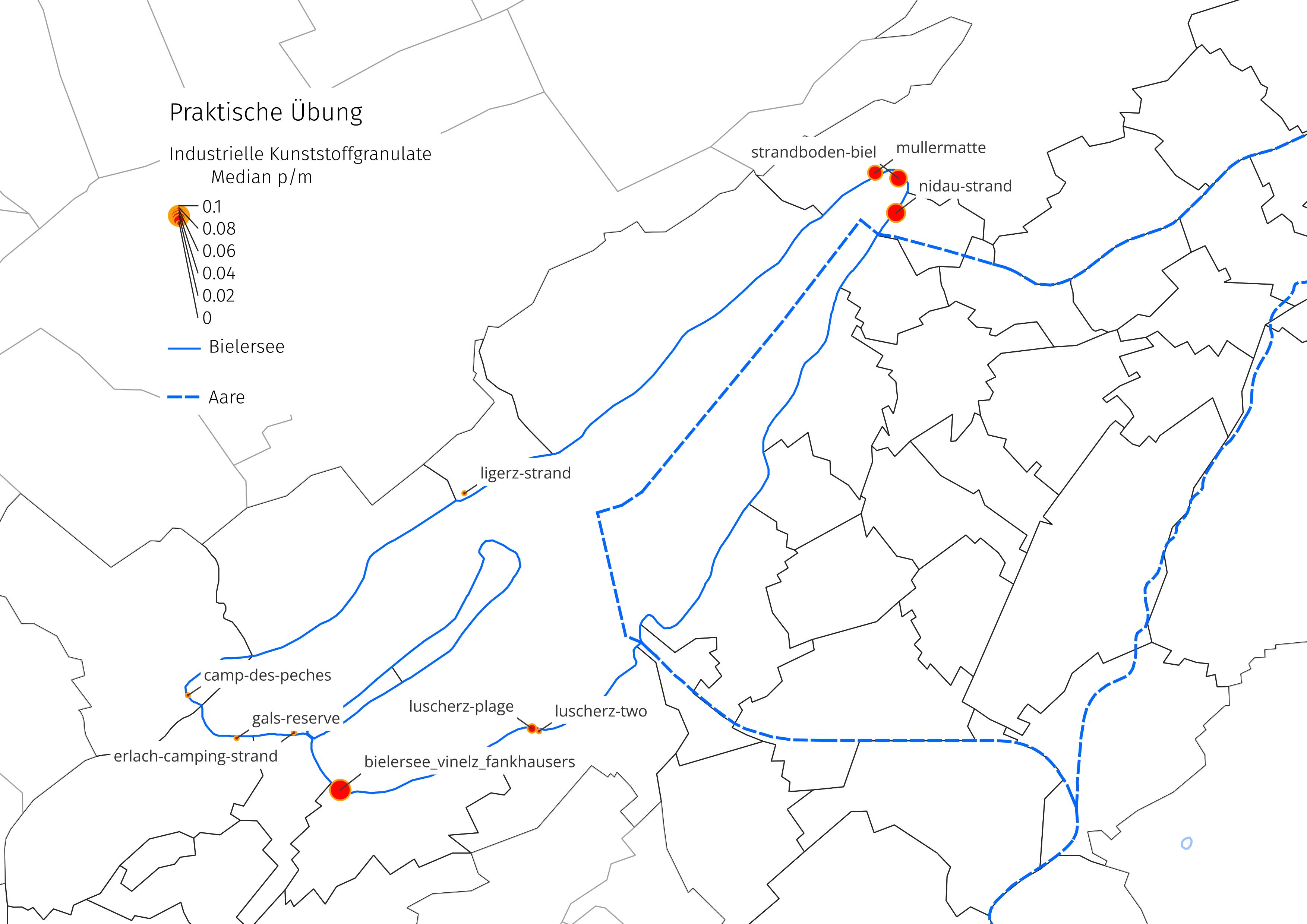
Abb. 15.6 #
Abbildung 15.6: Die häufigsten Objekte im Erhebungsgebiet Aare machen rund 66 % (2022) der Gesamtzahl der erfassten Objekte (3067) an den drei Erhebungsorten in Biel/Bienne aus.