
Show code cell source
# -*- coding: utf-8 -*-
# This is a report using the data from IQAASL.
# IQAASL was a project funded by the Swiss Confederation
# It produces a summary of litter survey results for a defined region.
# These charts serve as the models for the development of plagespropres.ch
# The data is gathered by volunteers.
# Please remember all copyrights apply, please give credit when applicable
# The repo is maintained by the community effective January 01, 2022
# There is ample opportunity to contribute, learn and teach
# contact dev@hammerdirt.ch
# Dies ist ein Bericht, der die Daten von IQAASL verwendet.
# IQAASL war ein von der Schweizerischen Eidgenossenschaft finanziertes Projekt.
# Es erstellt eine Zusammenfassung der Ergebnisse der Littering-Umfrage für eine bestimmte Region.
# Diese Grafiken dienten als Vorlage für die Entwicklung von plagespropres.ch.
# Die Daten werden von Freiwilligen gesammelt.
# Bitte denken Sie daran, dass alle Copyrights gelten, bitte geben Sie den Namen an, wenn zutreffend.
# Das Repo wird ab dem 01. Januar 2022 von der Community gepflegt.
# Es gibt reichlich Gelegenheit, etwas beizutragen, zu lernen und zu lehren.
# Kontakt dev@hammerdirt.ch
# Il s'agit d'un rapport utilisant les données de IQAASL.
# IQAASL était un projet financé par la Confédération suisse.
# Il produit un résumé des résultats de l'enquête sur les déchets sauvages pour une région définie.
# Ces tableaux ont servi de modèles pour le développement de plagespropres.ch
# Les données sont recueillies par des bénévoles.
# N'oubliez pas que tous les droits d'auteur s'appliquent, veuillez indiquer le crédit lorsque cela est possible.
# Le dépôt est maintenu par la communauté à partir du 1er janvier 2022.
# Il y a de nombreuses possibilités de contribuer, d'apprendre et d'enseigner.
# contact dev@hammerdirt.ch
# sys, file and nav packages:
import datetime as dt
# for date and month formats in french or german
import locale
from babel.dates import format_date, format_datetime, format_time, get_month_names
# math packages:
import pandas as pd
import numpy as np
from scipy import stats
from statsmodels.distributions.empirical_distribution import ECDF
# charting:
import matplotlib as mpl
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
from matplotlib import ticker
from matplotlib import colors
from matplotlib.colors import LinearSegmentedColormap
from matplotlib.ticker import MultipleLocator
from matplotlib.gridspec import GridSpec
import seaborn as sns
# home brew utitilties
import resources.chart_kwargs as ck
import resources.sr_ut as sut
from PIL import Image as PILImage
from IPython.display import Markdown as md
from IPython.display import display_html
from myst_nb import glue
# build report
import reportlab
from reportlab.lib.styles import getSampleStyleSheet, ParagraphStyle
from reportlab.lib import colors
from reportlab.platypus.flowables import Flowable
from reportlab.platypus import SimpleDocTemplate, Paragraph, Spacer, PageBreak, KeepTogether, Image
from reportlab.lib.pagesizes import A4
from reportlab.lib.units import cm
from reportlab.platypus import Table, TableStyle
# the module that has all the methods for handling the data
import resources.featuredata as featuredata
from resources.featuredata import makeAList, small_space, large_space, aSingleStyledTable, smallest_space
from resources.featuredata import caption_style, subsection_title, title_style, block_quote_style, makeBibEntry
from resources.featuredata import figureAndCaptionTable, tableAndCaption, aStyledTableWithTitleRow
from resources.featuredata import sectionParagraphs, section_title, addToDoc, makeAParagraph, bold_block
def convertPixelToCm(file_name: str = None):
im = PILImage.open(file_name)
width, height = im.size
dpi = im.info.get("dpi", (72, 72))
width_cm = width / dpi[0] * 2.54
height_cm = height / dpi[1] * 2.54
return width_cm, height_cm
# a place to save figures and a
# method to choose formats
save_fig_prefix = "resources/output/"
# the arguments for formatting the image
save_figure_kwargs = {
"fname": None,
"dpi": 300.0,
"format": "jpeg",
"bbox_inches": None,
"pad_inches": 0,
"bbox_inches": 'tight',
"facecolor": 'auto',
"edgecolor": 'auto',
"backend": None,
}
# this defines the css rules for the note-book table displays
header_row = {'selector': 'th:nth-child(1)', 'props': f'background-color: #FFF;text-align:right;'}
even_rows = {"selector": 'tr:nth-child(even)', 'props': f'background-color: rgba(139, 69, 19, 0.08);'}
odd_rows = {'selector': 'tr:nth-child(odd)', 'props': 'background: #FFF;'}
table_font = {'selector': 'tr', 'props': 'font-size: 12px;'}
table_data = {'selector': 'td', 'props': 'padding:6px;'}
table_css_styles = [even_rows, odd_rows, table_font, header_row, table_data]
# this defines the css rules for the note-book table displays
header_row = {'selector': 'th:nth-child(1)', 'props': f'background-color: #FFF;text-align:right;'}
table_font = {'selector': 'tr', 'props': 'font-size: 10px;'}
table_data = {'selector': 'td', 'props': 'padding:4px;'}
heat_map_css_styles = [table_font, header_row, table_data]
# set the locale to the language desired
# the locale is set back to to original at the the end of the script
loc = locale.getlocale()
date_lang = 'de_DE.utf8'
lang = 'de_CH.utf8'
locale.setlocale(locale.LC_ALL, lang)
unit_label = "p/100 m"
unit_value = 100
fail_rate = 50
sns.set_style("whitegrid")
# colors for gradients
cmap2 = ck.cmap2
# colors for projects
this_palette = {"IQAASL":"dodgerblue", "SLR":"magenta"}
this_palettel = {"IQAASL":"teal", "SLR":"indigo"}
# get the data:
survey_data = pd.read_csv("resources/agg_results_with_land_use_2015.csv")
dfBeaches = pd.read_csv("resources/beaches_with_land_use_rates.csv")
dfCodes = pd.read_csv("resources/codes_with_group_names_2015.csv")
# a common aggregation
agg_pcs_quantity = {unit_label:"sum", "quantity":"sum"}
# reference columns
use_these_cols = ["survey year","loc_date" ,"% to buildings", "% to trans", "% to recreation", "% to agg", "% to woods","population","water_name_slug","streets km", "intersects", "groupname","code"]
# explanatory variables:
luse_exp = ["% to buildings", "% to recreation", "% to agg", "% to woods", "streets km", "intersects"]
# lakes that have samples in both years
these_lakes = ["zurichsee", "bielersee", "lac-leman", "neuenburgersee", "walensee", "thunersee"]
# set the index of the beach data to location slug
dfBeaches.set_index("slug", inplace=True)
# index the code data
dfCodes.set_index("code", inplace=True)
# the surveyor designated the object as aluminum instead of metal
dfCodes.loc["G708", "material"] = "Metal"
# language specific
# importing german code descriptions
de_codes = pd.read_csv("resources/codes_german_Version_1.csv")
de_codes.set_index("code", inplace=True)
for x in dfCodes.index:
dfCodes.loc[x, "description"] = de_codes.loc[x, "german"]
# there are long code descriptions that may need to be shortened for display
codes_to_change = [
["G704", "description", "Seilbahnbürste"],
["Gfrags", "description", "Fragmentierte Kunststoffstücke"],
["G30", "description", "Snack-Verpackungen"],
["G124", "description", "Kunststoff-oder Schaumstoffprodukte"],
["G87", "description", "Abdeckklebeband/Verpackungsklebeband"],
["G178","description","Flaschenverschlüsse aus Metall"],
["G3","description","Einkaufstaschen, Shoppingtaschen"],
["G33", "description", "Einwegartikel; Tassen/Becher & Deckel"],
["G31", "description", "Schleckstengel, Stengel von Lutscher"],
["G211", "description", "Sonstiges medizinisches Material"],
["G904", "description", "Feuerwerkskörper; Raketenkappen"],
["G940", "description", "Schaumstoff EVA (flexibler Kunststoff)"],
["G82", "description", "Expandiertem Polystyrol 2,5 - 50 cm"]
]
# apply changes
for x in codes_to_change:
dfCodes = sut.shorten_the_value(x, dfCodes)
# translate the material column
dfCodes["material"] = dfCodes.material.map(lambda x: sut.mat_ge[x])
# make a map to the code descriptions
code_description_map = dfCodes.description
# make a map to the code materials
code_material_map = dfCodes.material
pdf_link = 'resources/pdfs/slr_iqaasl.pdf'
source_prefix = "https://hammerdirt-analyst.github.io/IQAASL-End-0f-Sampling-2021/"
source = "slr-iqaasl.html"
# the components are stored in an array and collected as the script runs
pdfcomponents = []
glue("blank_caption", " ", display=False)
# pdf title and map
pdf_title = Paragraph("Vergleich der Datenerhebungen seit 2018", featuredata.title_style)
o_w, o_h = convertPixelToCm("resources/maps/slr_iqasl.jpeg")
figure_kwargs = {
"image_file":"resources/maps/slr_iqasl.jpeg",
"caption": None,
"original_width":o_w,
"original_height":o_h,
"desired_width": 15,
"caption_height":0,
"hAlign": "CENTER",
}
f1 = figureAndCaptionTable(**figure_kwargs)
pdfcomponents = addToDoc([
pdf_title,
small_space
], pdfcomponents)
21. Vergleich der Datenerhebungen seit 2018#
Der erste nationale Uferabfallbericht wurde 2018 erstellt. Der Swiss Litter Report (SLR) war ein Projekt, das von Gabriele Kuhl [Kuh] initiiert und vom World Wildlife Fund Schweiz [Fun] unterstützt wurde. Das Protokoll basierte auf dem Leitfaden für die Überwachung von Meeresmüll [Han13], das Projekt wurde vom WWF geleitet und die Erhebungen wurden von Freiwilligen beider Organisationen durchgeführt. Das Projekt begann im April 2017 und endete im März 2018. Der SLR deckte einen Grossteil der Landesfläche ab, jedoch nicht das Tessin.
Der SLR sammelte 1052 Proben an 112 Orten. Mehr als 150 geschulte Freiwillige aus 81 Gemeinden sammelten und kategorisierten 98 474 Abfälle an den Ufern von 48 Seen und 67 Fliessgewässern in der Schweiz. [Bla18]
Die naheliegendste Frage ist: Wurde 2021 mehr oder weniger Abfall beobachtet als 2018? Zur Beantwortung dieser Frage wurden zunächst die Erhebungsorte der einzelnen Projekte auf der Grundlage des Landnutzungsprofils im Umkreis von 1500 m von jedem Erhebungsorte für jedes Projekt verglichen. Die Erhebungsergebnisse waren beschränkt auf:
Es wurden nur Objekte berücksichtigt, die im Jahr 2018 identifiziert wurden.
Aus dieser Untergruppe von Daten wurden der Median der Gesamtzahl aller Objekte und die durchschnittliche Gesamtzahl der häufigsten Objekte verglichen, um statistisch signifikante Veränderungen in beide Richtungen von einem Projekt zum nächsten zu ermitteln. Dieser Test wurde für zwei Gruppen der Teilmenge durchgeführt:
Seen und Fliessgewässer kombiniert mit Proben aus beiden Projekten
Nur Seen mit Proben aus beiden Projekten
21.1. Umfang der Projekte SLR und IQAASL#
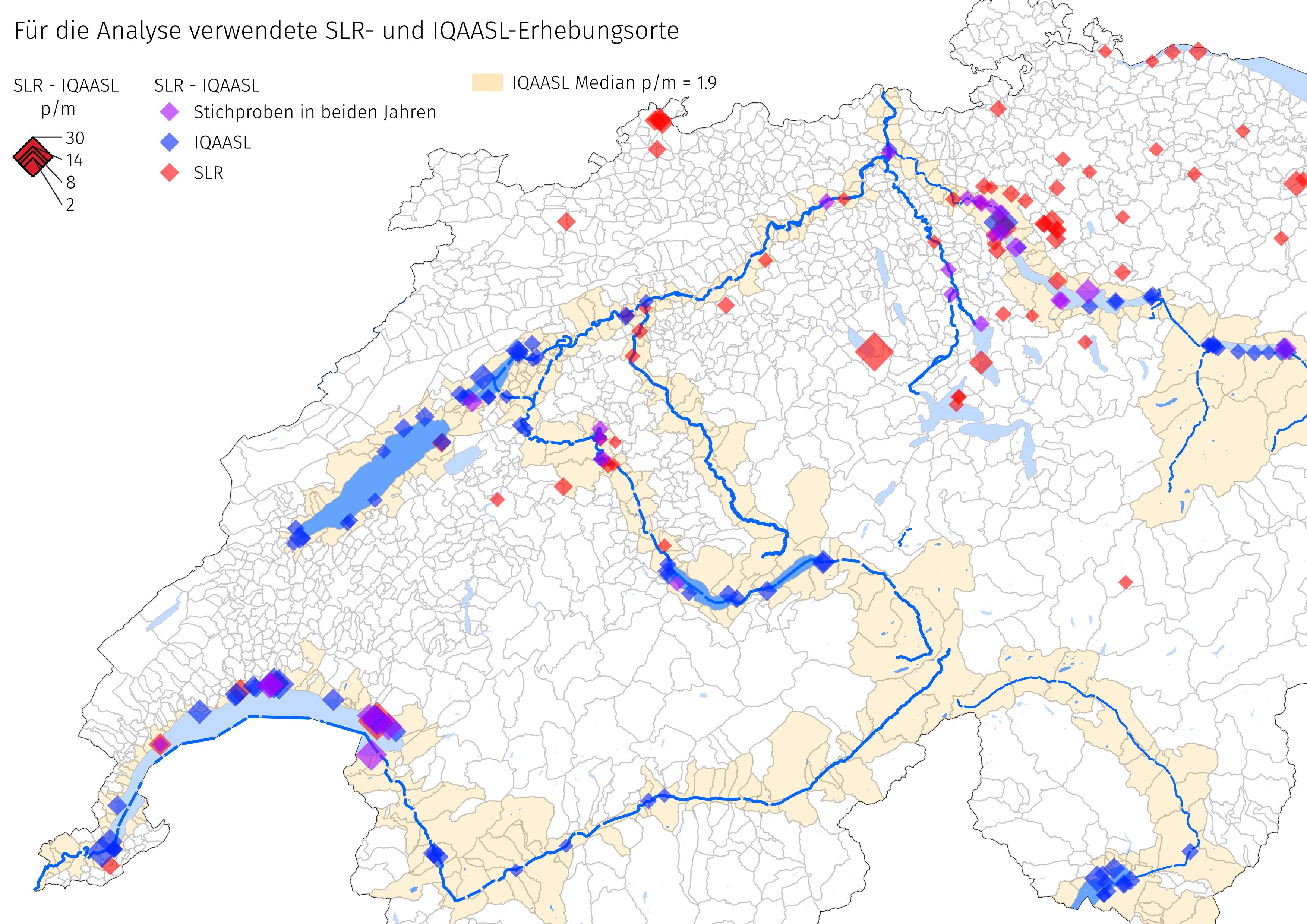
Abb. 21.1 #
Abbildung 21.1: Für die Analyse verwendete SLR- und IQAASL-Erhebungsorte
Show code cell source
# make sure date is time stamp
survey_data["date"] = pd.to_datetime(survey_data["date"], format="%Y-%m-%d")
# get only the water features that were sampled in 2021
after_2020 = survey_data[survey_data["date"] >= "2020-01-01"].water_name_slug.unique()
a_data = survey_data[survey_data.water_name_slug.isin(after_2020)].copy()
# convert pcs-m to unit_value
a_data["pcs_m"] = (a_data.pcs_m * unit_value).astype("int")
a_data.rename(columns={"pcs_m":unit_label}, inplace=True)
# the date ranges of two projects
first_date_range = (a_data.date >= "2017-04-01")&(a_data.date <= "2018-03-31")
second_date_range = (a_data.date >= "2020-04-01")&(a_data.date <= "2021-03-31")
# a df for each set
slr_data = a_data[first_date_range].copy()
iqasl_data = a_data[second_date_range].copy()
# only use codes identified in the first project
these_codes = slr_data[slr_data.quantity > 0].code.unique()
# add a survey year column to each data set
iqasl_data["survey year"] = "IQAASL"
slr_data["survey year"] = "SLR"
# put the two sets of data back together
combined_data = pd.concat([iqasl_data, slr_data])
combined_data["length"] = (combined_data.quantity/combined_data[unit_label])*unit_value
# unique locations in both years
sdlocs = slr_data.location.unique()
iqs = iqasl_data.location.unique()
# locations common to both
both_years = list(set(sdlocs).intersection(iqs))
# locations specific to each year
just_2017 = [x for x in sdlocs if x not in iqs]
j_2021 = [x for x in iqs if x not in sdlocs]
# use only the codes identified in 2017, the protocol only called for certain MLW codes
df = combined_data[combined_data.code.isin(these_codes)].copy()
# scale the streets value
df["streets km"] = (df.streets/1000).round(1)
21.1.1. Landnutzungsprofil der Erhebungsorte#
Das Landnutzungsprofil sind die messbaren Eigenschaften, die geolokalisiert sind und aus den aktuellen Versionen der Arealstatistik der Schweiz [Con21a] und swissTLMRegio [Con21b]. extrahiert werden können. Das Landnutzungsprofil ist eine Schätzung der Art und des Umfangs der wirtschaftlichen Aktivität in der Nähe der Erhebungsorte. Die folgenden Werte wurden in einem Radius von 1500 m um jeden Erhebungsort berechnet:
Fläche, die von Gebäuden eingenommen wird in %
Fläche, die dem Wald vorbehalten ist in %
Fläche, die für Aktivitäten im Freien genutzt wird in %
Fläche, die von der Landwirtschaft genutzt wird in %
Strassen in Gesamtzahl der Strassenkilometer
Anzahl Flussmündungen
Mit Stand vom 22. Juni 2021 waren die Landnutzungsdaten für Walensee nicht mehr aktuell. Walensee wurde geschätzt, indem die relevanten Kartenebenen visuell inspiziert und die Landnutzungsdaten mit denen anderer Orte mit ähnlicher Bevölkerungszahl verglichen wurden. Für Einzelheiten zu dieser Berechnung und warum sie wichtig ist, siehe Landnutzungsprofil.
Show code cell source
# !!walensee landuse is approximated by comparing the land use profile from similar locations!!
# the classification for that part of switzerland is incomplete for the current estimates
# the land use profile of wychely - brienzersee was used for walenstadt-wyss (more prairie, buildings less woods)
# the land use profile of grand-clos - lac-leman was used for other locations on walensee (more woods, less buildings, less praire and agg)
luse_wstdt = dfBeaches.loc["wycheley"][["population","% to buildings", "% to trans", "% to recreation", "% to agg", "% to woods"]]
estimate_luse = dfBeaches.loc["grand-clos"][["population","% to buildings", "% to trans", "% to recreation", "% to agg", "% to woods"]]
lu = featuredata.luse_de
# seperate out the locations that aren"t walenstadt
wlsnsee_locs_not_wstdt = ["gasi-strand", "untertenzen", "mols-rocks", "seeflechsen", "seemuhlestrasse-strand", "muhlehorn-dorf", "murg-bad", "flibach-river-right-bank"]
for a_param in estimate_luse.index:
df.loc[df.location.isin(wlsnsee_locs_not_wstdt), a_param] = estimate_luse[a_param]
df.loc["walensee_walenstadt_wysse", a_param] = luse_wstdt[a_param]
dfdt = df.groupby(use_these_cols[:-2], as_index=False).agg(agg_pcs_quantity)
# chart the distribtuion of survey results with respect to the land use profile
fig, axs = plt.subplots(2, 3, figsize=(9,8), sharey="row")
data=dfdt[(dfdt["survey year"] == "SLR")].groupby(use_these_cols[:-2], as_index=False).agg({"p/100 m":"sum", "quantity":"sum"})
data2=dfdt[(dfdt["survey year"] == "IQAASL")].groupby(use_these_cols[:-2], as_index=False).agg({"p/100 m":"sum", "quantity":"sum"})
for i, n in enumerate(luse_exp):
r = i%2
c = i%3
ax=axs[r,c]
# land use data for each project
the_data = ECDF(data[n].values)
the_data2 = ECDF(data2[n].values)
# the median value
the_median = np.median(data[n].values)
median_two = np.median(data2[n].values)
# plot the curves
sns.lineplot(x= the_data.x, y=the_data.y, ax=ax, color=this_palette[ "SLR"], label="SLR")
sns.lineplot(x=the_data2.x, y=the_data2.y, ax=ax, color=this_palette["IQAASL"], label="IQAASL")
# plot the median and drop horzontal and vertical lines
ax.scatter([the_median], 0.5, color=this_palette[ "SLR"],s=50, linewidth=2, zorder=100, label="Median SLR")
ax.vlines(x=the_median, ymin=0, ymax=0.5, color=this_palette[ "SLR"], linewidth=1)
ax.hlines(xmax=the_median, xmin=0, y=0.5, color=this_palette[ "SLR"], linewidth=1)
# plot the median and drop horzontal and vertical lines
ax.scatter([median_two], 0.5, color=this_palette["IQAASL"],s=50, linewidth=2, zorder=100, label="Median IQAASL")
ax.vlines(x=median_two, ymin=0, ymax=0.5, color=this_palette["IQAASL"], linewidth=1)
ax.hlines(xmax=median_two, xmin=0, y=0.5, color=this_palette["IQAASL"], linewidth=1)
if i <= 3:
if c == 0:
ax.yaxis.set_major_locator(MultipleLocator(.1))
ax.xaxis.set_major_formatter(ticker.PercentFormatter(1.0, 0, "%"))
else:
pass
handles, labels = ax.get_legend_handles_labels()
ax.get_legend().remove()
ax.set_title(featuredata.luse_de[n], loc='left')
handles, labels=ax.get_legend_handles_labels()
plt.tight_layout()
plt.subplots_adjust(top=.91, hspace=.4)
plt.suptitle("Landnutzung im Umkreis von 1500 m um den Erhebungsort", ha="center", y=1, fontsize=16)
fig.legend(handles, labels, bbox_to_anchor=(.5,.5), loc="upper center", ncol=4)
figure_caption = "Verteilung der Anzahl der Erhebungen in Bezug auf das Landnutzungsprofil SLR und IQAASL"
figure_name = "slr_iqaasl_land_use"
land_use_file_name = f'{save_fig_prefix}{figure_name}.jpeg'
save_figure_kwargs.update({"fname":land_use_file_name})
plt.savefig(**save_figure_kwargs)
# capture the output
glue(figure_name, fig, display=False)
glue(f"{figure_name}_caption", figure_caption, display=False)
plt.close()
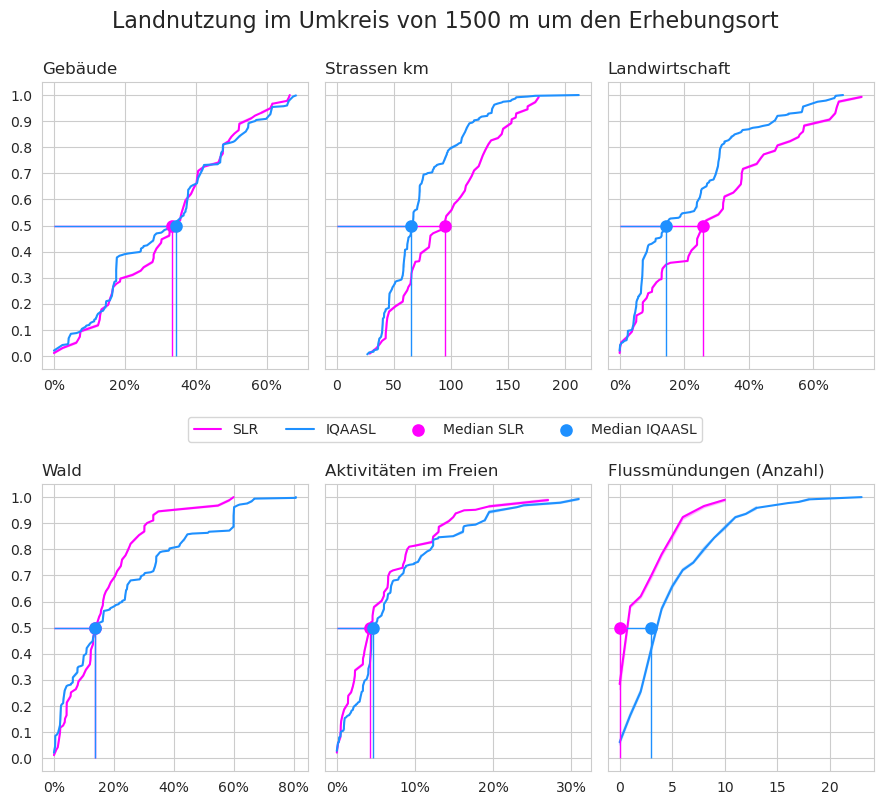
Abb. 21.2 #
Abbildung 21.2: Verteilung der Anzahl der Erhebungen in Bezug auf das Landnutzungsprofil SLR und IQAASL
Die Stichprobenorte im SLR hatten einen grösseren Anteil an landwirtschaftlich genutzter Fläche und ein dichteres Strassennetz als die Orte in IQAASL. Der prozentuale Anteil der Wälder an der Gesamtfläche weicht bei Werten, die oberhalb des Medians ab. Ab diesem Punkt haben die Orte in IQAASL einen grösseren Anteil an Wäldern im Vergleich zum SLR.
Die Einwohnerzahl (nicht gezeigt) stammt aus der Statistik der Bevölkerung und der Haushalte 2018 [Con]. Die kleinste Einwohnerzahl betrug 442 und die grösste 415 357. Mindestens 50 % der Stichproben stammten aus Gemeinden mit einer Einwohnerzahl von 13 000 oder weniger.
Wenn der prozentuale Anteil der Landwirtschaft an der Landnutzung ein Zeichen für Verstädterung ist, dann waren die untersuchten Gebiete im Jahr 2021 etwas städtischer als 2018.
21.2. Ergebnisse Seen und Fliessgewässer#
Betrachtet man nur die Seen und Flüsse, die in beiden Jahren Proben aufweisen, so wurden 2018 mehr Proben und Müll an weniger Orten gesammelt als 2021. Auf der Basis von Stücken pro Meter war der Median im Jahr 2021 jedoch grösser.
21.2.1. Verteilung der Ergebnisse 2018 und 2021#
Show code cell source
# group by survey and sum all the objects for each survey AKA: survey total
data=df.groupby(["survey year","water_name_slug","loc_date", "location", "date"], as_index=False)[unit_label].sum()
data["lakes"] = data.water_name_slug.isin(these_lakes)
# get the ecdf for both projects
ecdf_2017 = ECDF(data[data["survey year"] == "SLR"][unit_label].values)
ecdf_2021 = ECDF(data[data["survey year"] == "IQAASL"][unit_label].values)
# get the ecddf for the condition lakes in both years
l2017 = data[(data.water_name_slug.isin(these_lakes))&(data["survey year"] == "SLR")].copy()
l2021 = data[(data.water_name_slug.isin(these_lakes))&(data["survey year"] == "IQAASL")].copy()
ecdf_2017l = ECDF(l2017[unit_label].values)
ecdf_2021l = ECDF(l2021[unit_label].values)
# group by survey year and use pd.describe to get basic stats
som_1720 = data.groupby("survey year")[unit_label].describe().round(2)
# add total quantity and number of unique locations
som_1720["total objects"] = som_1720.index.map(lambda x: df[df["survey year"] == x].quantity.sum())
som_1720["# locations"] = som_1720.index.map(lambda x: df[df["survey year"] == x].location.nunique())
# make columns names more descriptive
som_1720.rename(columns=(featuredata.createSummaryTableIndex(unit_label, language="de")), inplace=True)
ab = som_1720.reset_index()
# melt that on survey year
c_s = ab.melt(id_vars=["survey year"])
# pivot on survey year
combined_summary = c_s.pivot(columns="variable", index="survey year")
# change the index to date
data.set_index("date", inplace=True)
# get the median monthly value
monthly_2017 = data.loc[data["survey year"] == "SLR"]["p/100 m"].resample("M").median()
# change the date to the name of the month for charting
months_2017 = pd.DataFrame({"month":[dt.datetime.strftime(x, "%b") for x in monthly_2017.index], unit_label:monthly_2017.values})
# repeat for 2021
monthly_2021 = data.loc[data["survey year"] == "IQAASL"]["p/100 m"].resample("M").median()
months_2021 = pd.DataFrame({"month":[dt.datetime.strftime(x, "%b") for x in monthly_2021.index], unit_label:monthly_2021.values})
# set the date intervals for the chart
months = mdates.MonthLocator(interval=1)
months_fmt = mdates.DateFormatter("%b")
years = mdates.YearLocator()
# set a y limit axis:
the_90th = np.percentile(data["p/100 m"], 95)
# chart that
fig, ax = plt.subplots(2,2, figsize=(14,9), sharey=False)
# set axs and lables
axone=ax[0,0]
axtwo = ax[0,1]
axthree = ax[1,0]
axfour = ax[1,1]
axone.set_ylabel(unit_label, **featuredata.xlab_k14)
axone.xaxis.set_minor_locator(months)
axone.xaxis.set_major_locator(years)
axone.set_xlabel(" ")
axtwo.set_xlabel(" ")
axtwo.set_ylabel(unit_label, **featuredata.xlab_k14)
axtwo.set_ylim(-10, the_90th)
axthree.set_ylabel("# der Erhebungen", **featuredata.xlab_k14)
axthree.set_xlabel(unit_label, **ck.xlab_k)
axfour.set_ylabel("% der Erhebungen", **featuredata.xlab_k14)
axfour.set_xlabel(unit_label, **ck.xlab_k)
# histogram data:
data_long = pd.melt(data[["survey year", "loc_date", unit_label]],id_vars=["survey year","loc_date"], value_vars=(unit_label,), value_name="survey total")
data_long["year_bin"] = np.where(data_long["survey year"] == "SLR", 0, 1)
# scatter plot of surveys both years
sns.scatterplot(data=data, x="date", y="p/100 m", color="red", s=10, ec="black", hue="survey year", palette=this_palette, ax=axone)
axone.legend(loc="upper center", title="Gesamtergebnis Erhebung")
# monthly median
sns.lineplot(data=months_2017, x="month", y=unit_label, color=this_palette[ "SLR"], label= "SLR", ax=axtwo)
sns.lineplot(data=months_2021, x="month", y=unit_label, color=this_palette["IQAASL"], label="IQAASL", ax=axtwo)
axtwo.legend(title="Monatlicher Median")
# histogram
axthree = sns.histplot(data=data_long, x="survey total", hue="survey year", stat="count", multiple="stack",palette=this_palette, ax=axthree, bins=[x*20 for x in np.arange(80)])
axthree_legend = axthree.get_legend()
axthree_legend.set_title("Erhebungsjahr")
# empirical cumulative distribution
sns.lineplot(x=ecdf_2017.x, y=ecdf_2017.y, ax=axfour, color=this_palette[ "SLR"], label= "SLR")
sns.lineplot(x=ecdf_2021.x, y=ecdf_2021.y, ax=axfour, color=this_palette["IQAASL"], label="IQAASL")
axfour.xaxis.set_major_locator(ticker.MultipleLocator(1000))
axfour.xaxis.set_minor_locator(ticker.MultipleLocator(100))
axfour.legend(loc="center right")
axfour.tick_params(which="both", bottom=True)
axfour.grid(visible=True, which="minor",linewidth=0.5)
f3caption = [
"<b>Oben links:</b> Gesamtwerte der Erhebungen nach Datum. <b>Oben rechts:</b> Median der monatlichen Gesamtzahl der Erhebungen. ",
"<b>Unten links</b>: Anzahl der Stichproben in Bezug auf die Gesamtzahl der Erhebungen. <b>Unten rechts:</b> empirische Verteilungsfunktion ",
"der Gesamtzahlen der Erhebungen."
]
figure_name = "slr_iqaasl_surveys"
figure_file_name = f'{save_fig_prefix}{figure_name}.jpeg'
save_figure_kwargs.update({"fname":figure_file_name})
plt.subplots_adjust(left=0, bottom=0 )
# plt.tight_layout(pad=.1)
plt.savefig(**save_figure_kwargs)
# capture the output
glue(figure_name, fig, display=False)
plt.close()
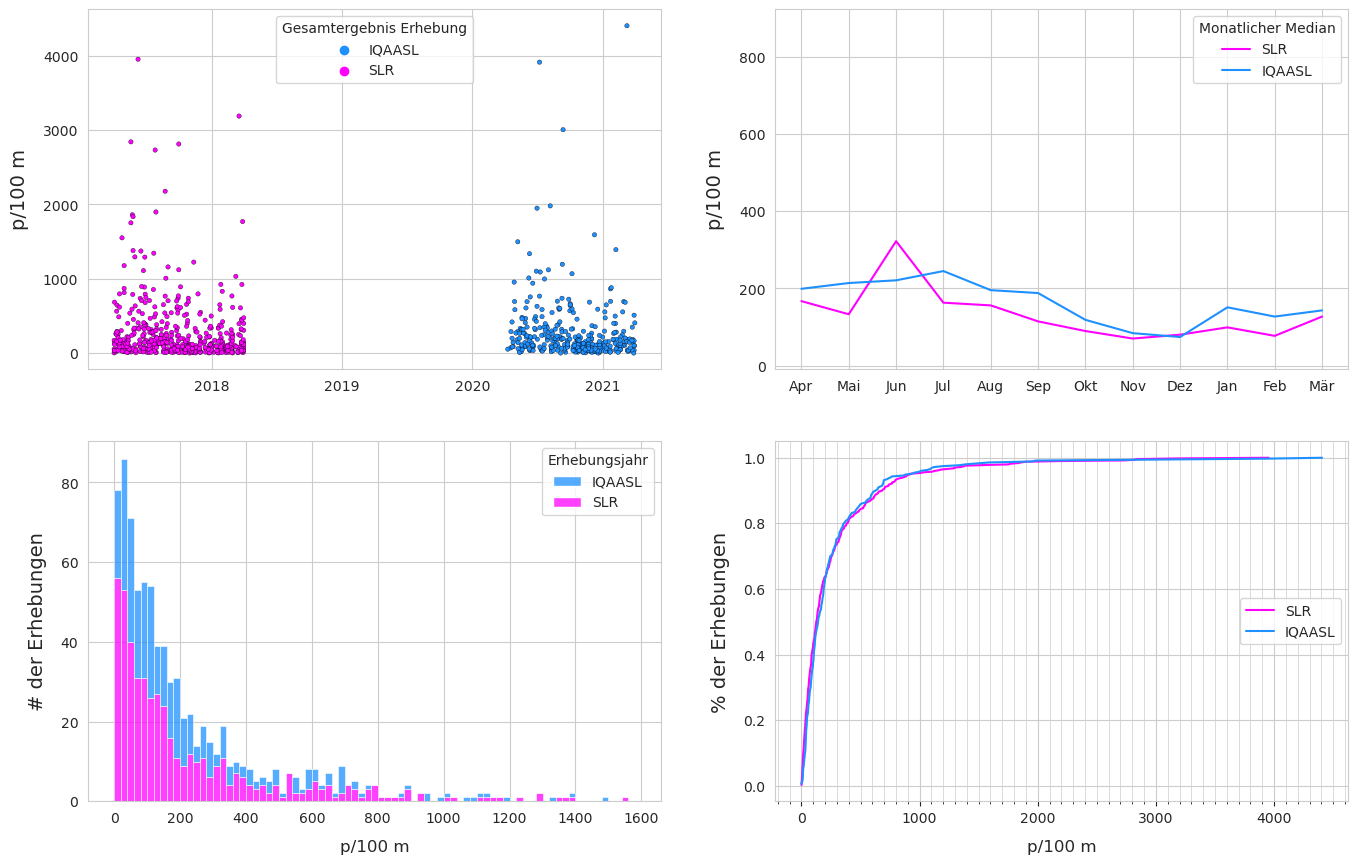
Abb. 21.3 #
Abbildung 21.3: Oben links: Gesamtwerte der Erhebungen nach Datum. Oben rechts: Median der monatlichen Gesamtzahl der Erhebungen. Unten links: Anzahl der Stichproben in Bezug auf die Gesamtzahl der Erhebungen. Unten rechts: empirische Verteilungsfunktion der Gesamtzahlen der Erhebungen.
21.2.2. Zusammenfassende Daten und Materialarten 2018 und 2021#
Show code cell source
#### format for printing
# pivot on survey year
combined_summary = c_s.pivot(columns="variable", index="survey year")
combined_summary.columns = combined_summary.columns.get_level_values(1)
col_rder = ['Anzahl der Standorte',
'Durchschnitt p/100 m',
'Standardabweichung',
'min p/100 m',
'25%',
'50%',
'75%',
'max p/100 m',
'Abfallobjekte'
]
cy = combined_summary[col_rder]
c = cy.T.reset_index()
c[[ "SLR", "IQAASL"]] = c[[ "SLR", "IQAASL"]].astype("int")
c[[ "SLR", "IQAASL"]] = c[[ "SLR", "IQAASL"]].applymap(lambda x: f"{featuredata.thousandsSeparator(int(x))}")
# material totals
mat_total = df.groupby(["survey year", "code"], as_index=False).quantity.sum()
# add material type:
mat_total["mat"] = mat_total.code.map(lambda x:code_material_map.loc[x])
# the cumulative sum of material by category
mat_total = mat_total.groupby(["survey year", "mat"], as_index=False).quantity.sum()
# get the % of total and fail rate for each object from each year
# add the yearly total column
mat_total.loc[mat_total["survey year"] == "SLR", "yt"] = mat_total[mat_total["survey year"] == "SLR"].quantity.sum()
mat_total.loc[mat_total["survey year"] == "IQAASL", "yt"] = mat_total[mat_total["survey year"] == "IQAASL"].quantity.sum()
# get % of total
mat_total["pt"] =((mat_total.quantity/mat_total.yt)*100).round(2)
# format for printing:
mat_total["pt"] = mat_total.pt.map(lambda x: F"{featuredata.replaceDecimal(x)}%")
mat_total["quantity"] = mat_total.quantity.map(lambda x: f"{featuredata.thousandsSeparator(int(x))}")
# pivot and rename columns
m_t = mat_total[["survey year","mat", "quantity", "pt"]].pivot(columns="survey year", index="mat", values="pt").reset_index()
m_t.rename(columns={"mat":"material", "pt":"% of total"}, inplace=True)
fig = plt.figure(figsize=(7,5))
gs = GridSpec(10, 7, figure=fig)
axone = fig.add_subplot(gs[:, 0:4])
axtwo= fig.add_subplot(gs[:,4:])
# convenience func
sut.hide_spines_ticks_grids(axone)
sut.hide_spines_ticks_grids(axtwo)
# summary data table
a_table = sut.make_a_table(axone, c.values, colLabels=c.columns, colWidths=[.5,.25,.25], loc="lower center", bbox=[0,0,1,1])
a_table.get_celld()[(0,0)].get_text().set_text(" ")
# material totals
second_table = sut.make_a_table(axtwo, m_t.values, colLabels=m_t.columns, colWidths=[.5,.25,.25], loc="lower center", bbox=[0,0,1,1])
second_table.get_celld()[(0,0)].get_text().set_text(" ")
plt.tight_layout()
f4caption = [
"<b>Links:</b> Zusammenfassung der Gesamtzahlen der Erhebung. <b>Rechts:</b> Materialarten. ",
"Bei den Chemikalien handelt es sich hauptsächlich um Paraffin und beim Holz um verarbeitetes Holz. "
]
figure_name = "slr_iqaasl_summary_tables"
figure_file_name = f'{save_fig_prefix}{figure_name}.jpeg'
save_figure_kwargs.update({"fname":figure_file_name})
plt.savefig(**save_figure_kwargs)
# capture the output
glue(figure_name, fig, display=False)
plt.close()
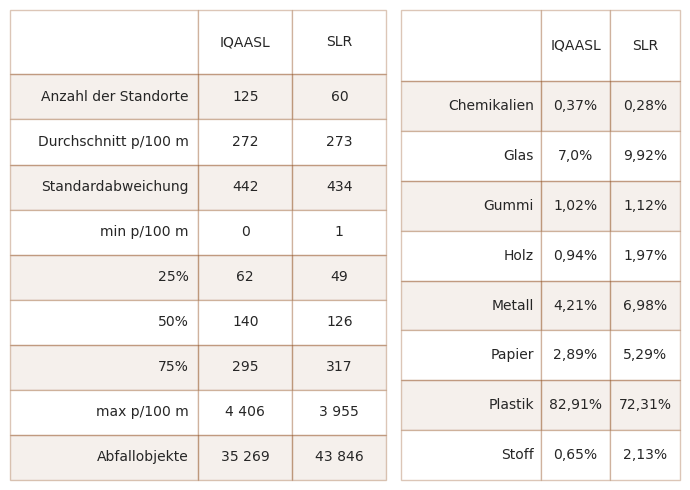
Abb. 21.4 #
Abbildung 21.4: Links: Zusammenfassung der Gesamtzahlen der Erhebung. Rechts: Materialarten. Bei den Chemikalien handelt es sich hauptsächlich um Paraffin und beim Holz um verarbeitetes Holz.
21.2.2.1. Differenz der Mediane zwischen 2018 und 2021#
Der beobachtete Unterschied der Mediane zwischen den beiden Projekten beträgt 14 p/100 m. Unterschiede dieser Grössenordnung könnten auf Zufall zurückzuführen sein. Um die Hypothese zu testen, wurde ein Permutationstest durchgeführt:
Nullhypothese: Der Median des Erhebungsergebnisses von 2018 unterscheidet sich statistisch nicht vom Median 2021 und der beobachtete Unterschied ist auf Zufall zurückzuführen.
Alternativhypothese: Der Median des Erhebungsergebnisses von 2018 unterscheidet sich statistisch vom Median 2021 und der beobachtete Unterschied ist nicht zufällig.
Show code cell source
# data for testing
data=df.copy()
# get the survey total for each survey keep the survey year column
pre_shuffle = data.groupby(["loc_date", "survey year"], as_index=False)[unit_label].sum()
# get the median from each year
observed_median = pre_shuffle.groupby("survey year")[unit_label].median()
# get the dif mu_2021 - mu_2017
observed_dif = observed_median.loc["IQAASL"] - observed_median.loc[ "SLR"]
# a place to store the sample statistics
new_medians=[]
# resampling:
for element in np.arange(5000):
# shuffle the entire survey year column
pre_shuffle["new_class"] = pre_shuffle["survey year"].sample(frac=1, replace=True).values
# get the median for both "survey years"
b=pre_shuffle.groupby("new_class")['p/100 m'].median()
# get the change and store it
new_medians.append((b.loc[ "SLR"] - b.loc["IQAASL"]))
# calculate the empirical p
emp_p = np.count_nonzero(new_medians <= observed_dif )/ 5000
# chart the results
fig, ax = plt.subplots()
sns.histplot(new_medians, ax=ax)
ax.set_title(F"$\u0394\mu$ = {np.round(observed_dif, 2)}, perm=5000, p={emp_p} ", **ck.title_k14)
ax.set_ylabel("Permutationen", **featuredata.xlab_k14)
ax.set_xlabel("$\mu$ 2021 - $\mu$ 2018", **featuredata.xlab_k14)
f5caption = [
"Die Verteilung der Differenz der Mediane 2018 und 2021. Die Erhebungsergebnisse wurden gemischt und ",
"in der Spalte des Erhebungsjahres 5 000 Mal als Stichprobe gezogen. Die Nullhypothese kann nicht verworfen ",
"werden, was das Argument stützt, dass die Medianwerte der Erhebungsergebnisse von Jahr zu Jahr ungefähr gleich sind."
]
figure_name = "slr_iqaasl_dif_median"
figure_file_name = f'{save_fig_prefix}{figure_name}.jpeg'
save_figure_kwargs.update({"fname":figure_file_name})
plt.savefig(**save_figure_kwargs)
# capture the output
glue(figure_name, fig, display=False)
plt.close()
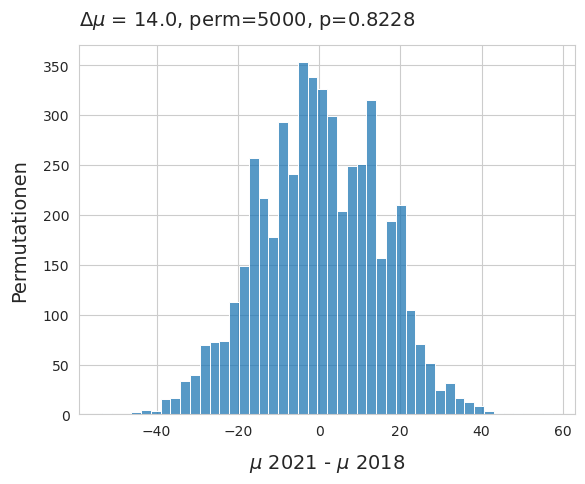
Abb. 21.5 #
Abbildung 21.5: Die Verteilung der Differenz der Mediane 2018 und 2021. Die Erhebungsergebnisse wurden gemischt und in der Spalte des Erhebungsjahres 5 000 Mal als Stichprobe gezogen. Die Nullhypothese kann nicht verworfen werden, was das Argument stützt, dass die Medianwerte der Erhebungsergebnisse von Jahr zu Jahr ungefähr gleich sind.
21.2.3. Die am häufigsten gefundenen Objekte#
Die häufigsten Objekte sind die zehn mengenmässig am häufigsten vorkommenden Objekte und/oder Objekte, die in mindestens 50 % aller Erhebungen identifiziert wurden. Das sind 60–80 % aller Objekte, die in einem bestimmten Erhebungszeitraum identifiziert wurden. Die am häufigsten vorkommenden Objekte 2018 und 2021 sind nicht identisch. Um die Veränderungen zu bewerten, werden nur diejenigen Objekte berücksichtigt, die in beiden Jahren am häufigsten vorkamen.
Show code cell source
# code totals by project
c_totals = df.groupby(["survey year", "code"], as_index=False).agg({"quantity":"sum", "fail":"sum", unit_label:"median"})
# calculate the fail rate % of total for each code and survey year
for a_year in [ "SLR", "IQAASL"]:
c_totals.loc[c_totals["survey year"] == a_year, "fail rate"] = ((c_totals.fail/df[df["survey year"] == a_year].loc_date.nunique())*100).astype("int")
c_totals.loc[c_totals["survey year"] == a_year, "% of total"] = ((c_totals.quantity/df[df["survey year"] == a_year].quantity.sum())*100).astype("int")
# get all the instances where the fail rate is > fail_rate
c_50 = c_totals.loc[c_totals["fail rate"] >= fail_rate]
# the top ten from each project
ten_2017 = c_totals[c_totals["survey year"] == "SLR"].sort_values(by="quantity", ascending=False)[:10].code.unique()
ten_2021 = c_totals[c_totals["survey year"] == "IQAASL"].sort_values(by="quantity", ascending=False)[:10].code.unique()
# combine the most common from each year with the top ten from each year
# most common 2017
mcom_2017 = list(set(c_50[c_50["survey year"]== "SLR"].code.unique())|set(ten_2017))
# most common 2021
mcom_2021 = list(set(c_50[c_50["survey year"]=="IQAASL"].code.unique())|set(ten_2021))
# the set of objects that were the most common in both years:
mcom = list(set(mcom_2017)&set(mcom_2021))
# get the data
com_2017 = c_totals[(c_totals["survey year"] == "SLR")&(c_totals.code.isin(mcom))].copy()
com_2021 = c_totals[(c_totals["survey year"] == "IQAASL")&(c_totals.code.isin(mcom))]
# format values for table
table_data = []
chart_labels = [ "SLR", "IQAASL"]
for i, som_data in enumerate([com_2017, com_2021]):
som_data = som_data.set_index("code")
som_data.sort_values(by="quantity", ascending=False, inplace=True)
som_data["item"] = som_data.index.map(lambda x: code_description_map.loc[x])
som_data["% of total"] = som_data["% of total"].map(lambda x: F"{int(x)}%")
som_data["quantity"] = som_data.quantity.map(lambda x: featuredata.thousandsSeparator(x, "de"))
som_data["fail rate"] = som_data["fail rate"].map(lambda x: F"{int(x)}%")
som_data[unit_label] = som_data[unit_label].map(lambda x: featuredata.replaceDecimal(x, "de"))
table_data.append({chart_labels[i]:som_data})
# the columns needed
cols_to_use = {"item":"Objekte","quantity":"Total (St.)", "% of total":"Total (%)", "fail rate":"Häufigkeitsrate", unit_label:unit_label}
table_formatter = {
# "p/100 m": lambda x: featuredata.replaceDecimal(x, "de"),
# "Total (St.)": lambda x: featuredata.thousandsSeparator(int(x), "de")
}
com_2017 = table_data[0][ "SLR"]
com_2017.rename(columns=cols_to_use, inplace=True)
# com_2017["Objekte"] = com_2017.code.map(lambda x: code_description_map.loc[x])
com_2017 = com_2017[["Objekte", "Total (St.)", "Total (%)", "Häufigkeitsrate", "p/100 m"]]
com_2017.set_index("Objekte", inplace=True)
com_2017.index.name = None
com_2017x = com_2017.style.set_table_styles(table_css_styles)
com_2021 = table_data[1]["IQAASL"]
com_2021.rename(columns=cols_to_use, inplace=True)
# com_2017["Objekte"] = com_2017.code.map(lambda x: code_description_map.loc[x])
com_2021 = com_2021[["Objekte", "Total (St.)", "Total (%)", "Häufigkeitsrate", "p/100 m"]]
com_2021.set_index("Objekte", inplace=True)
com_2021.index.name = None
com_2021x = com_2021.style.set_table_styles(table_css_styles)
col_widths = [5*cm, 2.2*cm, 2*cm, 2.8*cm, 2*cm]
# pdf components
f6_chart = featuredata.aSingleStyledTable(com_2017, colWidths=col_widths)
f7_chart = featuredata.aSingleStyledTable(com_2021, colWidths=col_widths)
f6_caption = Paragraph("Häufigste Objekte SLR", featuredata.caption_style)
f7_caption = Paragraph("Häufigste Objekte IQAASL", featuredata.caption_style)
f6 = featuredata.tableAndCaption(f6_chart, f6_caption, col_widths)
f7 = featuredata.tableAndCaption(f7_chart, f7_caption, col_widths)
figure_name="2017_table"
glue(figure_name, com_2017x, display=False)
figure_name="2021_table"
glue(figure_name, com_2021x, display=False)
| Total (St.) | Total (%) | Häufigkeitsrate | p/100 m | |
|---|---|---|---|---|
| Zigarettenfilter | 13 174.0 | 30% | 76% | 14,0 |
| Objekte aus Kunststoff 2,5 - 50 cm | 3 349.0 | 7% | 64% | 6,0 |
| Snack-Verpackungen | 2 715.0 | 6% | 60% | 4,0 |
| Industriefolie (Kunststoff) | 2 069.0 | 4% | 40% | 0,0 |
| Expandiertem Polystyrol 2,5 - 50 cm | 1 699.0 | 3% | 39% | 0,0 |
| Flaschenverschlüsse aus Metall | 1 255.0 | 2% | 42% | 0,0 |
| Wattestäbchen/Tupfer | 1 043.0 | 2% | 14% | 0,0 |
Abb. 21.6 #
Abbildung 21.6: Häufigste Objekte SLR.
| Total (St.) | Total (%) | Häufigkeitsrate | p/100 m | |
|---|---|---|---|---|
| Zigarettenfilter | 7 614.0 | 21% | 87% | 20,0 |
| Snack-Verpackungen | 3 097.0 | 8% | 85% | 9,0 |
| Objekte aus Kunststoff 2,5 - 50 cm | 2 906.0 | 8% | 80% | 7,0 |
| Industriefolie (Kunststoff) | 2 485.0 | 7% | 70% | 5,0 |
| Expandiertem Polystyrol 2,5 - 50 cm | 1 737.0 | 4% | 52% | 1,0 |
| Wattestäbchen/Tupfer | 1 337.0 | 3% | 51% | 1,0 |
| Flaschenverschlüsse aus Metall | 621.0 | 1% | 51% | 1,0 |
Abb. 21.7 #
Abbildung 21.7: Häufigste Objekte IQAASL.
21.3. Ergebnisse Seen 2018 und 2021#
Die folgenden Seen wurden in beiden Projektjahren beprobt:
Zürichsee
Bielersee
Neuenburgersee
Walensee
Genfersee
Thunersee
Bei der Betrachtung der sechs Seen (oben) gab es 2021 mehr Proben und Erhebungsorte und grössere Mengen an gesammeltem Abfall, aber sowohl der Median als auch der Durchschnitt waren im Vergleich zu 2018 niedriger.
Show code cell source
data=lks_df.groupby(["survey year","loc_date", "date"], as_index=False)[unit_label].sum()
data.set_index("date", inplace=True)
# the empirical distributions for each year
ecdf_2017 = ECDF(data[data["survey year"] == "SLR"][unit_label].values)
ecdf_2021 = ECDF(data[data["survey year"] == "IQAASL"][unit_label].values)
# get the x,y vals for each year
ecdf_2017_x, ecdf_2017_y = ecdf_2017.x, ecdf_2017.y
ecdf_2021_x, ecdf_2021_y = ecdf_2021.x, ecdf_2021.y
the_90th = np.percentile(data[unit_label], 95)
# the monthly plots
just_2017 = data[data["survey year"] == "SLR"][unit_label].resample("M").median()
monthly_2017 = pd.DataFrame(just_2017)
monthly_2017.reset_index(inplace=True)
monthly_2017["month"] = monthly_2017.date.map(lambda x: dt.datetime.strftime(x, "%b"))
just_2021 = data[data["survey year"] == "IQAASL"][unit_label].resample("M").median()
monthly_2021 = pd.DataFrame(just_2021)
monthly_2021.reset_index(inplace=True)
monthly_2021["month"] = monthly_2021.date.map(lambda x: dt.datetime.strftime(x, "%b"))
# long form data for histogram
data_long = pd.melt(data[["survey year", "p/100 m"]],id_vars=["survey year"], value_vars=("p/100 m",), value_name="survey total")
data_long["year_bin"] = np.where(data_long["survey year"] == "SLR", 0, 1)
data_long = data_long[data_long["survey total"] < the_90th].copy()
fig, ax = plt.subplots(2,2, figsize=(12,9), sharey=False)
# set axs and labels
axone=ax[0,0]
axtwo = ax[0,1]
axthree = ax[1,0]
axfour = ax[1,1]
axone.set_ylabel("pieces of trash per 100m", **featuredata.xlab_k14)
axone.set_xlabel(" ")
axone.xaxis.set_minor_locator(months)
axone.xaxis.set_major_locator(years)
axtwo.set_xlabel(" ")
axtwo.set_ylabel(unit_label, **featuredata.xlab_k14)
axthree.set_ylabel("# der Erhebungen", **featuredata.xlab_k14)
axthree.set_xlabel(unit_label, **ck.xlab_k)
axtwo.set_ylim(0, the_90th)
axfour.set_ylabel("% der Erhebungen", **featuredata.xlab_k14)
axfour.set_xlabel(unit_label, **ck.xlab_k)
# scatter plot of surveys both years
sns.scatterplot(data=data, x="date", y="p/100 m", color="red", s=10, ec="black", hue="survey year", palette=this_palette, ax=axone)
axone.legend(loc="upper center", title="Gesamtergebnis Erhebung")
# monthly median
sns.lineplot(data=monthly_2017, x="month", y=unit_label, color=this_palette[ "SLR"], label= "SLR", ax=axtwo)
sns.lineplot(data=monthly_2021, x="month", y=unit_label, color=this_palette["IQAASL"], label="IQAASL", ax=axtwo)
axtwo.legend(title="Monatlicher Median")
# histogram of survey results
sns.histplot(data=data_long, x="survey total", hue="survey year", stat="count", multiple="stack", palette=this_palette, ax=axthree)
axthree_legend = axthree.get_legend()
axthree_legend.set_title("Erhebungsjahr")
# ecdfs
sns.lineplot(x=ecdf_2017_x, y=ecdf_2017_y, ax=axfour, color=this_palette[ "SLR"], label= "SLR")
sns.lineplot(x=ecdf_2021_x, y=ecdf_2021_y, ax=axfour, color=this_palette["IQAASL"], label="IQAASL")
axfour.xaxis.set_major_locator(ticker.MultipleLocator(1000))
axfour.xaxis.set_minor_locator(ticker.MultipleLocator(100))
axfour.legend(loc="center right")
axfour.tick_params(which="both", bottom=True)
axfour.grid(visible=True, which="minor",linewidth=0.5)
plt.tight_layout()
f8caption = [
"<b>Oben links:</b> Erhebungssummen nach Datum. <b>Oben rechts:</b> Median der monatlichen Erhebungssumme. <b>Unten links:</b> ",
"Anzahl der Stichproben in Bezug auf die Erhebungssumme. <b>Unten rechts:</b> empirische Verteilungsfunktion der ",
"Erhebungssummen."
]
figure_name = "slr_iqaasl_lake_surveys"
figure_file_name = f'{save_fig_prefix}{figure_name}.jpeg'
save_figure_kwargs.update({"fname":figure_file_name})
plt.savefig(**save_figure_kwargs)
# capture the output
glue(figure_name, fig, display=False)
plt.close()
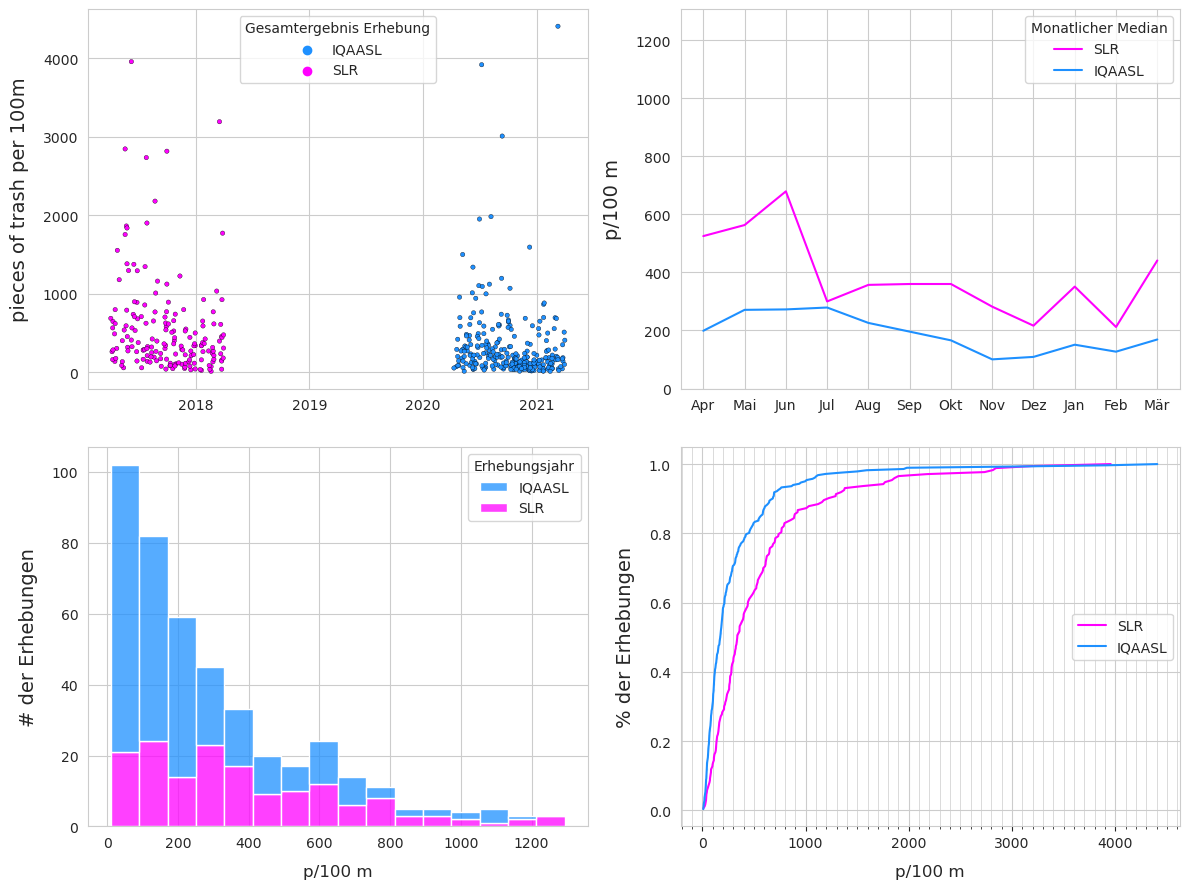
Abb. 21.8 #
Abbildung 21.8: Oben links: Erhebungssummen nach Datum. Oben rechts: Median der monatlichen Erhebungssumme. Unten links: Anzahl der Stichproben in Bezug auf die Erhebungssumme. Unten rechts: empirische Verteilungsfunktion der Erhebungssummen.
Show code cell source
# group by survey year and use pd.describe to get basic stats
som_1720 = lks_dt.groupby("survey year")[unit_label].describe().round(2)
# add total quantity and number of unique locations
som_1720["total objects"] = som_1720.index.map(lambda x: df[df["survey year"] == x].quantity.sum())
som_1720["# locations"] = som_1720.index.map(lambda x: df[df["survey year"] == x].location.nunique())
# make columns names more descriptive
som_1720.rename(columns=(featuredata.createSummaryTableIndex(unit_label, language="de")), inplace=True)
ab = som_1720.reset_index()
# melt that on survey year
c_s = ab.melt(id_vars=["survey year"])
# pivot on survey year
combined_summary = c_s.pivot(columns="variable", index="survey year")
# format for printing
combined_summary.columns = combined_summary.columns.get_level_values(1)
col_rder = ['Anzahl der Standorte',
'Durchschnitt p/100 m',
'Standardabweichung',
'min p/100 m',
'25%',
'50%',
'75%',
'max p/100 m',
'Abfallobjekte'
]
cy = combined_summary[col_rder]
c = cy.T.reset_index()
c[[ "SLR", "IQAASL"]] = c[[ "SLR", "IQAASL"]].astype("int")
c[[ "SLR", "IQAASL"]] = c[[ "SLR", "IQAASL"]].applymap(lambda x: f"{featuredata.thousandsSeparator(int(x))}")
# material totals
mat_total = lks_df.groupby(["survey year", "code"], as_index=False).quantity.sum()
# add material type:
mat_total["mat"] = mat_total.code.map(lambda x:code_material_map.loc[x])
# the most common codes for each year
mat_total = mat_total.groupby(["survey year", "mat"], as_index=False).quantity.sum()
# get the % of total and fail rate for each object from each year
# add the yearly total column
mat_total.loc[mat_total["survey year"] == "SLR", "yt"] = mat_total[mat_total["survey year"] == "SLR"].quantity.sum()
mat_total.loc[mat_total["survey year"] == "IQAASL", "yt"] = mat_total[mat_total["survey year"] == "IQAASL"].quantity.sum()
# get % of total
mat_total["pt"] =((mat_total.quantity/mat_total.yt)*100).round(2)
# format for printing:
mat_total["pt"] = mat_total.pt.map(lambda x: F"{featuredata.replaceDecimal(x)}%")
mat_total["quantity"] = mat_total.quantity.map(lambda x: f"{featuredata.thousandsSeparator(int(x))}")
m_t = mat_total[["survey year","mat", "quantity", "pt"]].pivot(columns="survey year", index="mat", values="pt").reset_index()
m_t.rename(columns={"mat":"material", "pt":"% of total"}, inplace=True)
fig = plt.figure(figsize=(7,5))
gs = GridSpec(10, 7, figure=fig)
axone = fig.add_subplot(gs[:, 0:4])
axtwo= fig.add_subplot(gs[:,4:])
# convenience func
sut.hide_spines_ticks_grids(axone)
sut.hide_spines_ticks_grids(axtwo)
# summary data table
a_table = sut.make_a_table(axone, c.values, colLabels=c.columns, colWidths=[.5,.25,.25], loc="lower center", bbox=[0,0,1,1])
a_table.get_celld()[(0,0)].get_text().set_text(" ")
# material totals
second_table = sut.make_a_table(axtwo, m_t.values, colLabels=m_t.columns, colWidths=[.5,.25,.25], loc="lower center", bbox=[0,0,1,1])
second_table.get_celld()[(0,0)].get_text().set_text(" ")
plt.tight_layout()
f9caption = [
"<b>Links:</b> Zusammenfassung der Gesamterhebung. <b>Rechts:</b> Materialarten."
]
figure_name = "slr_iqaasl_lakes_summary_tables"
figure_file_name = f'{save_fig_prefix}{figure_name}.jpeg'
save_figure_kwargs.update({"fname":figure_file_name})
plt.savefig(**save_figure_kwargs)
# capture the output
glue(figure_name, fig, display=False)
plt.close()
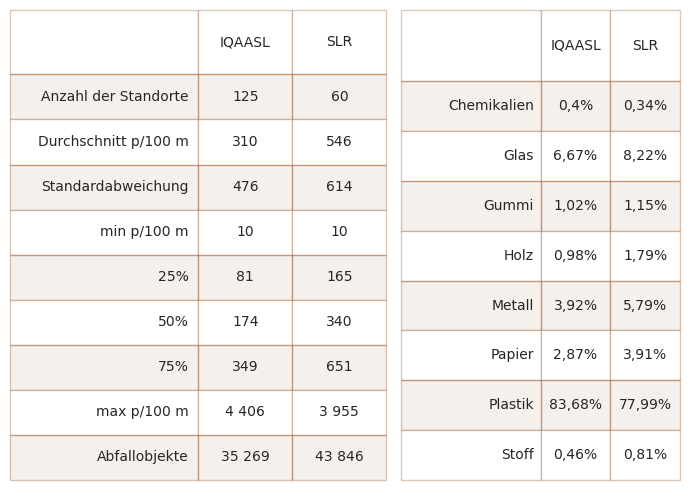
Abb. 21.9 #
Abbildung 21.9: Links: Zusammenfassung der Gesamterhebung. Rechts: Materialarten.
21.3.1. Seen: Die am häufigsten gefundenen Objekte#
Die häufigsten Objekte waren 71 % aller gezählten Objekte im Jahr 2018 gegenüber 60 % im Jahr 2021. Zigarettenfilter und zerbrochene Plastikteile wurden 2018 fast doppelt so häufig gezählt wie 2021.
Seen: Schlüsselindikatoren der häufigsten Abfallobjekte 2018 und 2021
Show code cell source
# compare the key indicators of the most common objects
lks_codes = lks_df[lks_df.code.isin(mcom)].copy()
lks_codes = lks_df[lks_df.code.isin(mcom)].groupby(["code", "survey year"], as_index=False).agg({unit_label:"median", "quantity":"sum", "fail":"sum", "loc_date":"nunique"})
# get fail rate and % of total
for a_year in ["IQAASL", "SLR"]:
lks_codes.loc[lks_codes["survey year"] == a_year, "fail rate"] = lks_codes.fail/lks_df[lks_df["survey year"]==a_year].loc_date.nunique()
lks_codes.loc[lks_codes["survey year"] == a_year, "% of total"] = lks_codes.quantity/lks_df[lks_df["survey year"]==a_year].quantity.sum()
lks_codes["d"] = lks_codes.code.map(lambda x: code_description_map.loc[x])
a = lks_codes.pivot(columns="survey year", values=unit_label, index="d")
b = lks_codes.pivot(columns="survey year", values="fail rate", index="d").astype(float)
c = lks_codes.pivot(columns="survey year", values="% of total", index="d")
# plot that
fig = plt.figure(figsize=(8, 12))
# use gridspec to position
spec = GridSpec(ncols=8, nrows=2, figure=fig)
axone = fig.add_subplot(spec[:,1:3])
axtwo = fig.add_subplot(spec[:,3:5])
axthree = fig.add_subplot(spec[:,5:7])
# get an order to assign each ax
an_order = a.sort_values(by= "SLR", ascending=False).index
# index axtwo and and axthree to axone
axone_data = a.sort_values(by= "SLR", ascending=False)
axtwo_data = b.sort_values(by= "SLR", ascending=False).reindex(an_order)
axthree_data = c.sort_values(by= "SLR", ascending=False).reindex(an_order)
# pieces per meter
sns.heatmap(axone_data, cmap=cmap2, annot=True, annot_kws={"fontsize":12}, ax=axone, square=True, cbar=False, linewidth=.05, linecolor="white")
axone.tick_params(**dict(labeltop=True, labelbottom=True, pad=12, labelsize=12), **ck.no_xticks)
axone.set_xlabel(" ")
axone.set_title("Median p/100 m",loc='center', pad=12, linespacing=1.5, fontsize=12)
# fail rate
sns.heatmap(axtwo_data, cmap=cmap2, annot=True, annot_kws={"fontsize":12}, fmt=".0%", ax=axtwo, square=True, cbar=False, linewidth=.05, linecolor="white")
axtwo.tick_params(**dict(labeltop=True, labelbottom=True, pad=12, labelsize=12), **ck.no_xticks)
axtwo.tick_params(labelleft=False, left=False)
axtwo.set_xlabel(" ")
axtwo.set_title("Häufigkeitsrate",loc='center', pad=12, linespacing=1.5, fontsize=12)
# percent of total
sns.heatmap(axthree_data, cmap=cmap2, annot=True, annot_kws={"fontsize":12}, fmt=".0%", ax=axthree, square=True, cbar=False, linewidth=.05, linecolor="white")
axthree.tick_params(**dict(labeltop=True, labelbottom=True, pad=12, labelsize=12), **ck.no_xticks)
axthree.tick_params(labelleft=False, left=False)
axthree.set_xlabel(" ")
axthree.set_title("Total (%)", loc='center', pad=12, linespacing=1.5, fontsize=12)
for anax in [axone, axtwo, axthree]:
anax.set_ylabel("")
plt.subplots_adjust(wspace=0.4)
f10caption = [
"Seen: Schlüsselindikatoren der häufigsten Abfallobjekte IQAASL und SLR"
]
figure_name = "slr_iqaasl_lakes_most_common"
figure_file_name = f'{save_fig_prefix}{figure_name}.jpeg'
save_figure_kwargs.update({"fname":figure_file_name})
plt.savefig(**save_figure_kwargs)
# capture the output
glue(figure_name, fig, display=False)
plt.close()
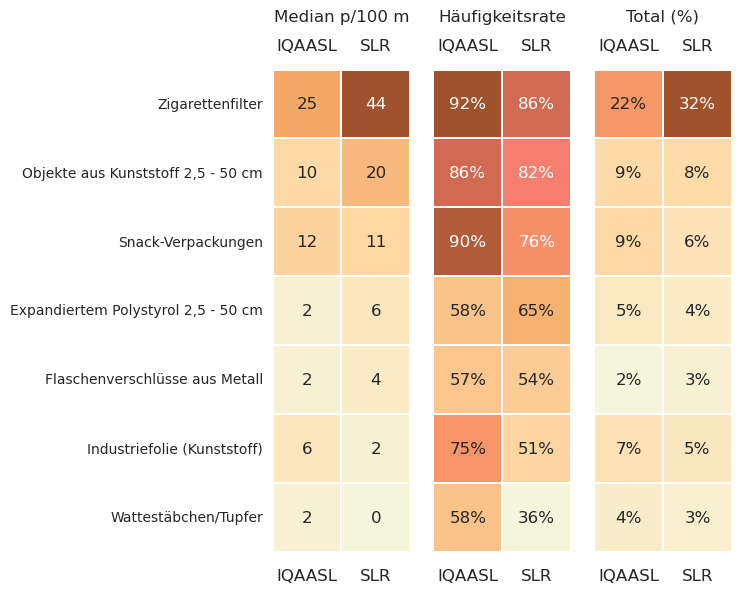
Abb. 21.10 #
Abbildung 21.10: Schlüsselindikatoren der häufigsten Abfallobjekte IQAASL und SLR
21.3.2. Differenz der durchschnittlichen Erhebungssumme#
Bei der Betrachtung nur der Seen ist die Differenz der Mediane umgekehrt, es wurde 2021 weniger Abfall beobachtet als 2018 und die Differenz der Mittelwerte ist viel grösser zugunsten von 2018. Das deutet darauf hin, dass auf der Ebene der Seen ein Rückgang der beobachteten Mengen zu verzeichnen war.
Nullhypothese: Der Mittelwert der Erhebungsergebnisse für die Seen im Jahr 2018 unterscheidet sich statistisch nicht vom Mittelwert für 2021. Der beobachtete Unterschied ist auf Zufall zurückzuführen.
Zweite Hypothese: Der Mittelwert der Erhebungsergebnisse für die Seen im Jahr 2018 unterscheidet sich statistisch vom Mittelwert für 2021. Der beobachtete Unterschied ist nicht auf Zufall zurückzuführen.
Show code cell source
# data for testing
data=df[df.water_name_slug.isin(these_lakes)].copy()
# get the survey total for each survey keep the survey year column
pre_shuffle = data.groupby(["survey year", "loc_date"], as_index=False)[unit_label].sum()
# get the mean for each survey year
observed_mean = pre_shuffle.groupby("survey year")[unit_label].mean()
# get the diff
observed_dif = observed_mean.loc["IQAASL"] - observed_mean.loc[ "SLR"]
new_means=[]
# resampling:
for element in np.arange(5000):
# shuffle the survey year column
pre_shuffle["new_class"] = pre_shuffle["survey year"].sample(frac=1).values
# get the means for both years
b=b=pre_shuffle.groupby("new_class")['p/100 m'].mean()
# get the change and store it
new_means.append((b.loc["IQAASL"] - b.loc[ "SLR"]))
# calculate p
emp_p = np.count_nonzero(new_means <= observed_dif )/ 5000
# chart the results
fig, ax = plt.subplots()
sns.histplot(new_means, ax=ax)
ax.set_title(F"$\u0394\mu$ = {np.round(observed_dif, 2)}, perm=5000, p={emp_p} ", **ck.title_k14)
ax.set_ylabel("permutations", **featuredata.xlab_k14)
ax.set_xlabel("$\mu$ 2021 - $\mu$ 2018", **featuredata.xlab_k14)
f11caption = [
"Die Verteilung der Differenz der Mittelwerte der beiden Stichprobenzeiträumen. Die Erhebungsergebnisse wurden ",
"gemischt und in der Spalte des Erhebungsjahres 5000 Mal als Stichprobe gezogen. Die Nullhypothese konnte verworfen ",
"werden, was die anfängliche Beobachtung stützt, dass im Jahr 2021 weniger beobachtet wurde als 2018."
]
figure_name = "slr_iqaasl_lakes_dif_average"
figure_file_name = f'{save_fig_prefix}{figure_name}.jpeg'
save_figure_kwargs.update({"fname":figure_file_name})
plt.savefig(**save_figure_kwargs)
# capture the output
glue(figure_name, fig, display=False)
plt.close()
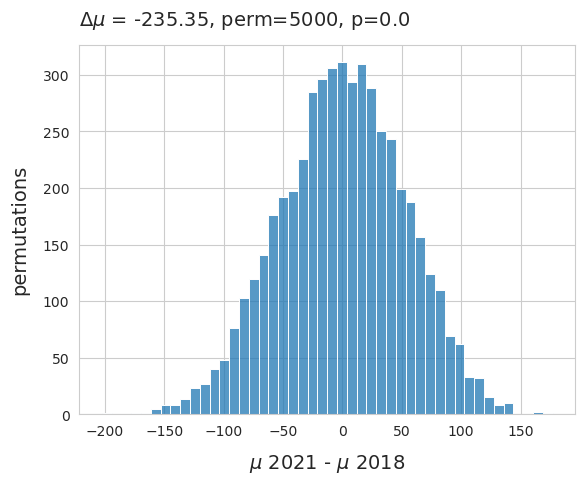
Abb. 21.11 #
Abbildung 21.11: Die Verteilung der Differenz der Mittelwerte der beiden Stichprobenzeiträumen. Die Erhebungsergebnisse wurden gemischt und in der Spalte des Erhebungsjahres 5000 Mal als Stichprobe gezogen. Die Nullhypothese konnte verworfen werden, was die anfängliche Beobachtung stützt, dass im Jahr 2021 weniger beobachtet wurde als 2018.
21.3.3. Differenz der Mittel häufigste Objekte#
Die beobachtete Differenz der Mittelwerte der beiden Probenahmezeiträume betrug -235 p/100 m. Die am häufigsten vorkommenden Objekte machen etwa 60 % der Gesamtmenge aus. Veränderungen in der täglichen Gesamtzahl können sich auch in den täglichen Gesamtzahlen der häufigsten Objekte widerspiegeln.
Nullhypothese: Der Mittelwert der Erhebungsergebnisse der häufigsten Objekte von 2018 ist derselbe wie 2021. Der beobachtete Unterschied ist auf Zufall zurückzuführen.
Alternativhypothese: Der Mittelwert der Erhebungsergebnisse der häufigsten Objekte von 2018 ist anders als 2021. Der beobachtete Unterschied ist nicht auf Zufall zurückzuführen.
wenn p < 0,05 = gelb: Der Unterschied ist statistisch signifikant.
Show code cell source
# data testing
data=df[df.water_name_slug.isin(these_lakes)].copy()
# data to resample
pre_shuffle = data[data.code.isin(mcom)].groupby(["survey year", "loc_date", "code"], as_index=False)[unit_label].sum()
# the observed mean from each year
observed_mean = pre_shuffle.groupby(["survey year", "code"])[unit_label].mean()
# get the differences from one year to the next: check the inverse
observed_dif = observed_mean.loc["IQAASL"] - observed_mean.loc[ "SLR"]
inv_diff = observed_mean.loc[ "SLR"] - observed_mean.loc["IQAASL"]
# number of shuffles
perms = 1000
new_means=[]
# resample
for a_code in mcom:
# store the test statisitc
cdif = []
c_data = pre_shuffle[pre_shuffle.code == a_code].copy()
for element in np.arange(perms):
# shuffle labels
c_data["new_class"] = c_data["survey year"].sample(frac=1).values
b=c_data.groupby("new_class")['p/100 m'].mean()
cdif.append((b.loc["IQAASL"] - b.loc[ "SLR"]))
emp_p = np.count_nonzero(cdif <= (observed_dif.loc[a_code])) / perms
# store that result
new_means.append({a_code:{"p":emp_p,"difs":cdif}})
# chart the results
fig, axs = plt.subplots(4,2, figsize=(6,10), sharey=True)
for i,code in enumerate(mcom):
# set up the ax
row = int(np.floor((i/2)%4))
col =i%2
ax=axs[row, col]
# data for charts
data = new_means[i][code]["difs"]
# pvalues
p=new_means[i][code]["p"]
# set the facecolor based on the p value
if p < 0.05:
ax.patch.set_facecolor("palegoldenrod")
ax.patch.set_alpha(0.5)
# plot that
sns.histplot(data, ax=ax, color=this_palette["IQAASL"])
ax.set_title(code_description_map.loc[code], loc="center", fontsize=12)
ax.set_xlabel(F"$\u0394\mu$={np.round(observed_dif.loc[code], 2)}, p={new_means[i][code]['p']}", fontsize=12)
ax.set_ylabel("permutations")
# hide the unused axs
sut.hide_spines_ticks_grids(axs[3,1])
# get some space for xaxis label
plt.tight_layout()
plt.subplots_adjust(hspace=0.7, wspace=.7)
f12caption = [
"Der beobachtete Unterschied in den Mittelwerten zwischen den beiden Jahren könnte zum Teil durch den Rückgang der ",
"Mengen an Zigaretten, Schaumpolystyrol, Metallflaschenverschlüssen und zerbrochenen Kunststoffen erklärt werden."
]
figure_name = "slr_iqaasl_lakes_dif_objects"
figure_file_name = f'{save_fig_prefix}{figure_name}.jpeg'
save_figure_kwargs.update({"fname":figure_file_name})
plt.savefig(**save_figure_kwargs)
# capture the output
glue(figure_name, fig, display=False)
plt.close()
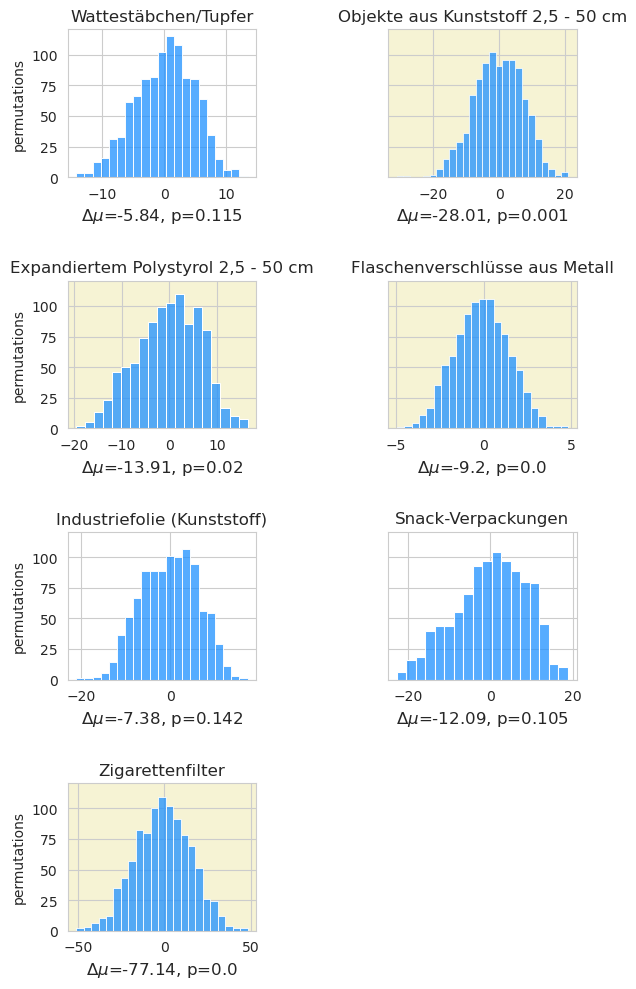
Abb. 21.12 #
Abbildung 21.12: Der beobachtete Unterschied in den Mittelwerten zwischen den beiden Jahren könnte zum Teil durch den Rückgang der Mengen an Zigaretten, Schaumpolystyrol, Metallflaschenverschlüssen und zerbrochenen Kunststoffen erklärt werden.
21.3.4. Landnutzungsprofil: Spearmans rangierte Korrelation#
Die Merkmale der Landnutzung wurden zuvor berechnet, um die Erhebungsorte zu vergleichen. Um die statistische Signifikanz der Landnutzung auf die Ergebnisse der Uferabfalluntersuchung zu testen, wurden die Gesamtzahlen und Erhebungsorte beider Projekte als eine Gruppe betrachtet. Die Erhebungsergebnisse der häufigsten Objekte wurden mit den gemessenen Landnutzungsmerkmalen verglichen.
Spearmans Rho oder Spearmans Rangkorrelationskoeffizient ist ein nichtparametrischer Test der Rangkorrelation zwischen zwei Variablen [Wikd] [Inn]. Die Testergebnisse werden bei p < 0,05 und 454 Stichproben ausgewertet. Zur Implementierung des Tests wird SciPy verwendet [scc].
Rot/Rosa steht für eine positive Assoziation: p < 0,05 und Rho > 0
Gelb steht für eine negative Assoziation: p < 0,05 und Rho < 0
Weiss, dass es keine statistische Grundlage für die Annahme eines Zusammenhangs gibt: p > 0,05
Unten: Eine Assoziation deutet darauf hin, dass sich die Erhebungssummen für das betreffende Objekt im Verhältnis zu der diesem Merkmal zugewiesenen Fläche (oder im Falle von Strassen oder Flussmündungen: Menge) ändern. Das Ausmass der Beziehung ist nicht definiert, und jede Assoziation ist nicht linear.
Show code cell source
corr_data = lks_df[(lks_df.code.isin(mcom))].copy()
# keys to the column names
some_keys = {
"% to buildings":"lu_build",
"% to agg":"lu_agg",
"% to woods":"lu_woods",
"% to recreation":"lu_rec",
"% to trans":"lu_trans",
"% to meadow":"lu_m",
"str_rank":"lu_trans"
}
fig, axs = plt.subplots(len(mcom),len(luse_exp), figsize=(len(luse_exp)+7,len(mcom)+1), sharey="row")
for i,code in enumerate(mcom):
data = corr_data[corr_data.code == code]
for j, n in enumerate(luse_exp):
# each grid is its own axis with a scatterplot
ax=axs[i, j]
ax.grid(False)
ax.tick_params(axis="both", which="both",bottom=False,top=False,labelbottom=False, labelleft=False, left=False)
if i == 0:
ax.set_title(f"{featuredata.luse_de[n]}", rotation=67.5, ha="left", fontsize=12)
else:
pass
if j == 0:
ax.set_ylabel(F"{code_description_map[code]}", rotation=0, ha="right", **featuredata.xlab_k14)
ax.set_xlabel(" ")
else:
ax.set_xlabel(" ")
ax.set_ylabel(" ")
_, corr, a_p = sut.make_plot_with_spearmans(data, ax, n, unit_label=unit_label)
# assign the facecolor based on the value of p and rho
if a_p < 0.05:
if corr > 0:
ax.patch.set_facecolor("salmon")
ax.patch.set_alpha(0.5)
else:
ax.patch.set_facecolor("palegoldenrod")
ax.patch.set_alpha(0.5)
plt.tight_layout()
plt.subplots_adjust(wspace=0, hspace=0)
f13caption = [
"Eine Assoziation deutet darauf hin, dass sich die Erhebungssummen für das betreffende Objekt im Verhältnis zu der diesem Merkmal ",
"zugewiesenen Fläche (oder im Falle von Strassen oder Flussmündungen: Menge) ändern. Das Ausmass der Beziehung ist nicht definiert, ",
"und jede Assoziation ist nicht linear."
]
figure_name = "slr_iqaasl_lakes_landuse"
figure_file_name = f'{save_fig_prefix}{figure_name}.jpeg'
save_figure_kwargs.update({"fname":figure_file_name})
plt.savefig(**save_figure_kwargs)
# capture the output
glue(figure_name, fig, display=False)
plt.close()
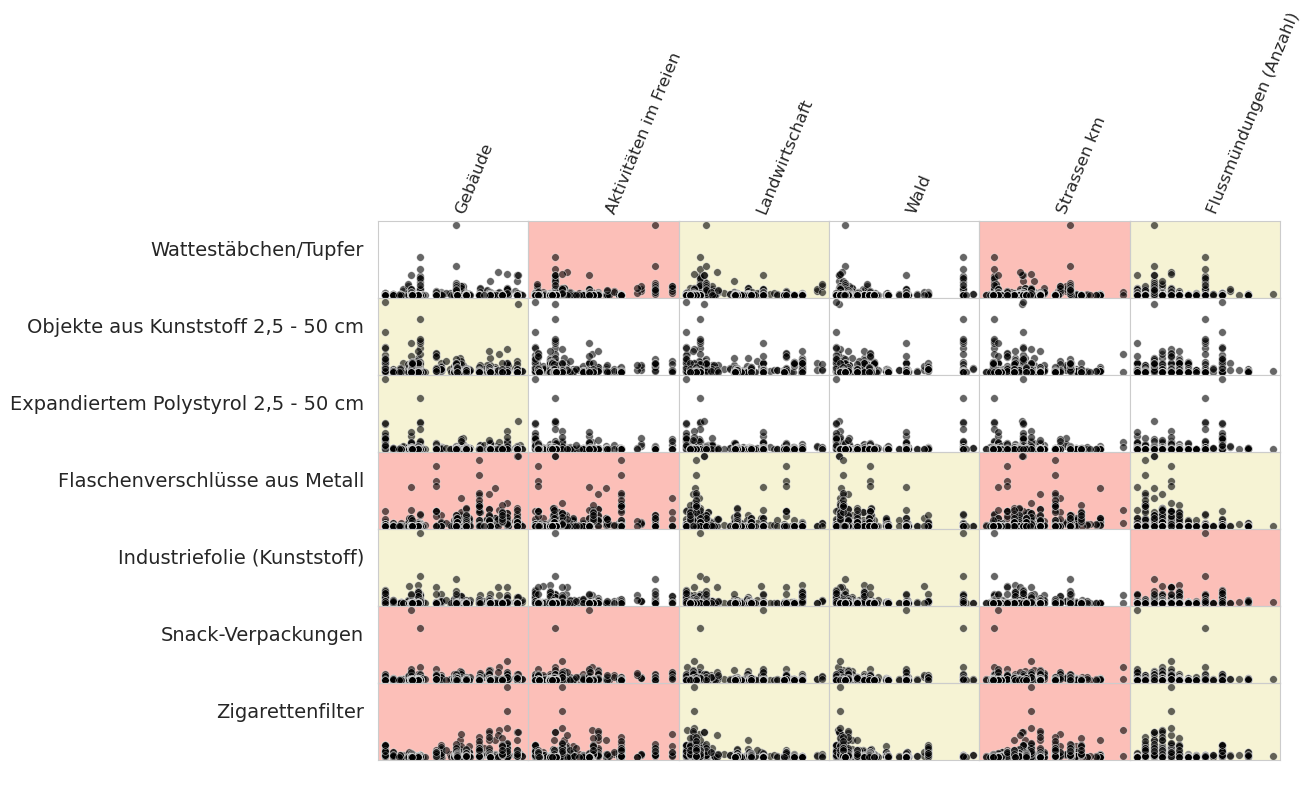
Abb. 21.13 #
Abbildung 21.13: Eine Assoziation deutet darauf hin, dass sich die Erhebungssummen für das betreffende Objekt im Verhältnis zu der diesem Merkmal zugewiesenen Fläche (oder im Falle von Strassen oder Flussmündungen: Menge) ändern. Das Ausmass der Beziehung ist nicht definiert, und jede Assoziation ist nicht linear.
21.3.4.1. Interpretation von Spearmans \(\rho\)#
Eine positive Assoziation deutet darauf hin, dass Landnutzungsmerkmale die Untersuchungsergebnisse im Vergleich zu anderen Erhebungsorten erhöhen. Dies kann auf eine Kovarianz von Merkmalen zurückzuführen sein. In jedem Fall ist eine positive Assoziation ein Signal dafür, dass die Erhebungsgsorte in der Nähe einer Akkumulationszone oder einer Quelle liegen. Dieses Signal sollte zusammen mit den anderen Schlüsselindikatoren von Erhebungsorten mit ähnlichen Landnutzungsprofilen bewertet werden. Im Allgemeinen können Orte, die die Kriterien erfüllen, sowohl als Quelle als auch als Akkumulationsgebiet für alle Objekte, die positiv assoziiert sind, betrachtet werden.
Eine negative Assoziation bedeutet, dass das Landnutzungsmerkmal die Akkumulation des Objekts nicht erleichtert. Dieses Ergebnis ist für landwirtschaftliche und bewaldete Gebiete auf nationaler Ebene üblich. Eine negative Assoziation ist ein Signal dafür, dass die Orte keine Akkumulationszone für das Objekt sind.
Wenige oder keine Assoziationen bedeuten, dass die Landnutzungsmerkmale keinen Einfluss auf die Anhäufung dieses Objekts hatten. Die Erhebungsergebnisse zu den häufigsten Objekten ohne oder mit wenigen Assoziationen lassen sich in zwei Kategorien einteilen:
Allgegenwärtig: hohe Häufigkeitsrate, hohe Stückzahl pro Meter. Im gesamten Untersuchungsgebiet in gleichbleibender Häufigkeit gefunden, unabhängig von der Landnutzung
Vorübergehend: geringe Häufigkeitsrate, hohe Menge, hohe Stückzahl pro Meter, wenige Verbände. Gelegentlich in grossen Mengen an bestimmten Orten gefunden.
21.4. Fazit#
21.4.1. Per Saldo keine Änderung#
Die zusammenfassenden Statistiken und die Ergebnisse des Tests zur Differenz der Mediane deuten darauf hin, dass es auf nationaler Ebene keine statistisch messbare Veränderung von einem Projekt zum nächsten gab. Das 95-Prozent-Konfidenzintervall des Medianwertes der Erhebung im Jahr 2021 lag bei 137–188 p/100 m (siehe 14 Basiswerte für Abfallobjekte an Gewässern¶). Das Medianergebnis für 2018 lag bei 125 p/100 m mit einem 95-Prozent-Konfidenzintervall von 112–146 p/100 m, was die untere Grenze des Medians von 2021 einschliesst. Die Differenz der Mittelwerte für die häufigsten Objekte deutet jedoch auf ein realistischeres und dynamischeres Ergebnis hin:
Es gab einen statistisch signifikanten Rückgang bei vier der sieben häufigsten Objekte aus beiden Jahren:
Zigarettenfilter
Flaschenverschlüsse aus Metall
Kunststofffragmente > 2,5 cm
Fragmente aus Schaumstoff > 2,5 cm
Der Rückgang bei Tabak und Flaschenverschlüssen könnte mit den pandemischen Einschränkungen im Jahr 2021 zusammenhängen. Die Ergebnisse deuten darauf hin, dass der wahrgenommene lokale Rückgang der Abfallmengen höchstwahrscheinlich das Ergebnis eines allgemeinen Rückgangs der Nutzung und nicht einer umfassenden Verhaltensänderung war. Folglich werden die Erhebungsergebnisse für die genannten Objekte höchstwahrscheinlich wieder auf das Niveau von 2018 zurückkehren, wenn die pandemiebedingten Beschränkungen gelockert werden und sich die Nutzungsmuster wieder normalisieren.
Die Rückgänge bei fragmentierten Schaumstoffen und geschäumten Kunststoffen sind wahrscheinlich auf einen Unterschied in den Protokollen zwischen den beiden Jahren zurückzuführen.
21.4.2. Protokolle#
Es gab einen entscheidenden Unterschied zwischen den beiden Projekten:
Das Protokoll von 2021 zählt alle sichtbaren Objekte und klassifiziert Fragmente nach Grösse
Das Protokoll von 2018 beschränkte die Anzahl der Objekte auf Gegenstände, die mindestens 2,5 cm lang waren
Die Gesamtmenge der im Jahr 2021 gesammelten Kunststoffteile beträgt 7400 oder 18 p/100 m und 5563 oder 5 p/100 m Schaumstofffragmente. Im Jahr 2021 wurden 3662 Plastikteile zwischen 0,5 und 2,5 cm entfernt, was der Gesamtmenge von 2018 entspricht. Das Gleiche gilt für Schaumstoffteile zwischen 0,5 und 2,5 cm, siehe 1 Seen und Fliessgewässer¶
Der Unterschied im Protokoll und die Ergebnisse von 2021 lassen Zweifel an der Wahrscheinlichkeit eines Rückgangs von fragmentierten Kunststoffen und geschäumten Kunststoffen von 2018 bis 2021 aufkommen. Geschäumte Kunststoffe und fragmentierte Kunststoffe sind Objekte, deren ursprüngliche Verwendung unbekannt ist, aber das Material kann unterschieden werden. Fragmentierte Kunststoffe und Schaumstoffe, die grösser als 0,5 cm sind, machen 27 % der gesamten Erhebungsergebnisse für die Seen im Jahr 2021 aus. Studien im Maas-/Rheindelta zeigen, dass diese kleinen, fragmentierten Objekte einen grossen Teil des Gesamtaufkommens ausmachen. [vE]
Wenn den Vermessungsingenieuren erlaubt wird, eine breitere Palette von Objektcodes zu verwenden, erhöht sich die Genauigkeit der Gesamtzahl der erfassten Objekte und es lassen sich zusätzliche Ebenen zur Unterscheidung ähnlicher Materialien einrichten. Expandiertes Polystyrol zum Beispiel ist ein Objekt, das leicht zersplittert. Ob die Vermesser einige grössere Stücke > 20 cm oder Tausende von Stücken < 10 mm finden, ist ein wichtiges Detail, wenn das Ziel darin besteht, diese Objekte in der Umwelt zu reduzieren.
Geringere Kosten und besserer Zugang sind ein weiteres Ergebnis eines harmonisierten Protokolls. Die von SLR und IQAASL angewandten Verfahren waren fast identisch, abgesehen von der Grössenbeschränkung kann man davon ausgehen, dass die Proben unter ähnlichen Bedingungen gesammelt wurden. Die SLR-Daten liefern die Ergebnisse von über 1000 Beobachtungen von etwa 150 Personen und die IQAASL-Daten liefern die Ergebnisse von 350 Beobachtungen von etwa 10 Personen. Beide Methoden haben Schwächen und Stärken, die sehr unterschiedliche Themen ansprechen:
Erfahrung des Vermessungsingenieurs
Konsistenz der Erhebungsergebnisse
Aufsicht
beabsichtigte Verwendung der Daten
Zuweisung von Ressourcen
All diese Themen sollten bei jedem Projekt berücksichtigt werden, ebenso wie der Umgang mit den Daten. Ungeachtet der Unterschiede konnten wir auf dem vom SLR vorgeschlagenen Modell aufbauen und zu den gemeinsamen Erfahrungen beitragen.
21.4.3. Kunststoffdeckel#
Kunststoffdeckel werden bei der Zählung in drei Kategorien eingeteilt:
Essen, Trinken
Chemie/Haushalt
unbekannt
Als Gruppe machen Kunststoffdeckel 2 % der gesamten Objekte im Jahr 2018 und 3 % im Jahr 2021 aus. Getränkedeckel machten ca. 51 % aller gefundenen Deckel im Jahr 2018 aus, 45 % im Jahr 2021. Auf der Basis von Abfallobjekten pro Meter gab es eine Abnahme der Menge an Getränkedeckeln und eine Zunahme von Nicht-Getränkedeckeln von 2018–2021.
21.4.4. Landnutzungsprofil#
Das Landnutzungsprofil für jeden Erhebungsort wurde unter Verwendung derselben Daten für beide Jahre berechnet. Wenn die Erhebungsergebnisse aus beiden Jahren als Gruppe betrachtet werden, unterstützen die Ergebnisse von Spearmans Rho die SLR-Schlussfolgerungen im Jahr 2018, dass die Erhebungsergebnisse in städtischen und vorstädtischen Umgebungen erhöht waren, und dies galt auch für 2021. Gleichzeitig war die im Kapitel 17 Landnutzungsprofil¶ festgestellte Allgegenwärtigkeit von zerkleinerten Kunststoffen, Industriefolien und Schaumstoffen im Jahr 2018 wahrscheinlich vorherrschend..
Bei den Flächen, die Aktivitäten im Freien zugeschrieben werden, handelt es sich um Orte in der Nähe des Erhebungsortes, die dazu bestimmt sind, Gruppen von Menschen für verschiedene Aktivitäten zu beherbergen. Die positive Assoziation von Tabak und Lebensmitteln/Getränken mit diesem Landnutzungsmerkmal könnte als Ergebnis eines vorübergehenden Anstiegs der Bevölkerung in der Nähe des Untersuchungsgebiets interpretiert werden.
21.4.5. Schlussfolgerungen#
Die Proben aus beiden Projekten wurden an Orten entnommen, die ein ähnliches Niveau an Infrastruktur und wirtschaftlicher Entwicklung aufwiesen. In einigen Fällen waren die Erhebungsorte identisch. Bei beiden Projekten wurde ein gemeinsames Protokoll verwendet. Die Proben wurden von zwei verschiedenen Gruppen entnommen und von zwei verschiedenen Verbänden verwaltet.
Von 2018 bis 2021 gab es eine statistisch signifikante Veränderung, nämlich einen Rückgang der Anzahl der Objekte, die direkt mit dem Verhalten am Erhebungsort in Verbindung stehen. Dies deutet darauf hin, dass die wahrgenommenen Rückgänge an Orten stattfanden, die einen höheren Anteil an Gebäuden und einen geringeren Anteil an Landwirtschafts- oder Waldflächen aufweisen.
Erhebungsorte mit einem entgegengesetzten oder anderen Landnutzungsprofil (weniger Gebäude, mehr Landwirtschaft oder Wälder) werden höchstwahrscheinlich überhaupt keinen Rückgang erfahren haben. An Erhebungsorten in der Nähe von Flussmündungen oder grösseren Einleitungsstellen wäre kein Unterschied zwischen 2018 und 2021 erkennbar und eine Zunahme von zerbrochenen Kunststoffen, Schaumstoffen und Industriefolien wahrscheinlich. Sowohl der Test der Differenz der Mediane der häufigsten Objekte als auch die Ergebnisse von Spearmans Rho der Erhebungsergebnisse unterstützen diese Schlussfolgerung.
Beide Erhebungsjahre zeigen Spitzenwerte im Juni und Juli (Anhang) und Tiefstwerte im November. Die möglichen Ursachen für die Spitzen- und Tiefstwerte sind je nach Objekt unterschiedlich. Lebensmittel- und Tabakgegenstände sind in der Sommersaison aufgrund des verstärkten Gebrauchs häufiger anzutreffen. Objekte wie zerbrochene Kunststoffe hängen mehr von den hydrologischen Bedingungen ab und die Abflussspitzen der grössten Flüsse in dieser Studie liegen zwischen Mai und Juli (Mitverantwortung).
Künftige Erhebungen sollten sichtbare Objekte aller Grössenordnungen umfassen. Die Datenaggregation kann auf dem Server anhand definierter Regeln erfolgen, die auf bekannten Beziehungen basieren. Die Gesamtzahl ist ein Schlüsselindikator in allen Statistiken, die auf Zähldaten beruhen, und für Modellierungszwecke unerlässlich.
21.5. Anhang#
21.5.1. Seen: monatliche mediane gemeinsame Objekte:#
Bei beiden Projekten wurden alle Seen in allen Monaten beprobt. Im Jahr 2018 lag das Minimum der Proben pro Monat bei 12 und das Maximum bei 17, verglichen mit einem Minimum von 17 und einem Maximum von 34 im Jahr 2021.
| Apr. | Mai | Juni | Juli | Aug. | Sept. | Okt. | Nov. | Dez. | Jan. | Feb. | März | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Wattestäbchen/Tupfer | 8,9 | 82,4 | 36,8 | 10,5 | 9,6 | 12,8 | 15,8 | 11,5 | 2,9 | 4,6 | 5,8 | 20,8 |
| Objekte aus Kunststoff 2,5 - 50 cm | 36,1 | 117,9 | 66,1 | 62,4 | 62,6 | 86,7 | 19,4 | 33,5 | 32,9 | 34,8 | 36,0 | 63,6 |
| Expandiertem Polystyrol 2,5 - 50 cm | 19,1 | 33,7 | 33,4 | 40,6 | 33,9 | 64,6 | 9,8 | 16,8 | 24,1 | 32,3 | 9,8 | 44,1 |
| Flaschenverschlüsse aus Metall | 23,1 | 26,2 | 20,2 | 16,5 | 10,5 | 8,9 | 7,9 | 13,8 | 4,7 | 8,4 | 4,2 | 13,3 |
| Industriefolie (Kunststoff) | 35,7 | 73,2 | 39,1 | 20,2 | 40,3 | 26,7 | 12,8 | 17,6 | 24,2 | 15,2 | 9,6 | 39,5 |
| Snack-Verpackungen | 40,2 | 52,4 | 61,4 | 36,1 | 29,5 | 53,7 | 19,0 | 20,8 | 12,4 | 10,8 | 9,1 | 120,9 |
| Zigarettenfilter | 153,6 | 242,8 | 299,2 | 228,4 | 171,1 | 128,9 | 83,9 | 91,0 | 16,7 | 41,0 | 43,2 | 93,9 |
Abb. 21.14 #
Abbildung 21.14: Durchschnittliche monatliche Erhebungsergebnisse der häufigsten Objekten an Seen SLR.
| Apr. | Mai | Juni | Juli | Aug. | Sept. | Okt. | Nov. | Dez. | Jan. | Feb. | März | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Wattestäbchen/Tupfer | 4,6 | 14,9 | 25,9 | 25,3 | 15,9 | 10,1 | 11,6 | 4,0 | 13,0 | 12,5 | 7,3 | 17,1 |
| Objekte aus Kunststoff 2,5 - 50 cm | 38,2 | 48,8 | 46,1 | 48,3 | 30,7 | 29,0 | 16,6 | 7,8 | 21,6 | 12,6 | 13,6 | 29,4 |
| Expandiertem Polystyrol 2,5 - 50 cm | 32,2 | 28,4 | 32,2 | 35,1 | 20,9 | 13,3 | 9,0 | 7,4 | 5,3 | 10,9 | 6,9 | 5,3 |
| Flaschenverschlüsse aus Metall | 3,6 | 6,1 | 7,6 | 7,8 | 6,0 | 3,9 | 2,8 | 1,7 | 2,3 | 3,3 | 2,0 | 2,6 |
| Industriefolie (Kunststoff) | 29,7 | 20,1 | 22,8 | 33,1 | 22,2 | 29,2 | 19,7 | 11,8 | 9,8 | 12,3 | 15,1 | 68,8 |
| Snack-Verpackungen | 29,5 | 22,1 | 41,0 | 40,5 | 26,3 | 38,9 | 23,5 | 12,8 | 14,2 | 18,7 | 12,8 | 71,2 |
| Zigarettenfilter | 79,2 | 64,2 | 106,0 | 106,0 | 102,4 | 103,5 | 29,6 | 19,2 | 17,6 | 24,4 | 35,7 | 55,5 |
Abb. 21.15 #
Abbildung 21.15: Durchschnittliche monatliche Erhebungsergebnisse der häufigsten Objekten an Seen IQAASL.
21.5.1.1. Erhebungsorte#
| latitude | longitude | Stadt | |
|---|---|---|---|
| Standort | |||
| aabach | 47.220989 | 8.940365 | Schmerikon |
| anarchy-beach | 46.447216 | 6.859612 | La Tour-de-Peilz |
| augustmutzenbergstrandweg | 46.686640 | 7.689760 | Spiez |
| baby-plage-geneva | 46.208558 | 6.162923 | Genève |
| baby-plage-ii-geneve | 46.208940 | 6.164330 | Genève |
| bain-des-dames | 46.450507 | 6.858092 | La Tour-de-Peilz |
| baye-de-montreux-g | 46.430834 | 6.908778 | Montreux |
| bielersee_vinelz_fankhausers | 47.038398 | 7.108311 | Vinelz |
| boiron | 46.491030 | 6.480162 | Tolochenaz |
| camp-des-peches | 47.052812 | 7.074053 | Le Landeron |
| camping-gwatt-strand | 46.727140 | 7.629620 | Thun |
| cully-plage | 46.488887 | 6.741396 | Bourg-en-Lavaux |
| delta-park | 46.720078 | 7.635304 | Spiez |
| erlach-camping-strand | 47.047159 | 7.097854 | Erlach |
| evole-plage | 46.989477 | 6.923920 | Neuchâtel |
| flibach-river-right-bank | 47.133742 | 9.105461 | Weesen |
| gals-reserve | 47.046272 | 7.085007 | Gals |
| gasi-strand | 47.128442 | 9.110831 | Weesen |
| grand-clos | 46.387746 | 6.843686 | Saint-Gingolph |
| hauterive-petite-plage | 47.010797 | 6.980304 | Hauterive (NE) |
| impromptu_cudrefin | 46.964496 | 7.027936 | Cudrefin |
| la-pecherie | 46.463919 | 6.385732 | Allaman |
| la-petite-plage | 46.785054 | 6.656877 | Yverdon-les-Bains |
| lacleman_gland_lecoanets | 46.402811 | 6.281959 | Gland |
| le-pierrier | 46.439727 | 6.888968 | Montreux |
| ligerz-strand | 47.083979 | 7.135894 | Ligerz |
| luscherz-plage | 47.047955 | 7.151242 | Lüscherz |
| luscherz-two | 47.047519 | 7.152829 | Lüscherz |
| maladaire | 46.446296 | 6.876960 | La Tour-de-Peilz |
| mols-rocks | 47.114343 | 9.288174 | Quarten |
| muhlehorn-dorf | 47.118448 | 9.172124 | Glarus Nord |
| mullermatte | 47.133339 | 7.227907 | Biel/Bienne |
| murg-bad | 47.115307 | 9.215691 | Quarten |
| nidau-strand | 47.127196 | 7.232613 | Nidau |
| nouvelle-plage | 46.856646 | 6.848428 | Estavayer |
| oyonne | 46.456682 | 6.852262 | La Tour-de-Peilz |
| parc-des-pierrettes | 46.515215 | 6.575531 | Saint-Sulpice (VD) |
| pecos-plage | 46.803590 | 6.636650 | Grandson |
| pfafikon-bad | 47.206766 | 8.774182 | Freienbach |
| plage-de-cheyres | 46.818689 | 6.782256 | Cheyres-Châbles |
| plage-de-st-sulpice | 46.513265 | 6.570977 | Saint-Sulpice (VD) |
| pointe-dareuse | 46.946190 | 6.870970 | Boudry |
| preverenges | 46.512690 | 6.527657 | Préverenges |
| preverenges-le-sout | 46.508905 | 6.534526 | Préverenges |
| quai-maria-belgia | 46.460156 | 6.836718 | Vevey |
| rastplatz-stampf | 47.215177 | 8.844286 | Rapperswil-Jona |
| rocky-plage | 46.209737 | 6.164952 | Genève |
| ruisseau-de-la-croix-plage | 46.813920 | 6.774700 | Cheyres-Châbles |
| schmerikon-bahnhof-strand | 47.224780 | 8.944180 | Schmerikon |
| seeflechsen | 47.130223 | 9.103400 | Glarus Nord |
| seemuhlestrasse-strand | 47.128640 | 9.295100 | Walenstadt |
| signalpain | 46.786200 | 6.647360 | Yverdon-les-Bains |
| strandboden-biel | 47.132510 | 7.233142 | Biel/Bienne |
| sundbach-strand | 46.684386 | 7.794768 | Beatenberg |
| thun-strandbad | 46.739939 | 7.633520 | Thun |
| thunersee_spiez_meierd_1 | 46.704437 | 7.657882 | Spiez |
| tiger-duck-beach | 46.518256 | 6.582546 | Saint-Sulpice (VD) |
| tolochenaz | 46.497509 | 6.482875 | Tolochenaz |
| untertenzen | 47.115260 | 9.254780 | Quarten |
| versoix | 46.289194 | 6.170569 | Versoix |
| vidy-ruines | 46.516221 | 6.596279 | Lausanne |
| villa-barton | 46.222350 | 6.152500 | Genève |
| walensee_walenstadt_wysse | 47.121828 | 9.299552 | Walenstadt |
| weissenau-neuhaus | 46.676583 | 7.817528 | Unterseen |
| zuerichsee_richterswil_benkoem_2 | 47.217646 | 8.698713 | Richterswil |
| zuerichsee_staefa_hennm | 47.234643 | 8.769881 | Stäfa |
| zuerichsee_waedenswil_colomboc_1 | 47.219547 | 8.691961 | Richterswil |
| zurcher-strand | 47.364200 | 8.537420 | Zürich |
| zurichsee_kusnachterhorn_thirkell-whitej | 47.317685 | 8.576860 | Küsnacht (ZH) |
| zurichsee_wollishofen_langendorfm | 47.345890 | 8.536155 | Zürich |
| la-morges | 46.504063 | 6.494099 | Morges |
| lac-leman-hammerdirt | 46.450389 | 6.858234 | La Tour-de-Peilz |
| lacleman_gland_kubela | 46.402869 | 6.281936 | Gland |
| lacleman_vidy_santie | 46.518318 | 6.589608 | Lausanne |
| neuenburgersee_cudrefin_mattera | 46.962709 | 7.025968 | Cudrefin |
| zuerichsee_maennedorf_vanderkaadene | 47.254754 | 8.687504 | Männedorf |
| zuerichsee_zurich_kullg | 47.353957 | 8.550474 | Zürich |
| zurichsee-feldeggstr-banningersand | 47.359392 | 8.547368 | Zürich |