
Show code cell source
# -*- coding: utf-8 -*-
# This is a report using the data from IQAASL.
# IQAASL was a project funded by the Swiss Confederation
# It produces a summary of litter survey results for a defined region.
# These charts serve as the models for the development of plagespropres.ch
# The data is gathered by volunteers.
# Please remember all copyrights apply, please give credit when applicable
# The repo is maintained by the community effective January 01, 2022
# There is ample opportunity to contribute, learn and teach
# contact dev@hammerdirt.ch
# Dies ist ein Bericht, der die Daten von IQAASL verwendet.
# IQAASL war ein von der Schweizerischen Eidgenossenschaft finanziertes Projekt.
# Es erstellt eine Zusammenfassung der Ergebnisse der Littering-Umfrage für eine bestimmte Region.
# Diese Grafiken dienten als Vorlage für die Entwicklung von plagespropres.ch.
# Die Daten werden von Freiwilligen gesammelt.
# Bitte denken Sie daran, dass alle Copyrights gelten, bitte geben Sie den Namen an, wenn zutreffend.
# Das Repo wird ab dem 01. Januar 2022 von der Community gepflegt.
# Es gibt reichlich Gelegenheit, etwas beizutragen, zu lernen und zu lehren.
# Kontakt dev@hammerdirt.ch
# Il s'agit d'un rapport utilisant les données de IQAASL.
# IQAASL était un projet financé par la Confédération suisse.
# Il produit un résumé des résultats de l'enquête sur les déchets sauvages pour une région définie.
# Ces tableaux ont servi de modèles pour le développement de plagespropres.ch
# Les données sont recueillies par des bénévoles.
# N'oubliez pas que tous les droits d'auteur s'appliquent, veuillez indiquer le crédit lorsque cela est possible.
# Le dépôt est maintenu par la communauté à partir du 1er janvier 2022.
# Il y a de nombreuses possibilités de contribuer, d'apprendre et d'enseigner.
# contact dev@hammerdirt.ch
# sys, file and nav packages:
import datetime as dt
# for date and month formats in french or german
import locale
# math packages:
import pandas as pd
import numpy as np
from scipy import stats
from statsmodels.distributions.empirical_distribution import ECDF
# charting:
import matplotlib as mpl
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
from matplotlib import ticker
from matplotlib import colors
import seaborn as sns
import matplotlib.gridspec as gridspec
# build report
import reportlab
from reportlab.platypus.flowables import Flowable
from reportlab.platypus import SimpleDocTemplate, Paragraph, Spacer, PageBreak, KeepTogether
from reportlab.lib.pagesizes import A4
from reportlab.lib.units import cm
from reportlab.platypus import Table, TableStyle
# the module that has all the methods for handling the data
import resources.featuredata as featuredata
from resources.featuredata import makeAList, small_space, large_space, aSingleStyledTable, smallest_space
from resources.featuredata import caption_style, subsection_title, title_style, block_quote_style, makeBibEntry
from resources.featuredata import figureAndCaptionTable, tableAndCaption, aStyledTableWithTitleRow
from resources.featuredata import sectionParagraphs, section_title, addToDoc, makeAParagraph, bold_block
# home brew utitilties
import resources.chart_kwargs as ck
import resources.sr_ut as sut
# images and display
import IPython # base64, io
from PIL import Image as PILImage
from IPython.display import Markdown as md
# from IPython.display import display, Math, Latex
import matplotlib.image as mpimg
from myst_nb import glue
save_fig_prefix = "resources/output/"
save_figure_kwargs = {
"fname": None,
"dpi": 300.0,
"format": "jpeg",
"bbox_inches": None,
"pad_inches": 0,
"bbox_inches": 'tight',
"facecolor": 'auto',
"edgecolor": 'auto',
"backend": None,
}
pdf_link = 'resources/pdfs/sharedresponsibility.pdf'
source_prefix = "https://hammerdirt-analyst.github.io/IQAASL-End-0f-Sampling-2021/"
source = "shared_responsibility.html"
# set the locale to the language desired
# the locale is set back to to original at the the end of the script
loc = locale.getlocale()
lang = "de_CH.utf8"
locale.setlocale(locale.LC_ALL, lang)
# the date is in iso standard:
d = "%Y-%m-%d"
# it gets changed to german format
g = "%d.%m.%Y"
# set some parameters:
start_date = "2020-03-01"
end_date ="2021-05-31"
# ge_start = "01.03.2020"
# ge_end ="31.05.2021"
start_end = [start_date, end_date]
a_fail_rate = 50
unit_label = 'p/100 m'
reporting_unit = 100
sns.set_style('whitegrid')
a_color = 'dodgerblue'
# set the maps
bassin_map = PILImage.open("resources/maps/survey_locations_all.jpeg")
# common aggregations
agg_pcs_quantity = {unit_label:"sum", "quantity":"sum"}
agg_pcs_median = {unit_label:"median", "quantity":"sum"}
# aggregation of dimensional data
agg_dims = {"total_w":"sum", "mac_plast_w":"sum", "area":"sum", "length":"sum"}
# define the components
comps = ['linth', 'rhone', 'aare', 'ticino']
comp_labels = {"linth":"Linth / Limmat", "rhone":"Rhône", 'aare':"Aare", "ticino":"Ticino / Cerisio", "reuss":"Reuss"}
# explanatory variables:
luse_exp = ['% to buildings', '% to recreation', '% to agg', '% to woods', 'streets km', 'intersects']
# columns needed
use_these_cols = ['loc_date' ,
'% to buildings',
'% to trans',
'% to recreation',
'% to agg',
'% to woods',
'population',
'river_bassin',
'water_name_slug',
'streets km',
'intersects',
'length',
'groupname',
'code'
]
# these are default
top_name = ["Alle"]
# get your data:
survey_data = pd.read_csv('resources/checked_sdata_eos_2020_21.csv')
dfBeaches = pd.read_csv("resources/beaches_with_land_use_rates.csv")
dfCodes = pd.read_csv("resources/codes_with_group_names_2015.csv")
dfDims = pd.read_csv("resources/corrected_dims.csv")
# set the index of the beach data to location slug
dfBeaches.set_index('slug', inplace=True)
dfCodes.set_index("code", inplace=True)
# language specific
# importing german code descriptions
de_codes = pd.read_csv("resources/codes_german_Version_1.csv")
de_codes.set_index("code", inplace=True)
# the surveyor designated the object as aluminum instead of metal
dfCodes.loc["G708", "material"] = "Metal"
for x in dfCodes.index:
dfCodes.loc[x, "description"] = de_codes.loc[x, "german"]
# there are long code descriptions that may need to be shortened for display
codes_to_change = [
["G704", "description", "Seilbahnbürste"],
["Gfrags", "description", "Fragmentierte Kunststoffstücke"],
["G30", "description", "Snack-Verpackungen"],
["G124", "description", "Kunststoff-oder Schaumstoffprodukte"],
["G87", "description", "Abdeckklebeband/Verpackungsklebeband"],
["G178","description","Flaschenverschlüsse aus Metall"],
["G3","description","Einkaufstaschen, Shoppingtaschen"],
["G33", "description", "Einwegartikel; Tassen/Becher & Deckel"],
["G31", "description", "Schleckstengel, Stengel von Lutscher"],
["G211", "description", "Sonstiges medizinisches Material"],
["G904", "description", "Feuerwerkskörper; Raketenkappen"],
["G940", "description", "Schaumstoff EVA (flexibler Kunststoff)"]
]
# apply changes
for x in codes_to_change:
dfCodes = sut.shorten_the_value(x, dfCodes)
# translate the material column
dfCodes["material"] = dfCodes.material.map(lambda x: sut.mat_ge[x])
# make a map to the code descriptions
code_description_map = dfCodes.description
glue("blank_caption", " ", display=False)
# make a map to the code descriptions
code_material_map = dfCodes.material
20. Geteilte Verantwortung#
Untersuchungen über den Eintrag und die Anreicherung von Abfällen in der aquatischen Umwelt zeigen, dass Fliessgewässer eine Hauptquelle für Makroplastik sind [GFCH+21]. Allerdings gelangen nicht alle Objekte, die von Fliessgewässer transportiert werden, in die Ozeane, was darauf hindeutet, dass Fliessgewässer und Binnenseen auch Senken für einen Teil des emittierten Makroplastiks sind. [KBK+18].
In den Bestimmungen des Schweizer Rechts, Artikel 2 des Bundesgesetzes über den Umweltschutz (USG), wird das Prinzip der Kausalität für die illegale Entsorgung von Material berücksichtigt und ist allgemein als Verursacherprinzip bekannt. Letztendlich liegt die Verantwortung für die Beseitigung und das Management der Verschmutzung durch Abfälle in und entlang von Gewässern bei den kommunalen und kantonalen Verwaltungen, da sie rechtlich gesehen Eigentümer des Landes innerhalb ihrer Grenzen sind. Das Gesetz gibt den Gemeinden und Kantonen die Möglichkeit, Personen oder Unternehmen (z. B. Fast-Food-Unternehmen und ähnliche Betriebe oder Organisatoren von Veranstaltungen, die grosse Mengen an Abfall im öffentlichen Raum erzeugen), die weiter oben in der Kausalkette stehen, als Abfallverursacher zu betrachten und von ihnen Entsorgungsgebühren zu erheben, wenn keine konkreten Verursacher ermittelt werden können und sofern objektive Kriterien zur Bestimmung der Kausalkette herangezogen werden. [fdlCs20a] [cfs20] [fdlenvironnement18] [fc12]
20.1. Die Herausforderung#
Objektive Kriterien erfordern robuste, transparente und leicht wiederholbare Methoden. Die Herausforderung besteht darin, verfügbare Informationen aus den weggeworfenen Objekten zu extrahieren, die auf Mengen, Materialeigenschaften und Umweltvariablen in der Nähe des Erhebungsortes basieren.

Abb. 20.1 #
Abbildung 20.1: Genfersee, St. Gingolph 07.05.2020 (1600 p/100 m).
Der Nutzen von weggeworfenen Objekten sowie die Landnutzung in der Umgebung von Datenerhebungen sind Indikatoren für die Herkunft der Abfälle. Das Landnutzungsprofil zur Bewertung der Verschmutzungsquellen ist für einige gängige Objekte nützlich. So wurden beispielsweise grössere Mengen an Zigarettenfiltern und Snack-Verpackungen in der Nähe von Erhebungsorten mit einer höheren Konzentration von Flächen, die Gebäuden und Aktivitäten im Freien zugeordnet werden, festgestellt (siehe Landnutzungsprofil). Objekte, die mit dem Verzehr von Lebensmitteln, Getränken und Tabakwaren in Verbindung gebracht werden, machen etwa 26 % des gesamten Materials aus, das an den Schweizer Gewässern gefunden wurde.
Andere Objekte haben jedoch weder einen eindeutigen geografischen Ursprung noch eine klare Verbindung zu einer Aktivität in der Nähe ihres Erhebungsorts. Die häufigsten dieser Objekte machen ca. 40 % aller im Jahr 2020 identifizierten Abfallobjekte aus Seen und Fleissgewässer . Die Verringerung der Menge an Abfällen an den Schweizer Ufern beinhaltet auch die Verringerung der Menge an ausrangierten Objekten, die von ausserhalb der geografischen Grenzen des Ufers selbst stammen. Daher ist es ein Anreiz, Abfallobjekte, die an oder in der Nähe von Erhebungsorten weggeworfen werden zu unterscheiden von solchen, die in die Erhebungsorte eingetragen werden.
Die Gewinnung objektiver Daten über Uferabfälle wird durch die hydrologischen Einflüsse der rund 61 000 km Fliessgewässer und 1500 Seen in der Schweiz erschwert. Die hydrologischen Bedingungen der Fliessgewässer wirken sich auf die Entfernung und die Richtung aus, in der die in einen Fluss eingebrachten Objekte transportiert werden. Grosse Objekte mit geringer Dichte werden höchstwahrscheinlich zum nächsten Stausee oder in ein Gebiet mit geringerer Strömung transportiert. Objekte mit hoher Dichte werden nur dann transportiert, wenn die Fliessgeschwindigkeit und die Turbulenzen des Wassers ausreichen, um die Objekte vom Grund fernzuhalten. Sobald Objekte mit hoher Dichte in eine Zone mit geringer Strömungsgeschwindigkeit gelangen, neigen sie dazu, sich abzusetzen oder zu sinken. [SLBH19]
20.1.1. Die Ursprünge der häufigsten Objekte#
Die häufigsten Objekte sind die zehn mengenmässig am häufigsten vorkommenden Objekte und/oder Objekte, die in mindestens 50 % aller Datenerhebungen identifiziert wurden. Um besser zu verstehen, woher diese Objekte stammen, wird zwischen zwei Gruppen von Objekten unterschieden:
lokal entsorgte Objekte (leOs), die mehrere positive Assoziationen zu Landnutzungsmerkmalen haben, darunter eine Assoziation zu Gebäude-Flächen
Zigarettenstummel
Flaschenverschlüsse aus Metall
Snack-Verpackungen
Glasflaschen und -stücke
eingetragene Objekte (eOs, die wenige oder keine positiven Assoziationen zu Landnutzungsmerkmalen haben
Fragmentiertes expandiertes Polystyrol
Kunststoffgranulat für die Vorproduktion
Fragmentierte Kunststoffe
Wattestäbchen
Industrielle Abdeckungen
Baukunststoffe
Die Erhebungsorte werden unter Berücksichtigung der Landnutzungsprofile der umliegenden 1500 m betrachtet (siehe Landnutzungsprofil). Der Medianwert der Gebäudefläche wurde verwendet, um die Datenerhebungen in zwei verschiedene Gruppen zu unterteilen:
urban: Orte, an denen der prozentuale Anteil der bebauten Fläche grösser ist als der Median aller Datenerhebungen
ländlich: Orte, bei denen der prozentuale Anteil der bebauten Fläche kleiner ist als der Median aller Datenerhebungen und bei denen der prozentuale Anteil der bewaldeten oder landwirtschaftlich genutzten Fläche grösser ist als der Median
Im ländlichen Raum wurden 148 Datenerhebungen an 50 Erhebungsorten durchgefürt, im urbanen Raum 152 Datenerhebungen an 34 Erhebungsorten.
*Hinweis: Wattestäbchen sind bei den eingetragenen Objekten enthalten, da sie in der Regel über Wasseraufbereitungsanlagen in ein Gewässer gelangen.
Unten: Identifizierung von Gegenständen der Gruppe DG. DG ist eine vielfältige Gruppe von Gegenständen aus dem Bauwesen, der verarbeitenden Industrie und der Landwirtschaft. In einigen Fällen, wie z.B. bei zersplitterten Kunststoffen und geschäumten Kunststoffen, sind der ursprüngliche Gegenstand oder der Verwendungszweck unbestimmbar.

Abb. 20.2 #
Abbildung 20.2: Identifizierung von Objekten der Gruppe der eOs. EOs ist eine vielfältige Gruppe von Objekten aus dem Bauwesen, der verarbeitenden Industrie und der Landwirtschaft. In einigen Fällen, wie z. B. bei zersplitterten Kunststoffen und geschäumten Kunststoffen, sind der ursprüngliche Gegenstand oder der Verwendungszweck unbestimmbar.
Die Ergebnisse der verschiedenen Gruppen werden verwendet, um die folgende Nullhypothese zu testen, die auf den Ergebnissen des Korrelationskoeffizienten nach Spearman beruht.
Wenn es keine statistisch signifikanten Hinweise darauf gibt, dass Landnutzungsmerkmale zur Anhäufung eines Objekts beitragen, sollte die Verteilung dieses Objekts unter allen Landnutzungsbedingungen identisch oder fast identisch sein.
Nullhypothese: Es gibt keinen statistisch signifikanten Unterschied zwischen den Erhebungenergebnissen von eOs oder leOs in ländlichem und städtischem Umfeld.
Alternativhypothese: Es besteht ein statistisch signifikanter Unterschied zwischen den Erhebungenergebnissen von eOs oder leOs in ländlichem und städtischem Umfeld.
Methoden
Die Hypothese wird mit einer Kombination von nicht-parametrischen Tests getestet, um die Signifikanz zu bestätigen:
Kolmogorov-Smirnov-Test mit zwei Stichproben [sca]
Mann-Whitney-U-Test (MWU) [scb]
Bootstrap-Wiederholungsstichprobe Differenz der Mittelwerte [Efr87] [dry20]
20.2. Die Daten#
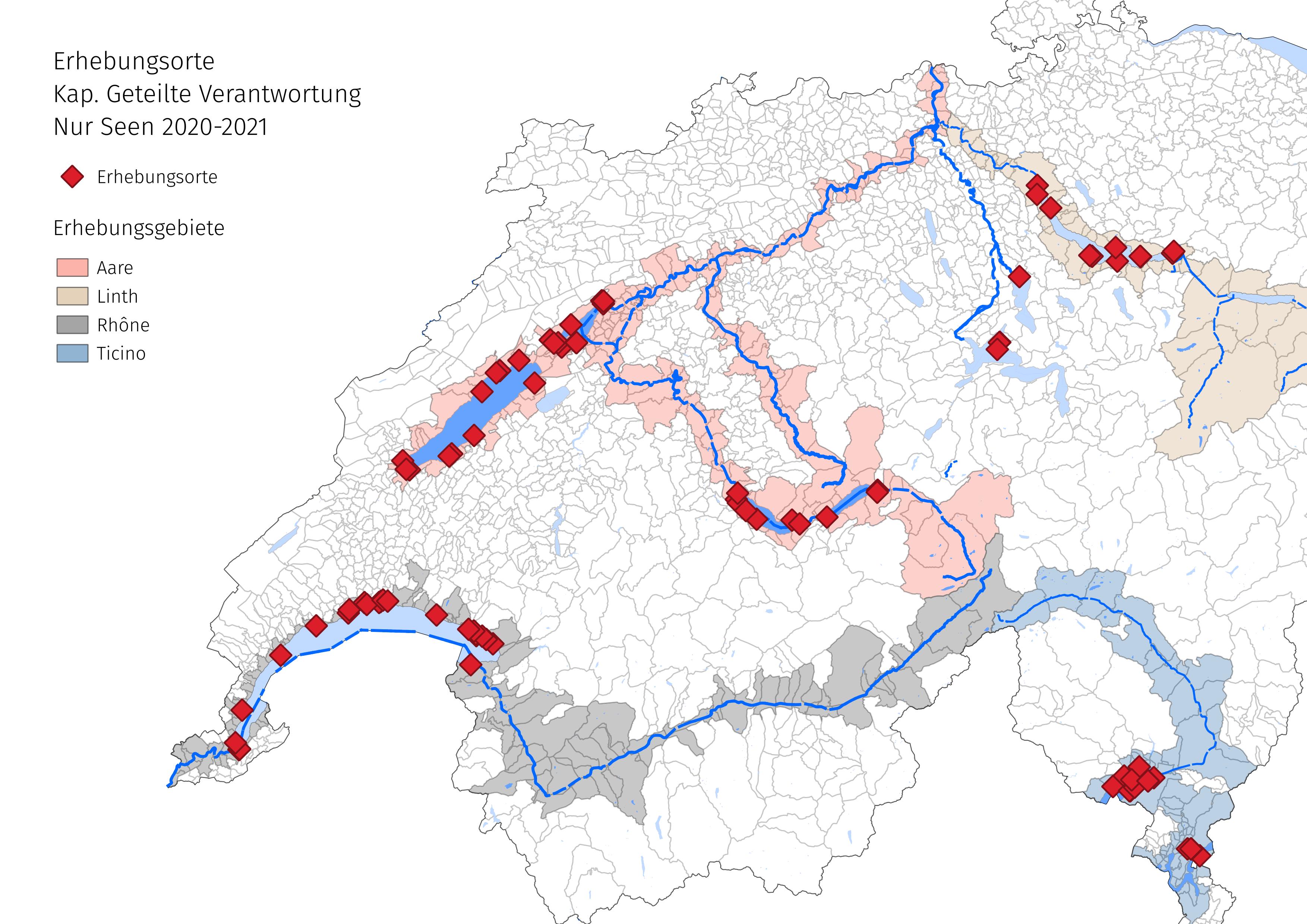
Abb. 20.3 #
Abbildung 20.3: Für diese Analyse wurden nur Erhebungsorte an Seen berücksichtigt. Das Walenseegebiet wurde mangels ausreichender Landnutzungsdaten ausgeschlossen. Damit reduziert sich der Datensatz auf 300 Erhebungen an 84 städtischen und ländlichen Erhebungsorten von März 2020 bis Mai 2021.
Show code cell source
# make date time
survey_data["date"] = pd.to_datetime(survey_data["date"], format=d)
# the land use data was unvailable for these municipalities
no_land_use = ['Walenstadt', 'Weesen', 'Glarus Nord', 'Quarten']
# slice the data by start and end date, remove the locations with no land use data
use_these_args = ((survey_data["date"] >= start_date)&(survey_data["date"] <= end_date))
survey_data = survey_data[use_these_args].copy()
# slice date to working data
a_data = survey_data[(~survey_data.city.isin(no_land_use))].copy()
a_data.rename(columns={"p/100m":unit_label},inplace=True)
# summarize the data
nsamps = a_data.loc_date.nunique()
nlocs = a_data.location.nunique()
# column headers for the survey area data
a_data['survey area'] = a_data.river_bassin.map(lambda x:comp_labels[x])
# feature data
fd = a_data[a_data.w_t == "l"].copy()
# survey totals
ad_dt = a_data.groupby(['loc_date','location','river_bassin', 'water_name_slug','city','date', 'month', 'eom'], as_index=False).agg({unit_label:'sum', 'quantity':'sum'})
# map survey total quantity to loc_date
fd_dq = ad_dt[['loc_date', 'quantity']].set_index('loc_date')
t = {"locations":fd.location.unique(), "nsamples":fd.loc_date.nunique()}
# gather the dimensional data for the time frame from dfDims
fd_dims= dfDims[(dfDims.location.isin(t["locations"]))&(dfDims.date >= start_date)&(dfDims.date <= end_date)].copy()
# map the survey area name to the dims data record
m_ap_to_survey_area = fd[['location', 'river_bassin']].drop_duplicates().to_dict(orient='records')
a_new_map = {x['location']:x['river_bassin'] for x in m_ap_to_survey_area}
# cumulative statistics for each code
code_totals = sut.the_aggregated_object_values(fd, agg=agg_pcs_median, description_map=code_description_map, material_map=code_material_map)
most_abundant = code_totals.sort_values(by="quantity", ascending=False)[:10].index
# found greater than 50% of the time
common = code_totals[code_totals['fail rate'] >= 50].index
# the most common
most_common = list(set([*most_abundant, *common]))
# Two land classifications
rural = ["urban", "ländlich"]
# Two code groups
cgroups = ["eOs", "leOs"]
DG = "eOs"
CG = "leOs"
# Two object types
obj_groups = ["FP", "FT"]
# objects that are likely left on site
cont = ["G27", "G30", "G178", "G200"]
# the most common objects minus the objects
# that are most likely left on site
dist = list(set(most_common) - set(cont))
# the survey results are being split according to
# the median value of the selected land use rates
bld_med = fd["% to buildings"].median()
agg_med = fd["% to agg"].median()
wood_med = fd["% to woods"].median()
# rural locations are locations that
fd['rural'] = ((fd["% to woods"] >= wood_med) | (fd["% to agg"] >= agg_med) ) & (fd["% to buildings"] < bld_med)
fd['rural'] = fd['rural'].where(fd['rural'] == True, 'urban')
fd['rural'] = fd['rural'].where(fd['rural'] == 'urban', 'ländlich')
# labels for the two groups and a label to catch all the other objects
fd['group'] = 'other'
fd['group'] = fd.group.where(~fd.code.isin(dist), "eOs")
fd['group'] = fd.group.where(~fd.code.isin(cont), "leOs")
# survey totals of all locations with its land use profile (indifferent of land use)
initial = ['loc_date','date','streets', 'intersects']
fd_dt=fd.groupby(initial, as_index=False).agg(agg_pcs_quantity)
# survey totals of contributed and distributed objects,
second = ['loc_date', 'group', 'rural', 'date','eom', 'river_bassin','location', 'streets', 'intersects']
cg_dg_dt=fd.groupby(second, as_index=False).agg({unit_label:"sum", "quantity":"sum"})
# adding the survey total of all objects to each record
cg_dg_dt['dt']= cg_dg_dt.loc_date.map(lambda x:fd_dq.loc[[x], 'quantity'][0])
# calculating the % total of contributed and distributed at each survey
cg_dg_dt['pt']= cg_dg_dt.quantity/cg_dg_dt.dt
rural = cg_dg_dt[(cg_dg_dt['rural'] == 'ländlich')].location.unique()
urban = cg_dg_dt[(cg_dg_dt['rural'] == 'urban')].location.unique()
grt_dtr = cg_dg_dt.groupby(['loc_date', 'date','rural'], as_index=False)[unit_label].agg({unit_label:"sum"})
# months locator, can be confusing
# https://matplotlib.org/stable/api/dates_api.html
months = mdates.MonthLocator(interval=1)
months_fmt = mdates.DateFormatter("%b")
days = mdates.DayLocator(interval=7)
fig, axs = plt.subplots(1,2, figsize=(11,6), sharey=True)
group_palette = {"leOs":'magenta', "eOs":'teal', 'other':'tan'}
rural_palette = {'ländlich':'black', 'urban':'salmon' }
ax = axs[0]
sns.scatterplot(data=grt_dtr, x='date', y=unit_label, hue='rural', s=80, palette=rural_palette, alpha=0.6, ax=ax)
ax.set_ylim(0,grt_dtr[unit_label].quantile(.98)+50 )
ax.set_xlabel("")
ax.set_ylabel(unit_label, **ck.xlab_k14)
ax.xaxis.set_major_locator(months)
ax.xaxis.set_major_formatter(months_fmt)
ax.legend(title=" ")
axtwo = axs[1]
box_props = {
'boxprops':{'facecolor':'none', 'edgecolor':'black'},
'medianprops':{'color':'black'},
'whiskerprops':{'color':'black'},
'capprops':{'color':'black'}
}
sns.boxplot(data=grt_dtr, x='rural', y=unit_label, dodge=False, showfliers=False, ax=axtwo, **box_props)
sns.stripplot(data=cg_dg_dt,x='rural', y=unit_label, ax=axtwo, zorder=1, hue='group', palette=group_palette, jitter=.35, alpha=0.3, s=8)
axtwo.set_ylabel(unit_label, **ck.xlab_k14)
# ax.tick_params(which='both', axis='both', labelsize=0)
axtwo.tick_params(which='both', axis='both', labelsize=14)
axtwo.set_xlabel(" ")
plt.tight_layout()
figure_name = "descriptive_data"
sample_totals_file_name = f'{save_fig_prefix}{figure_name}.jpeg'
save_figure_kwargs.update({"fname":sample_totals_file_name})
plt.savefig(**save_figure_kwargs)
glue("descriptive_data", fig, display=False)
plt.close()
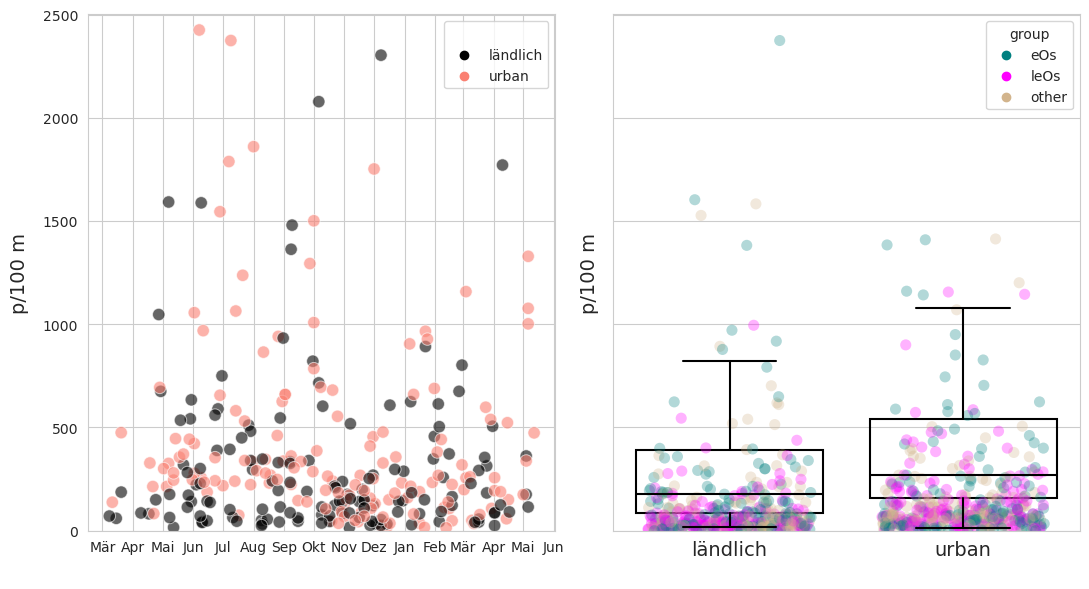
Abb. 20.4 #
Abbildung 20.4: Für diese Analyse wurden nur Erhebungsorte an Seen berücksichtigt. Das Walenseegebiet wurde mangels ausreichender Landnutzungsdaten ausgeschlossen. Damit reduziert sich der Datensatz auf 300 Erhebungen an 84 städtischen und ländlichen Erhebungsorten von März 2020 bis Mai 2021.
Show code cell source
change_names = {"count":"E",
"mean":"D",
"std":"S",
"min":"min",
"max": "max",
"25%":"25%",
"50%":"50%",
"75%":"75%",
"total objects":"Totalobjekte",
"# locations":"Anzahl der Standorte",
}
# convenience function to change the index names in a series
def anew_dict(x):
new_dict = {}
for param in x.index:
new_dict.update({change_names[param]:x[param]})
return new_dict
# select data
data = grt_dtr
# get the basic statistics from pd.describe
desc_2020 = data.groupby('rural')[unit_label].describe()
desc_2020.loc["Alle", ['count', 'mean', 'std', 'min', '25%', '50%', '75%', 'max']] = grt_dtr.groupby(['loc_date', 'date'])[unit_label].sum().describe().to_numpy()
desc = desc_2020.astype('int')
desc.rename(columns=(change_names), inplace=True)
desc = desc.applymap(lambda x: featuredata.thousandsSeparator(x))
desc.reset_index(inplace=True)
# make tables
fig, axs = plt.subplots(figsize=(7,3.4))
# summary table
# names for the table columns
a_col = [top_name[0], 'total']
axone = axs
sut.hide_spines_ticks_grids(axone)
a_table = sut.make_a_table(axone, desc.values, colLabels=desc.columns, colWidths=[.19,*[.1]*8], loc='lower center', bbox=[0,0,1,.95])
a_table.get_celld()[(0,0)].get_text().set_text(" ")
a_table.set_fontsize(14)
plt.tight_layout()
axone.set_xlabel("E = Erhebungen, D=Durchschnitt, S=Standardabweichung", labelpad=14, fontsize=14)
plt.subplots_adjust(wspace=0.2)
figure_name = "quantiles_rural_urban"
sample_totals_file_name = f'{save_fig_prefix}{figure_name}.jpeg'
save_figure_kwargs.update({"fname":sample_totals_file_name})
plt.savefig(**save_figure_kwargs)
glue("quantiles_rural_urban", fig, display=False)
plt.close()
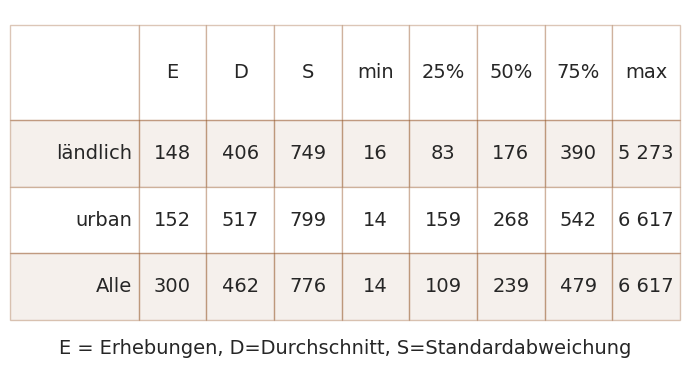
Abb. 20.5 #
Abbildung 20.5: Unterschiede zwischen städtischen und ländlichen Datenerhebungen. Die Erhebungsergebnisse in ländlichen Gebieten hatten einen niedrigeren Median und Mittelwert als in städtischen Gebieten und in allen Gebieten zusammen. Die Höchst- und Mindestwerte sowie die höchste Standardabweichung wurden an städtischen Erhebungsorten verzeichnet. Die 95-Prozent-Konfidenzintervalle des Medianwertes der Erhebungsergebnisse in den Städten und auf dem Land überschneiden sich nicht, siehe auch Anhang.
20.2.1. Bewertung der Zusammensetzung: Das grosse Ganze#
Das Verhältnis von eOs insgesamt zu leOs insgesamt betrug in der ländlichen Gruppe 2,5, in der städtischen Gruppe 1,6. Bei allen Datenerhebungen in den ländlichen Gebieten war der Anteil der eOs an der Gesamtzahl in % höher. In den Städten sind die Anteile von eOs und leOs an der Gesamtzahl der Datenerhebungen fast gleich.
Proben aus ländlichen Gegenden wiesen einen grösseren Anteil an fragmentierten Kunststoffen, geschäumten Kunststoffen und Baukunststoffen auf.
Show code cell source
dists = cg_dg_dt[(cg_dg_dt.group == DG)][['loc_date', 'location','rural', unit_label]].set_index('loc_date')
conts = cg_dg_dt[(cg_dg_dt.group == CG)][['loc_date', 'location', 'rural', unit_label]].set_index('loc_date')
conts.rename(columns={unit_label:CG}, inplace=True)
dists.rename(columns={unit_label:DG}, inplace=True)
c_v_d = pd.concat([dists, conts], axis=0)
c_v_d['dt'] = c_v_d[DG]/c_v_d[CG]
# the ratio of dist to cont under the two land use conditions
ratio_of_d_c_agg = c_v_d[c_v_d.rural == 'ländlich'][DG].sum()/c_v_d[c_v_d.rural == 'ländlich'][CG].sum()
ratio_of_d_c_urb= c_v_d[c_v_d.rural == 'urban'][DG].sum()/c_v_d[c_v_d.rural == 'urban'][CG].sum()
# chart that
fig, ax = plt.subplots(figsize=(6,5))
# get the eCDF of percent of total for each object group under each condition
# p of t urban
co_agecdf = ECDF(cg_dg_dt[(cg_dg_dt.rural == 'urban')&(cg_dg_dt.group.isin([CG]))]["pt"])
di_agecdf = ECDF(cg_dg_dt[(cg_dg_dt.rural == 'urban')&(cg_dg_dt.group.isin([DG]))]["pt"])
# p of t rural
cont_ecdf = ECDF(cg_dg_dt[(cg_dg_dt.rural == 'ländlich')&(cg_dg_dt.group.isin([CG]))]["pt"])
dist_ecdf = ECDF(cg_dg_dt[(cg_dg_dt.rural == 'ländlich')&(cg_dg_dt.group.isin([DG]))]["pt"])
sns.lineplot(x=cont_ecdf.x, y=cont_ecdf.y, color='salmon', label="ländlich: leOs", ax=ax)
sns.lineplot(x=co_agecdf.x, y=co_agecdf.y, color='magenta', ax=ax, label="urban: leOs")
sns.lineplot(x=dist_ecdf.x, y=dist_ecdf.y, color='teal', label="ländlich: eOs", ax=ax)
sns.lineplot(x=di_agecdf.x, y=di_agecdf.y, color='black', label="urban: eOs", ax=ax)
ax.set_xlabel("% der Gesamtzahl der Befragten", **ck.xlab_k14)
ax.set_ylabel("% der Erhebungen", **ck.xlab_k14)
plt.legend(loc='lower right', title="% Gesamt")
figure_name = "assess_composition"
sample_totals_file_name = f'{save_fig_prefix}{figure_name}.jpeg'
save_figure_kwargs.update({"fname":sample_totals_file_name})
plt.savefig(**save_figure_kwargs)
glue("assess_composition", fig, display=False)
plt.close()
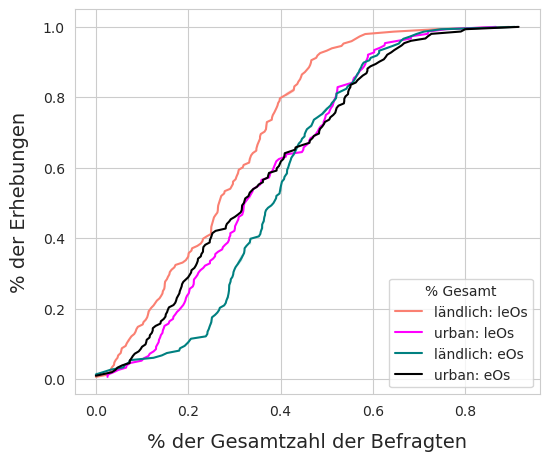
Abb. 20.6 #
Abbildung 20.6: Proben aus ländlichen Gegenden wiesen einen grösseren Anteil an fragmentierten Kunststoffen, geschäumten Kunststoffen und Baukunststoffen auf.
20.2.2. Verteilung der Datenerhebungen auf die verschiedenen Objektgruppen#
Die Erhebungsergebnisse der eOs sind unter beiden Landnutzungsklassen sehr ähnlich, es gibt mehr Varianz, wenn der gemeldete Wert steigt, aber nicht so viel, dass die Verteilungen auseinandergehen. Angesichts der Standardabweichung der Stichproben und der hohen Varianz der Datenerhebungen zum Ufer-Abfallaufkommen im Allgemeinen ist dies zu erwarten. [HG19]
Die Kolmogorov-Smirnov-Tests mit zwei Stichproben (ks = 0,073, p = 0,808) der beiden Gruppen von Datenerhebungen deuten darauf hin, dass sich die Erhebungsergebnisse der eOs zwischen den beiden Landnutzungsklassen möglicherweise nicht signifikant unterscheiden. Die Ergebnisse des Mann-Whitney-U-Tests (U = 11445,0, p = 0,762) deuten darauf hin, dass es möglich ist, dass die beiden Verteilungen gleich sind.
Show code cell source
# the dg group objects evaluated at rural locations
d_r_a = cg_dg_dt[(cg_dg_dt.rural == 'ländlich')&(cg_dg_dt.group == DG)].groupby(['loc_date', 'group'])[unit_label].sum()
dist_results_agg = d_r_a.values
a_d_ecdf = ECDF(dist_results_agg )
# the dg objects evaluated at urban locations
d_r_u = cg_dg_dt[(cg_dg_dt.rural == 'urban')&(cg_dg_dt.group == DG)].groupby(['loc_date', 'group'])[unit_label].sum()
dist_results_urb = d_r_u.values
b_d_ecdf = ECDF(dist_results_urb )
# the CG objects evaluated at ländlich locations
c_r_a = cg_dg_dt[(cg_dg_dt.rural == 'ländlich')&(cg_dg_dt.group == CG)].groupby('loc_date')[unit_label].sum()
cont_results_agg = c_r_a.values
a_d_ecdf_cont = ECDF(cont_results_agg)
# the CG objects evaluated at urban locations
c_r_u = cg_dg_dt[(cg_dg_dt.rural == 'urban')&(cg_dg_dt.group == CG)].groupby('loc_date')[unit_label].sum()
cont_results_urb = c_r_u.values
b_d_ecdf_cont = ECDF(cont_results_urb)
fig, ax = plt.subplots(1,2, figsize=(8,5))
axone = ax[0]
sns.lineplot(x=a_d_ecdf.x, y=a_d_ecdf.y, color='salmon', label="ländlich", ax=axone)
sns.lineplot(x=b_d_ecdf.x, y=b_d_ecdf.y, color='black', label="urban", ax=axone)
axone.set_xlabel(unit_label, **ck.xlab_k14)
axone.set_ylabel("% der Erhebungen", **ck.xlab_k14)
axone.legend(fontsize=12, title=DG,title_fontsize=14)
axtwo = ax[1]
sns.lineplot(x=a_d_ecdf_cont.x, y=a_d_ecdf_cont.y, color='salmon', label="ländlich", ax=axtwo)
sns.lineplot(x=b_d_ecdf_cont.x, y=b_d_ecdf_cont.y, color='black', label="urban", ax=axtwo)
axtwo.set_xlabel(unit_label, **ck.xlab_k14)
axtwo.set_ylabel(' ')
axtwo.legend(fontsize=12, title=CG,title_fontsize=14)
figure_name = "cg_dg_diff"
sample_totals_file_name = f'{save_fig_prefix}{figure_name}.jpeg'
save_figure_kwargs.update({"fname":sample_totals_file_name})
plt.savefig(**save_figure_kwargs)
glue(figure_name, fig, display=False)
plt.close()
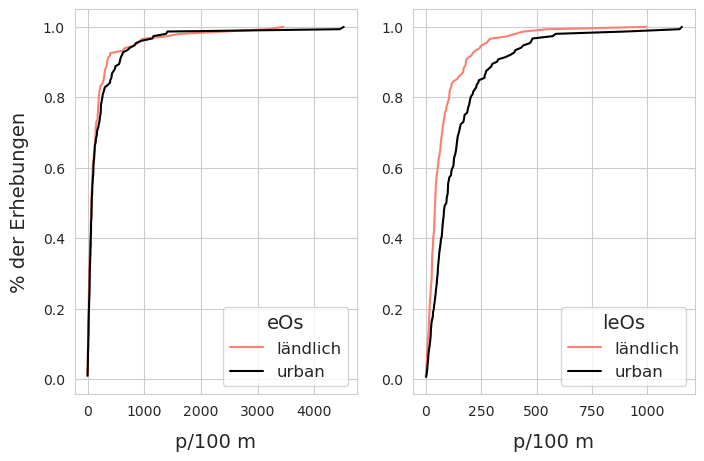
Abb. 20.7 #
Abbildung 20.7: Empirische Verteilungsfunktion von eOs und leOs. Links: Es sei daran erinnert, dass zu den eOs fragmentierte Kunststoffe, Schaumstoffe, Kunststoffe für den Bau und Industriepellets gehören. Rechts: Die Erhebungsergebnisse für Zigarettenfilter und Snack-Verpackungen haben visuell unterschiedliche Verteilungen unter den beiden Landnutzungsbedingungen.
Nach dem KS-Test (Rho = 0,09, p = 0,48) gibt es keinen statistischen Grund für die Annahme, dass unter den unterschiedlichen Landnutzungsbedingungen mehr eOs gefunden werden, nach dem MWU-Test (MWU = 1039, p = 0,25) besteht die Chance, dass die Häufigkeit der eOs unabhängig vom Landnutzungsprofil gleich ist. Andererseits weichen die Erhebungsergebnisse von leOs fast sofort ab und die Ergebnisse des KS-Tests (Rho = 0,31, p < 0,001) und des MWU-Tests (MWU = 7305, p < 0,001) deuten darauf hin, dass die Verteilung dieser Objekte mit dem Anteil der Fläche, die von Gebäuden eingenommen wird, zusammenhängt.
20.2.2.1. Differenz der Mittelwerte#
Das durchschnittliche Ergebnis der Datenerhebungen von eOs in ländlichen Gebieten lag bei 202 p/100 m gegenüber 237 p/100 m in städtischen Gebieten, ein Unterschied von -35 p/100 m ist nur ein kleiner Bruchteil der Standardabweichung. Es wurde ein Permutationstest auf die Differenz der Mittelwerte unter der Bedingung ländlich–städtisch der Mittelwerte der Datenerhebungen durchgeführt.
Differenz der Mittelwerte eOs. \(\mu_{rural}\) - \(\mu_{urban}\), method = shuffle, permutations = 5000.
Show code cell source
# for display purposes: the results of the ks and MWU tests for DG objects
# print(stats.ks_2samp(dist_results_agg, dist_results_urb, alternative='two-sided', mode='auto'))
# print(stats.mannwhitneyu(dist_results_agg,dist_results_urb, alternative='two-sided'))
# for display purposes: the results of the ks and MWU tests for CG objects
# print(stats.ks_2samp(cont_results_agg, cont_results_urb, alternative='two-sided', mode='auto'))
# print(stats.mannwhitneyu(cont_results_agg, cont_results_urb, alternative='two-sided'))
# combine the DG results from both land use classess
agdg = pd.DataFrame(d_r_a.copy())
budg = pd.DataFrame(d_r_u.copy())
# label the urban and ländlich results
agdg["class"] = 'ländlich'
budg['class'] = 'urban'
# merge into one
dg_merg = pd.concat([agdg, budg], axis=0)
# store the mean per class
the_mean = dg_merg.groupby('class')[unit_label].mean()
# store the difference
mean_diff = the_mean.loc['ländlich'] - the_mean.loc['urban']
new_means=[]
# permutation resampling:
for element in np.arange(5000):
dg_merg['new_class'] = dg_merg['class'].sample(frac=1).values
b=dg_merg.groupby('new_class')["p/100 m"].mean()
new_means.append((b.loc['ländlich'] - b.loc['urban']))
emp_p = np.count_nonzero(new_means <= (the_mean.loc['ländlich'] - the_mean.loc['urban'])) / 5000
# chart the results
fig, ax = plt.subplots()
sns.histplot(new_means, ax=ax)
ax.set_title(F"$\u0394\mu$ = {np.round(mean_diff, 2)}, perm=5000, p={emp_p} ", **ck.title_k14)
ax.set_ylabel('Permutationen', **ck.xlab_k14)
ax.set_xlabel(f"$\mu$ ländlich={np.round(the_mean.loc['ländlich'], 2)} - $\mu$ urban={np.round(the_mean.loc['urban'], 2)}", **ck.xlab_k14)
figure_name = "diff_mean"
sample_totals_file_name = f'{save_fig_prefix}{figure_name}.jpeg'
save_figure_kwargs.update({"fname":sample_totals_file_name})
plt.savefig(**save_figure_kwargs)
glue("diff_mean", fig, display=False)
plt.close()
Oben: Verwerfen Sie die Nullhypothese, dass diese beiden Verteilungen gleich sein könnten. Die beobachtete Differenz der Mittelwerte liegt innerhalb des 95%-Intervalls der Bootstrap-Ergebnisse.
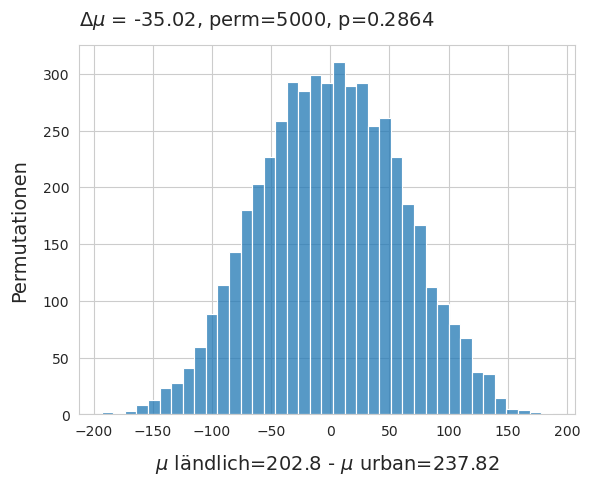
Abb. 20.8 #
Abbildung 20.8: Die Nullhypothese, dass diese beiden Verteilungen gleich sein könnten, ist zu verwerfen. Die beobachtete Differenz der Mittelwerte liegt innerhalb des 95-Prozent-Intervalls der Bootstrap-Ergebnisse.
20.3. Fazit#
Es kann ein positiver, statistisch relevanter Zusammenhang zwischen leOs und der Landnutzung angenommen werden, der auf Infrastruktur wie Strassen, Aktivitäten im Freien und Gebäude zurückzuführen ist. Mit 4/12 der häufigsten Objekte wurden etwa 26 % aller Objekte identifiziert und können mit Aktivitäten im Umkreis von 1500 m um den Erhebungsort in Verbindung gebracht werden.
Im Gegensatz dazu hat die Gruppe der eOs eine identische oder fast identische Verteilung unter den verschiedenen Landnutzungsklassen und keinen Zusammenhang mit dem prozentualen Anteil der Fläche, die Gebäuden zugeordnet ist. Die Gruppe eOs besteht aus Baukunststoffen, fragmentierten Schaumstoffen, Kunststoffstücken und Industriepellets und stellt eine vielfältige Gruppe von Objekten mit unterschiedlicher Dichte dar. Da es keine statistischen Beweise für das Gegenteil gibt, kann die Nullhypothese nicht verworfen werden. Daher kann nicht davon ausgegangen werden, dass die primäre Quelle in einem Umkreis von 1500 m um den Ort der Datenerhebungen liegt, und es ist wahrscheinlich, dass ein Teil dieser Objekte einen (wirtschaftlich und geografisch) weiter entfernten Ursprung hat.

Abb. 20.9 #
Abbildung 20.9: Festlegen objektiver Kriterien. Die Identifizierung und Quantifizierung von Objekten, die bei einer Datenerhebung über Abfälle gesammelt wurden, kann vor Ort erfolgen, wenn das Wetter es zulässt. Die Abmessungsdaten und die erste Bestandsaufnahme werden in einem Notizbuch dokumentiert und dann in die App The litter surveyor eingegeben. Objekte von Interesse: Plastikwatte, landwirtschaftliche Zäune und Abstandshalter für Ziegel.
20.3.1. Diskussion#
Durch den Vergleich der Erhebungsergebnisse mit den unabhängigen Variablen rund um die Erhebungsorte kann eine numerische Darstellung erstellt werden, die beschreibt, wie wahrscheinlich es ist, dass der Gegenstand dort weggeworfen wurde, wo er gefunden wurde. Die numerisch ermittelte Assoziation wird durch die tägliche Erfahrung verstärkt. Zum Beispiel wird ein Teil der Zigaretten und Snacks wahrscheinlich an oder in der Nähe der Verkaufsstellen konsumiert, und ein Teil des damit verbundenen Materials kann in die Umwelt gelangen.
Einige markante Objekte, die von relativ kleinen Teilen der Wirtschaft genutzt werden, können in einer ganzen Region identifiziert werden, sind aber aufgrund des hydrologischen Transports auf Zonen der Akkumulation beschränkt, was die Identifizierung der Quelle erschwert
Das vorangegangene Beispiel zeigt jedoch, dass sich Erhebungsergebnisse in Abhängigkeit von erklärenden Variablen erhöhen oder verringern. Bei Objekten wie Plastikpellets aus der Vorproduktion (GPI) ist der Verwendungszweck des Objekts eindeutig und die Nutzer und Hersteller sind im Vergleich zu anderen ausrangierten Objekten relativ selten. Auch wenn diese Objekte in allen Datenerhebungen vorkommen, ist es unwahrscheinlich, dass sie überall in gleichem Masse emittiert werden.
Anhand des vorangegangenen Beispiels lassen sich die steigenden Erhebungsergebnisse von GPI an zwei verschiedenen Seen verfolgen, um zu verstehen, wie diese Beziehung visualisiert werden kann.
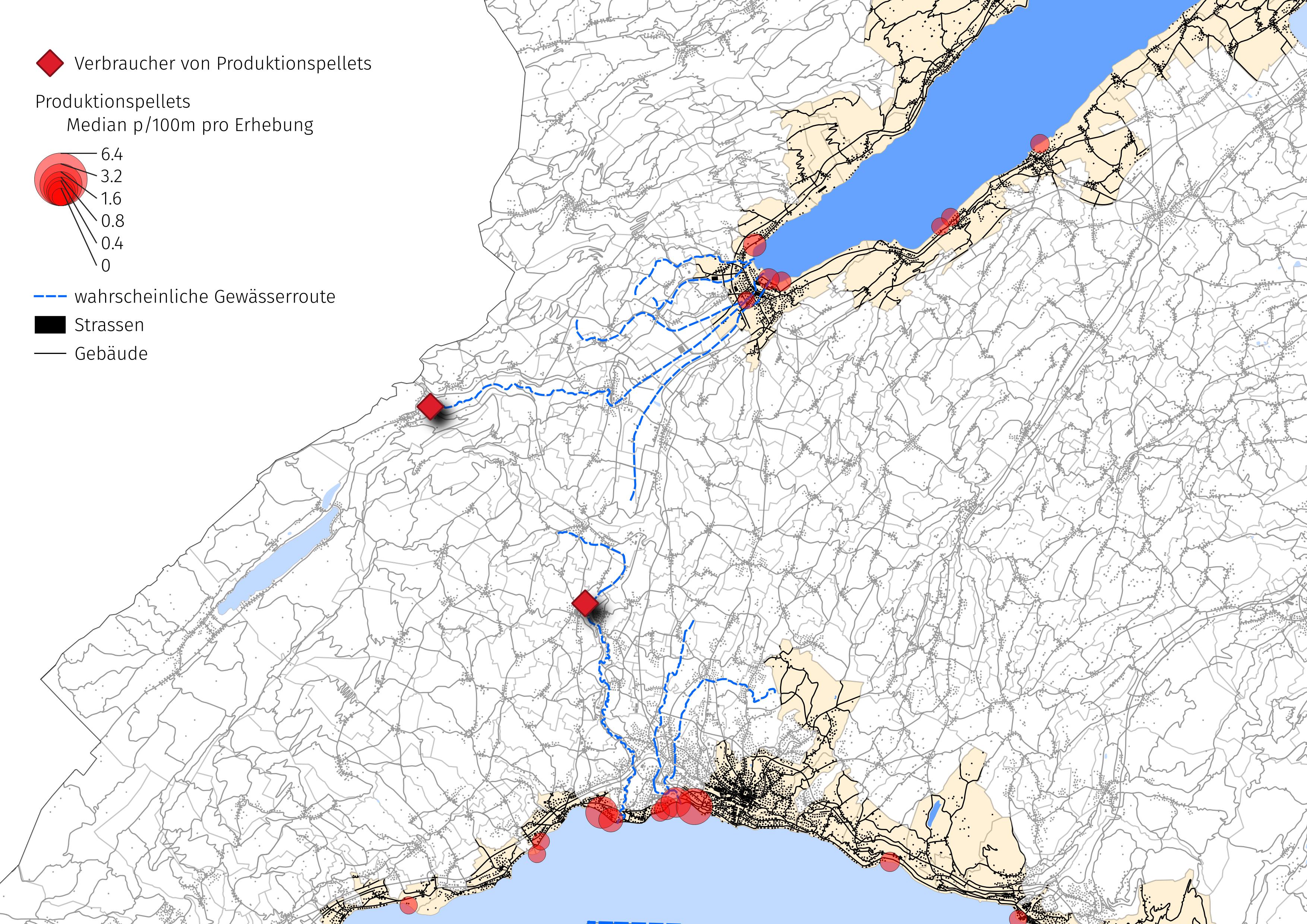
Abb. 20.10 #
Abbildung 20.10: Der Anstieg des mittleren p-pro-100-m-Wertes, wenn sich die Datenerhebungen der flussaufwärts gelegenen Quelle nähern. GPIs sind klein und schwer zu reinigen, wenn sie einmal verschüttet wurden, so dass die genaue Quelle schwer zu bestimmen ist. Man kann jedoch davon ausgehen, dass die Verarbeiter und Verbraucher von GPIs am besten wissen, wie man den Verlust von Material in die Umwelt verhindert. Die Wahrscheinlichkeit, mindestens einen GPI zu finden, ist an einigen der unten aufgeführten Orte doppelt so hoch wie die regionale Rate.
20.3.1.1. Partner finden#
Die Ergebnisse des Tests zeigen, dass leOs in städtischen Gebieten häufiger vorkommen. Als städtisch wurde die Landnutzung im Umkreis von 1500 m um das Untersuchungsgebiet definiert. Daraus lässt sich schliessen, dass die Ursache(n) für die Abfälle der leOs-Gruppe ebenfalls häufiger in städtischen Gebieten zu finden sind und dass die sekundäre Ursache für die ausrangierten Objekte in einem Umkreis von 1500 m um den Ort der Datenerhebungen liegt.
Akteure, die die Häufigkeit von leOs in einer bestimmten Zone reduzieren möchten, haben bessere Chancen, motivierte Partner in einem Umkreis von 1500 m um den betreffenden Ort zu finden.
Die eOs-Gruppe hat die Besonderheit, dass unabhängig von der Landnutzung verteilt ist und einen grösseren Anteil der gefundenen Objekte ausmacht als leOs. Dies deutet darauf hin, dass die Lösung ausserhalb der Gemeindegrenzen zu finden ist.
Fragmentierte Kunststoffe sind das einzige eO auf der Liste, das nicht mindestens einem Industriezweig zugeordnet werden kann, der in allen von dieser Analyse erfassten Datenerhebungen vertreten ist.
Expandiertes Polystyrol wird in der Bauindustrie als Aussenisolierung verwendet und dient als Verpackung, um zerbrechliche Objekte beim Transport zu schützen.
Kunststoff-Vorproduktionsgranulat wird für die Herstellung von Kunststoffobjekten im Spritzgussverfahren verwendet.
Wattestäbchen aus Plastik werden oft über Kläranlagen in Fliessgewässer und Seen geleitet.
Industriefolien werden in der Landwirtschaft, im Transportwesen und im Baugewerbe eingesetzt.
Baukunststoffe
Die Suche nach Partnern für diese Objekte kann eine erste Phase gezielter Kommunikation beinhalten. Dabei können IQAASL-Ergebnisse und die aktuellen EU-Grenzwerte und Grundlagen für Uferabfälle genutzt werden. [HG19]
20.3.1.2. Die Verantwortung teilen#
In einer kürzlich in der Zeitschrift Marine Policy veröffentlichten Studie wurden mehrere Einschränkungen bei der Verwendung bereits vorhandener Datenerhebungen über Strand-Abfallaufkommen zur Bewertung der Auswirkungen der EPR-Politik auf die beobachteten Abfallmengen festgestellt. [HLCM21]
In einer kürzlich in der Zeitschrift Marine Policy veröffentlichten Studie wurden mehrere Einschränkungen bei der Verwendung bereits vorhandener Datenerhebungen über Strand-Abfallaufkommen zur Bewertung der Auswirkungen der EPR-Politik auf die beobachteten Abfallmengen festgestellt.
Begrenzte Daten
Heterogene Methoden
Daten, die nicht zum Zweck der Bewertung des ERP erhoben wurden
Um diese Einschränkungen zu korrigieren, geben die Autoren die folgenden Empfehlungen:
Es ist ein Datenrahmen speziell für die Überwachung von ERP-Zielen zu erstellen.
Quellen sind zu identifizieren.
Um Basiswerte zu ermitteln, sind die Abfallobjekte zu zählen.
Häufige Überwachung
Die Zählung von Abfallobjekten mildert die Auswirkungen von Leichtverpackungen ab, wenn die Sammelergebnisse auf Gewichten basieren. [HLCM21]
Das IQAASl-Projekt geht auf drei der vier Empfehlungen ein und hat eine Methode eingeführt, die es den Beteiligten ermöglicht, dem Erhebungsprotokoll bestimmte Objekte hinzuzufügen. So kann die Überwachung des Fortschritts in Bezug auf die ERP-Ziele umgesetzt werden, solange die Objekte visuell definiert und gezählt werden können.
Die aktuelle Datenbank der Ufer-Abfallaufkommen-Untersuchungen in der Schweiz umfasst über 1000 Proben, die in den letzten sechs Jahren nach demselben Protokoll gesammelt wurden. Die Schweiz verfügt über alle Elemente, um die Mindestwahrscheinlichkeit für die häufigsten Objekte genau zu schätzen und stochastische Werte zu bewerten. Dieser Bericht bietet mehrere Möglichkeiten, die Unterschiede zwischen den Erhebungsrgebnissen zu bewerten, andere sollten ebenfalls in Betracht gezogen werden.
Eine nationale Strategie sollte Folgendes beinhalten:
Definition eines standardisierten Berichtsverfahrens für kommunale, kantonale und eidgenössische Akteure
Definition von Monitoring- oder Bewertungszielen
Formalisierung des Datenspeichers und der Methode zur Umsetzung auf den verschiedenen Verwaltungsebenen
Aufbau eines Netzwerks von Verbänden, die gemeinsam die Verantwortung und die Ressourcen für die Vermessung des Gebiets tragen
Entwicklung und Umsetzung eines formellen Ausbildungsprogramms für Vermessungsingenieure, das Datenwissenschaft und GIS-Technologien umfasst
Ermittlung des Forschungsbedarfs und Entwicklung idealer Stichproben-Szenarien in Zusammenarbeit mit akademischen Partnern
Entwicklung einer Finanzierungsmethode, die sicherstellt, dass pro Jahr und Region genügend Proben entnommen werden, um die Bedingungen genau zu bewerten und den Forschungsbedarf zu decken
20.4. Anhang#
Organisationen, die Proben gesammelt haben
Precious plastic leman
Association pour la sauvetage du Léman
Geneva international School
Solid waste management: École polytechnique fédérale Lausanne
Hamerdirt
Hackuarium
WWF Switzerland
20.4.1. Ergebnisse des Spearman-Rangkorrelationstests#
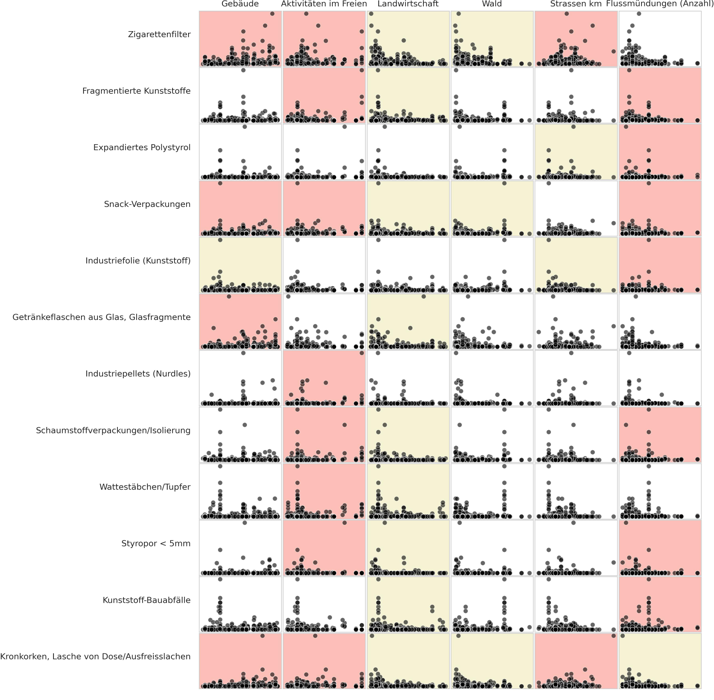
Eine Assoziation ist eine Beziehung zwischen den Datenerhebungen Ergebnissen und dem Landnutzungsprofil, die nicht auf Zufall beruht. Das Ausmass der Beziehung ist weder definiert noch linear.
Die Rangkorrelation ist ein nicht-parametrischer Test, um festzustellen, ob ein statistisch signifikanter Zusammenhang zwischen der Landnutzung und den in einer Datenerhebung identifizierten Objekten besteht.
Die verwendete Methode ist der Spearman’s rho oder Spearmans rangierter Korrelationskoeffizient. Die Testergebnisse werden bei p<0,05 für alle gültigen Seeproben im Untersuchungsgebiet ausgewertet.
Rot/Rose ist eine positive Assoziation
Gelb ist eine negative Assoziation
Weiss bedeutet, dass es bei p>0,05 keine statistische Grundlage für die Annahme eines Zusammenhangs gibt.
Unten: Rangfolge der häufigsten Objekte mit Landnutzungsmerkmalen.
Unten: 95% Konfidenzintervall des Medianwertes der Datenerhebungen unter den verschiedenen Landnutzungsklassen.
Show code cell source
# this code was modified from this source:
# http://bebi103.caltech.edu.s3-website-us-east-1.amazonaws.com/2019a/content/recitations/bootstrapping.html
# if you want to get the confidence interval around another point estimate use np.percentile
# and add the percentile value as a parameter
def draw_bs_sample(data):
"""Draw a bootstrap sample from a 1D data set."""
return np.random.choice(data, size=len(data))
def compute_jackknife_reps(data, statfunction=None, stat_param=False):
'''Returns jackknife resampled replicates for the given data and statistical function'''
# Set up empty array to store jackknife replicates
jack_reps = np.empty(len(data))
# For each observation in the dataset, compute the statistical function on the sample
# with that observation removed
for i in range(len(data)):
jack_sample = np.delete(data, i)
if not stat_param:
jack_reps[i] = statfunction(jack_sample)
else:
jack_reps[i] = statfunction(jack_sample, stat_param)
return jack_reps
def compute_a(jack_reps):
'''Returns the acceleration constant a'''
mean = np.mean(jack_reps)
try:
a = sum([(x**-(i+1)- (mean**-(i+1)))**3 for i,x in enumerate(jack_reps)])
b = sum([(x**-(i+1)-mean-(i+1))**2 for i,x in enumerate(jack_reps)])
c = 6*(b**(3/2))
data = a/c
except:
print(mean)
return data
def bootstrap_replicates(data, n_reps=1000, statfunction=None, stat_param=False):
'''Computes n_reps number of bootstrap replicates for given data and statistical function'''
boot_reps = np.empty(n_reps)
for i in range(n_reps):
if not stat_param:
boot_reps[i] = statfunction(draw_bs_sample(data))
else:
boot_reps[i] = statfunction(draw_bs_sample(data), stat_param)
return boot_reps
def compute_z0(data, boot_reps, statfunction=None, stat_param=False):
'''Computes z0 for given data and statistical function'''
if not stat_param:
s = statfunction(data)
else:
s = statfunction(data, stat_param)
return stats.norm.ppf(np.sum(boot_reps < s) / len(boot_reps))
def compute_bca_ci(data, alpha_level, n_reps=1000, statfunction=None, stat_param=False):
'''Returns BCa confidence interval for given data at given alpha level'''
# Compute bootstrap and jackknife replicates
boot_reps = bootstrap_replicates(data, n_reps, statfunction=statfunction, stat_param=stat_param)
jack_reps = compute_jackknife_reps(data, statfunction=statfunction, stat_param=stat_param)
# Compute a and z0
a = compute_a(jack_reps)
z0 = compute_z0(data, boot_reps, statfunction=statfunction, stat_param=stat_param)
# Compute confidence interval indices
alphas = np.array([alpha_level/2., 1-alpha_level/2.])
zs = z0 + stats.norm.ppf(alphas).reshape(alphas.shape+(1,)*z0.ndim)
avals = stats.norm.cdf(z0 + zs/(1-a*zs))
ints = np.round((len(boot_reps)-1)*avals)
ints = np.nan_to_num(ints).astype('int')
# Compute confidence interval
boot_reps = np.sort(boot_reps)
ci_low = boot_reps[ints[0]]
ci_high = boot_reps[ints[1]]
return (ci_low, ci_high)
the_bcas = {}
an_int = 50
# ländlich cis
r_median = grt_dtr[grt_dtr.rural == 'ländlich'][unit_label].median()
a_result = compute_bca_ci(grt_dtr[grt_dtr.rural == 'ländlich'][unit_label].to_numpy(), .05, n_reps=5000, statfunction=np.percentile, stat_param=an_int)
r_cis = {'ländlich':{"untere 2.5 %": a_result[0], "Median":r_median, "obere 97.5 %": a_result[1]}}
the_bcas.update(r_cis)
# urban cis
u_median = grt_dtr[grt_dtr.rural == 'urban'][unit_label].median()
a_result = compute_bca_ci(grt_dtr[grt_dtr.rural == 'urban'][unit_label].to_numpy(), .05, n_reps=5000, statfunction=np.percentile, stat_param=an_int)
u_cis = {'urban':{"untere 2.5 %":a_result[0], "Median":u_median, "obere 97.5 %": a_result[1]}}
the_bcas.update(u_cis)
# all surveys
u_median = grt_dtr[unit_label].median()
a_result = compute_bca_ci(grt_dtr[unit_label].to_numpy(), .05, n_reps=5000, statfunction=np.percentile, stat_param=an_int)
all_cis = {"alle":{"untere 2.5 %":a_result[0], "Median": u_median, "obere 97.5 %": a_result[1]}}
# combine the results:
the_bcas.update(all_cis)
# make a df
the_cis = pd.DataFrame.from_dict(the_bcas)
the_cis = the_cis.astype(int)
fig, axs = plt.subplots(figsize=(7,4))
data = the_cis.values
collabels = the_cis.columns
sut.hide_spines_ticks_grids(axs)
the_table = sut.make_a_table(axs, data, colLabels=collabels, colWidths=[*[.2]*3], bbox=[0, 0, 1, 1])
plt.show()
plt.close()
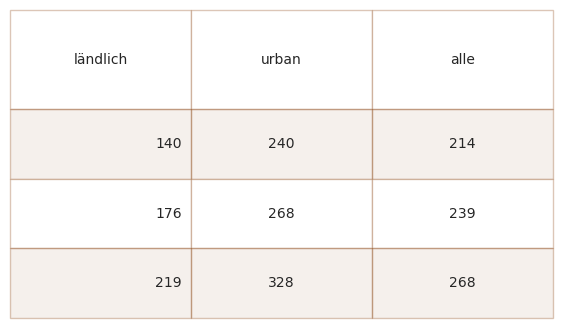
Unten: Die Erhebungsergebnisseder am häufigsten vorkommenden Objekte unter den beiden verschiedenen Landnutzungsklassen.
Show code cell source
rur_10 = fd[(fd.rural == 'ländlich')&(fd.code.isin(most_common))].groupby('code', as_index=False).quantity.sum().sort_values(by='quantity', ascending=False)
urb_10 = fd[(fd.rural == 'urban')&(fd.code.isin(most_common))].groupby('code', as_index=False).quantity.sum().sort_values(by='quantity', ascending=False)
rur_tot = fd[fd.location.isin(rural)].quantity.sum()
urb_tot = fd[fd.location.isin(urban)].quantity.sum()
rur_10['item'] = rur_10.code.map(lambda x: code_description_map.loc[x])
urb_10['item'] = urb_10.code.map(lambda x: code_description_map.loc[x])
rur_10["% of total"] = ((rur_10.quantity/rur_tot)*100).round(1)
urb_10["% of total"] = ((urb_10.quantity/urb_tot)*100).round(1)
# make tables
fig, axs = plt.subplots(2,1, figsize=(8,(len(most_common)*.6)*2))
# summary table
# names for the table columns
a_col = [top_name[0], 'total']
axone = axs[0]
axtwo = axs[1]
sut.hide_spines_ticks_grids(axone)
sut.hide_spines_ticks_grids(axtwo)
new_col_names = {"item":"Objekt","quantity":"Total (St.)", "% of total":"Total (%)"}
data_one = rur_10[['item', 'quantity', "% of total"]].copy()
data_one.rename(columns=new_col_names, inplace=True)
data_two = urb_10[['item', 'quantity', "% of total"]].copy()
data_two.rename(columns=new_col_names, inplace=True)
for a_df in [data_one, data_two]:
a_df["Total (St.)"] = a_df["Total (St.)"].map(lambda x: featuredata.thousandsSeparator(int(x)))
a_df["Total (%)"] = a_df["Total (%)"].map(lambda x: f"{int(x)}%")
first_table = sut.make_a_table(axone, data_one.values, colLabels=data_one.columns, colWidths=[.6,*[.2]*2], loc='lower center', bbox=[0,0,1,1])
first_table.get_celld()[(0,0)].get_text().set_text("ländlich")
a_table = sut.make_a_table(axtwo, data_two.values, colLabels=data_one.columns, colWidths=[.6,*[.2]*2], loc='lower center', bbox=[0,0,1,1])
a_table.get_celld()[(0,0)].get_text().set_text("urban")
plt.tight_layout()
plt.subplots_adjust(hspace=0.1)
plt.show()
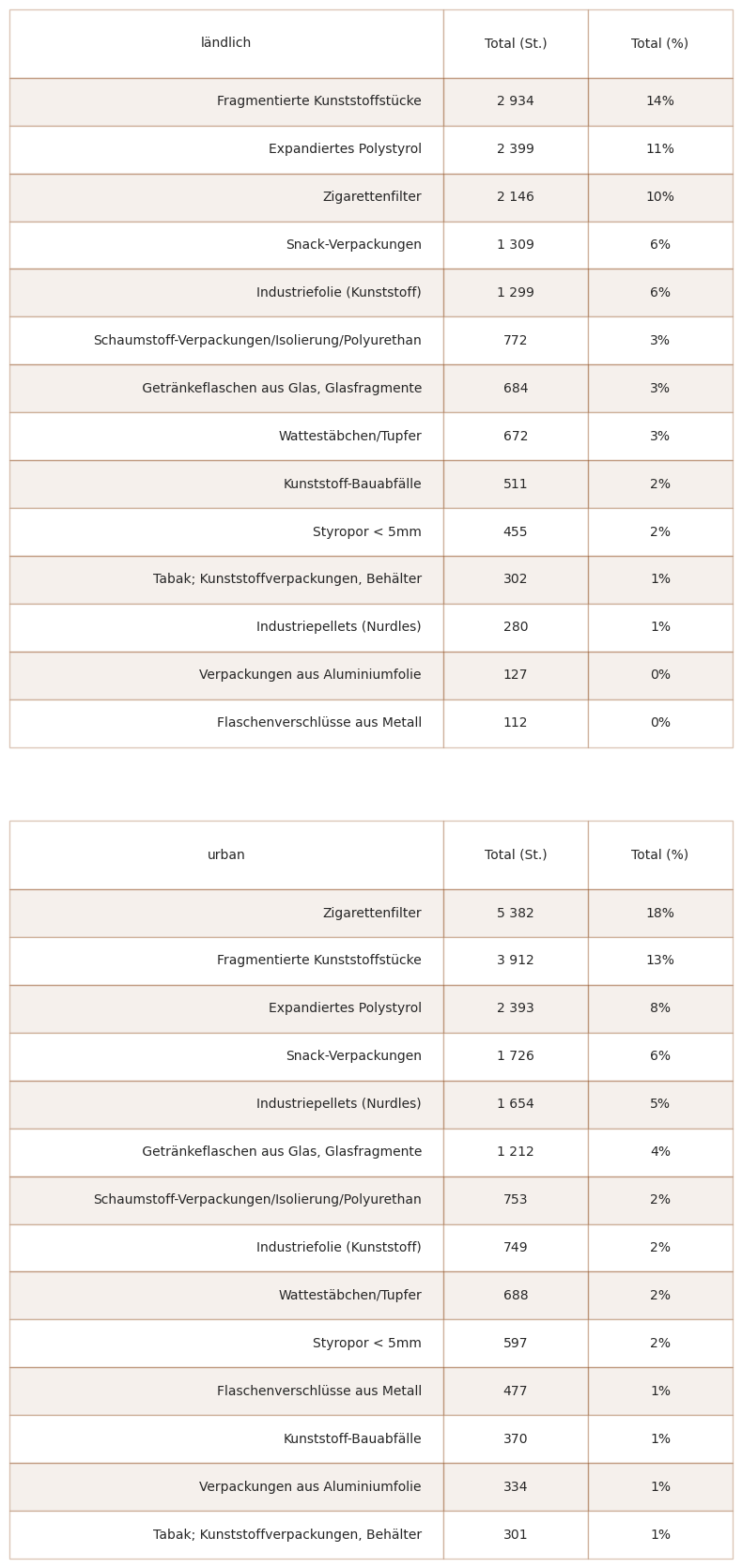
20.4.2. Saisonale Schwankungen#
Saisonale Schwankungen der Ergebnisse von Strand-Abfallaufkommen Untersuchungen sind unter verschiedenen Bedingungen und Umgebungen dokumentiert worden. Im Jahr 2018 meldete der SLR [Bla18] den Höchstwert im Juli und den Mindestwert im November. Für das Jahr 2020-2021 liegen die gleichen Ergebnisse vor.
Unten: monatliche Erhebungsergebnisseund Abflussmengen m³/Sekunde
April und Mai 2021 sind gleitende Durchschnitte, Daten nicht verfügbar
source : https://www.hydrodaten.admin.ch/en/stations-and-data.html?entrance_medium=menu
Show code cell source
# the survey results to test
corr_data = fd[(fd.code.isin(most_common))].copy()
results_sprmns = {}
for i,code in enumerate(most_common):
data = corr_data[corr_data.code == code]
for j, n in enumerate(luse_exp):
corr, a_p = stats.spearmanr(data[n], data[unit_label])
results_sprmns.update({code:{"rho":corr, 'p':a_p}})
# helper dict for converting ints to months
months={
0:'Jan',
1:'Feb',
2:"Mär",
3:'Apr',
4:'Mai',
5:'Jun',
6:'Jul',
7:'Aug',
8:'Sep',
9:'Okt',
10:'Nov',
11:'Dez'
}
# months_de={
# 0:"Jan",
# 1:"Feb",
# 2:"Mär",
# 3:"Apr",
# 4:"Mai",
# 5:"Jun",
# 6:"Jul",
# 7:"Aug",
# 8:"Sep",
# 9:"Okt",
# 10:"Nov",
# 11:"Dez"
# }
m_dt = fd.groupby(['loc_date', 'date','group'], as_index=False).agg({'quantity':'sum', unit_label:'sum'})
# sample totals all objects
m_dt_t = fd.groupby(['loc_date','date','month', 'eom'], as_index=False).agg({unit_label:'sum'})
m_dt_t.set_index('date', inplace=True)
# data montlhy median survey results contributed, distributed and survey total
fxi=m_dt.set_index('date', drop=True)
data1 = fxi[fxi.group == CG][unit_label].resample("M").mean()
data2 = fxi[fxi.group == DG][unit_label].resample("M").mean()
# helper tool for months in integer order
def new_month(x):
if x <= 11:
this_month = x
else:
this_month=x-12
return this_month
# the monthly average discharge rate of the three rivers where the majority of the samples are
aare_schonau = [61.9, 53, 61.5, 105, 161, 155, 295, 244, 150, 106, 93, 55.2, 74.6, 100, 73.6, 92.1]
rhone_scex = [152, 144, 146, 155, 253, 277, 317, 291, 193, 158, 137, 129, 150, 146, 121, 107]
linth_weesen = [25.3, 50.7, 40.3, 44.3, 64.5, 63.2, 66.2, 61.5, 55.9, 52.5, 35.2, 30.5, 26.1, 42.0, 36.9]
fig, ax = plt.subplots()
this_x = [i for i,x in enumerate(data1.index)]
this_month = [x.month for i,x in enumerate(data1.index)]
twin_ax = ax.twinx()
twin_ax.grid(None)
ax.bar(this_x, data1.to_numpy(), label="leOs", bottom=data2.to_numpy(), linewidth=1, color="salmon", alpha=0.6)
ax.bar([i for i,x in enumerate(data2.index)], data2.to_numpy(), label="eOs", linewidth=1,color="darkslategray", alpha=0.6)
sns.scatterplot(x=this_x,y=[*aare_schonau[2:], np.mean(aare_schonau)], color='turquoise', edgecolor='magenta', linewidth=1, s=60, label='Aare m³/Sek.', ax=twin_ax)
sns.scatterplot(x=this_x,y=[*rhone_scex[2:], np.mean(rhone_scex)], color='royalblue', edgecolor='magenta', linewidth=1, s=60, label='Rhône m³/Sek.', ax=twin_ax)
sns.scatterplot(x=this_x,y=[*linth_weesen[2:], np.mean(linth_weesen), np.mean(linth_weesen)], color='orange', edgecolor='magenta', linewidth=1, s=60, label='Linth m³/Sek.', ax=twin_ax)
handles, labels = ax.get_legend_handles_labels()
handles2, labels2 = twin_ax.get_legend_handles_labels()
ax.xaxis.set_major_locator(ticker.FixedLocator([i for i in np.arange(len(this_x))]))
ax.set_ylabel(unit_label, **ck.xlab_k14)
twin_ax.set_ylabel("m³/Sek.", **ck.xlab_k14)
axisticks = ax.get_xticks()
labelsx = [months[new_month(x-1)] for x in this_month]
plt.xticks(ticks=axisticks, labels=labelsx)
plt.legend([*handles, *handles2], [*labels, *labels2], bbox_to_anchor=(0,-.1), loc='upper left', ncol=2, fontsize=14)
plt.show()
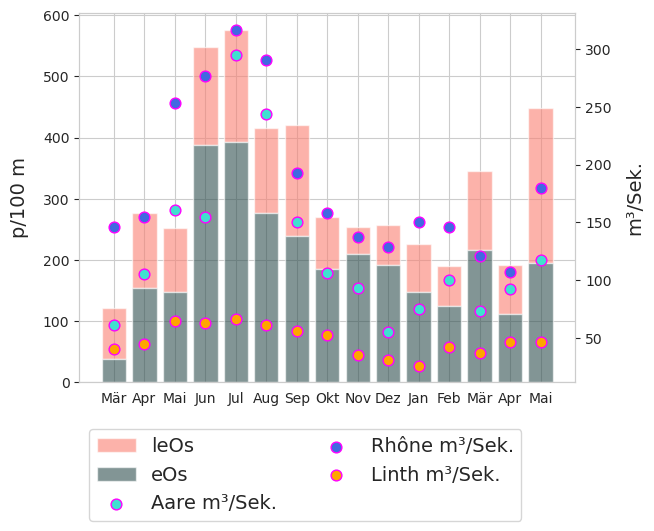
20.5. Die Erhebungsergebnissevon FP und FT in Bezug auf die Landnutzung#
FP = Fragmentierte Kunststoffstücke und Geschäumte Kunststoffe
FT = Zigaretten und Snack-Verpackungen
Ergebnisse von KS-Test und Mann Whitney U
Die Erhebungsergebnissefür FP Objekte sind sehr ähnlich bis zu \(\approxeq\) das 85. Perzentil, wo die Erhebungsergebnisseauf dem Land deutlich höher sind. Das deutet darauf hin, dass extreme Werte für FP in ländlichen Gebieten wahrscheinlicher waren. Nach dem KS-Test (ks=0,78, pvalue=0,69) und dem MWU-Test (U=10624, pvalue=0,40) ist die Verteilung der FP-Objekte unter den beiden Landnutzungsklassen nicht signifikant unterschiedlich und könnte gleich sein.
Die Erhebungsergebnissefür FT-Objekte behalten die gleichen Merkmale wie die der übergeordneten Verteilung. Die Ergebnisse des KS-Tests (ks=0,29, pWert<.001) und des MWU-Tests (U=7356,5, p<.001) stimmen mit den Ergebnissen der Elterngruppe überein, dass es einen statistisch relevanten Unterschied zwischen den Datenerhebungen Ergebnissen unter verschiedenen Landnutzungsklassen gibt.
Links: Land - Stadt: ECDF der Erhebungsergebnissefragmentierte Kunststoffe und Schaumstoffe (FP). Rechts: Land - Stadt: ECDF der ErhebungsergebnisseZigarettenstummel und Bonbonverpackungen (FT)
Show code cell source
agg_dobj = fd[(fd.rural == 'ländlich')&(fd.code.isin(['Gfrags', 'Gfoam']))].groupby(['loc_date'])[unit_label].sum().values
buld_obj = fd[(fd.rural == 'urban')&(fd.code.isin(['Gfrags', 'Gfoam']))].groupby(['loc_date'])[unit_label].sum().values
a_d_ecdf = ECDF(agg_dobj)
b_d_ecdf = ECDF(buld_obj)
agg_cont = fd[(fd.rural == 'ländlich')&(fd.code.isin(['G27', 'G30']))].groupby(['loc_date'])[unit_label].sum().values
b_cont = fd[(fd.rural == 'urban')&(fd.code.isin(['G27', 'G30']))].groupby(['loc_date'])[unit_label].sum().values
a_c_ecdf = ECDF(agg_cont)
b_c_ecdf = ECDF(b_cont)
fig, ax = plt.subplots(1,2, figsize=(8,5))
axone = ax[0]
sns.lineplot(x=a_d_ecdf.x, y=a_d_ecdf.y, color='salmon', label="ländlich", ax=axone)
sns.lineplot(x=b_d_ecdf.x, y=b_d_ecdf.y, color='black', label="urban", ax=axone)
axone.set_xlabel(unit_label, **ck.xlab_k14)
axone.set_ylabel('% der Erhebungen', **ck.xlab_k14)
axone.legend(fontsize=12, title='FP',title_fontsize=14)
axtwo = ax[1]
sns.lineplot(x=a_c_ecdf.x, y=a_c_ecdf.y, color='salmon', label="ländlich", ax=axtwo)
sns.lineplot(x=b_c_ecdf.x, y=b_c_ecdf.y, color='black', label="urban", ax=axtwo)
axtwo.set_xlabel(unit_label, **ck.xlab_k14)
axtwo.set_ylabel(' ')
axtwo.legend(fontsize=12, title='FT',title_fontsize=14)
plt.tight_layout()
plt.show()
20.5.1. FP und FT Differenz der Mittelwerte.#
Das durchschnittliche Datenerhebungsergebnis von FP-Objekten in ländlichen Gebieten lag bei 22,93p/50m in städtischen Gebieten bei 12p/50m. Es wurde ein Permutationstest auf die Differenz der Mittelwerte unter der Bedingung ländlich - städtisch durchgeführt.
Differenz der Mittelwerte von fragmentierten Schaumstoffen und Kunststoffen unter den beiden verschiedenen Landnutzungsklassen. \(\mu_{ländlich}\) - \(\mu_{urban}\), method=shuffle, permutations=5000*
Show code cell source
# pemutation test: of difference of means FP objects
agg_dobj = fd[(fd.rural == 'ländlich')&(fd.code.isin(['Gfrags', 'G89']))].groupby(['loc_date'], as_index=False)[unit_label].sum()
buld_obj = fd[(fd.rural == 'urban')&(fd.code.isin(['Gfrags', 'G89']))].groupby(['loc_date'], as_index=False)[unit_label].sum()
# label the urban and rural results
agg_dobj['class'] = 'ländlich'
buld_obj['class'] = 'urban'
# merge into one
objs_merged = pd.concat([agg_dobj, buld_obj])
# store the mean per class
the_mean = objs_merged.groupby('class')[unit_label].mean()
# store the difference
mean_diff = the_mean.loc['ländlich'] - the_mean.loc['urban']
new_means=[]
# permutation resampling:
for element in np.arange(5000):
objs_merged['new_class'] = objs_merged['class'].sample(frac=1).values
b=objs_merged.groupby('new_class')[unit_label].mean()
new_means.append((b.loc['ländlich'] - b.loc['urban']))
emp_p = np.count_nonzero(new_means <= (the_mean.loc['ländlich'] - the_mean.loc['urban'])) / 5000
# chart the results
fig, ax = plt.subplots()
sns.histplot(new_means, ax=ax)
ax.set_title(F"$\u0394\mu$ = {np.round(mean_diff, 2)}, perm=5000, p={emp_p} ", **ck.title_k14)
ax.set_ylabel('Permutationen', **ck.xlab_k14)
ax.set_xlabel("$\mu$ ländlich - $\mu$ urban", **ck.xlab_k14)
plt.show()
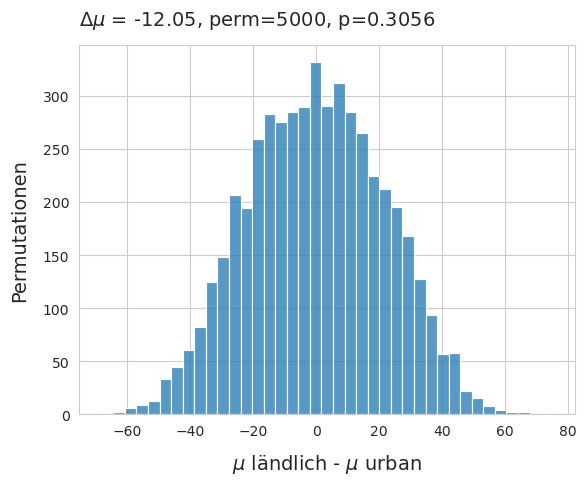
Oben: Verwerfen Sie die Nullhypothese: Es gibt keinen statistisch signifikanten Unterschied zwischen den beiden Verteilungen
Unten: Differenz der Mittelwerte für Zigarettenstummel und Snackverpackungen unter den beiden verschiedenen Landnutzungsklassen.
\(\mu_{länd;ich}\) - \(\mu_{urban}\), method=shuffle, permutations=5000
Show code cell source
# pemutation test: of difference of means food objects
agg_cont = fd[(fd.rural == 'ländlich')&(fd.code.isin(['G27', 'G30']))].groupby(['loc_date'], as_index=False)[unit_label].sum()
b_cont = fd[(fd.rural == 'urban')&(fd.code.isin(['G27', 'G30']))].groupby(['loc_date'], as_index=False)[unit_label].sum()
# label the urban and rural results
agg_cont['class'] = 'ländlich'
b_cont['class'] = 'urban'
# merge into one
objs_merged = pd.concat([agg_cont, b_cont])
# store the mean per class
the_mean = objs_merged.groupby('class')[unit_label].mean()
# store the difference
mean_diff = the_mean.loc['ländlich'] - the_mean.loc['urban']
# permutation resampling:
for element in np.arange(5000):
objs_merged['new_class'] = objs_merged['class'].sample(frac=1).values
b=objs_merged.groupby('new_class')[unit_label].mean()
new_means.append((b.loc['ländlich'] - b.loc['urban']))
emp_p = np.count_nonzero(new_means <= (the_mean.loc['ländlich'] - the_mean.loc['urban'])) / 5000
# chart the results
fig, ax = plt.subplots()
sns.histplot(new_means, ax=ax)
ax.set_title(F"$\u0394\mu$ = {np.round(mean_diff, 2)}, perm=5000, p={emp_p} ", **ck.title_k14)
ax.set_ylabel('Permutationen', **ck.xlab_k14)
ax.set_xlabel("$\mu$ ländlich - $\mu$ urban", **ck.xlab_k14)
plt.show()
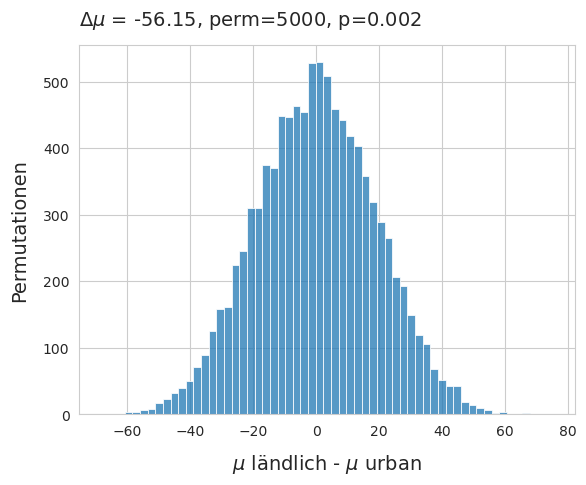
Oben: Verwerfen Sie die Nullhypothese: die beiden Verteilungen sind höchstwahrscheinlich nicht identisch.