Show code cell source
%load_ext watermark
# sys, file and nav packages:
import datetime as dt
import json
import functools
import time
from os import listdir
from os.path import isfile, join
# math packages:
import pandas as pd
import numpy as np
from scipy import stats
from statsmodels.distributions.empirical_distribution import ECDF
# charting:
import matplotlib as mpl
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
from matplotlib import ticker
from matplotlib import colors
from matplotlib.colors import LinearSegmentedColormap
from matplotlib.gridspec import GridSpec
from mpl_toolkits.axes_grid1 import make_axes_locatable
from mpl_toolkits.axes_grid1.inset_locator import inset_axes
import seaborn as sns
import IPython
from PIL import Image as PILImage
from IPython.display import Markdown as md
from IPython.display import display
from myst_nb import glue
import time
unit_label = 'p/100m'
# survey data:
dfx= pd.read_csv('resources/checked_sdata_eos_2020_21.csv')
dfBeaches = pd.read_csv("resources/beaches_with_land_use_rates.csv")
dfCodes = pd.read_csv("resources/codes_with_group_names_2015.csv")
# set the index of the beach data to location slug
dfBeaches.set_index('slug', inplace=True)
# set the index of to codes
dfCodes.set_index("code", inplace=True)
# code description map
code_d_map = dfCodes.description.copy()
# shorten the descriptions of two codes
code_d_map.loc["G38"] = "sheeting for protecting large cargo items"
code_d_map.loc["G73"] = "Foamed items & pieces (non packaging/insulation)"
# code material map
code_m_map = dfCodes.material
# this defines the css rules for the note-book table displays
header_row = {'selector': 'th:nth-child(1)', 'props': f'background-color: #FFF; text-align:right'}
even_rows = {"selector": 'tr:nth-child(even)', 'props': f'background-color: rgba(139, 69, 19, 0.08);'}
odd_rows = {'selector': 'tr:nth-child(odd)', 'props': 'background: #FFF;'}
table_font = {'selector': 'tr', 'props': 'font-size: 12px;'}
table_data = {'selector': 'td', 'props': 'padding: 6px;'}
table_css_styles = [even_rows, odd_rows, table_font, header_row]
pdtype = pd.core.frame.DataFrame
pstype = pd.core.series.Series
cmap = sns.diverging_palette(230, 20, as_cmap=True)
def scaleTheColumn(x):
xmin = x.min()
xmax = x.max()
xscaled = (x-xmin)/(xmax-xmin)
return xscaled
def collectAggregateValues(data: pd.DataFrame = None, locations: [] = None, columns: list = ["location", "OBJVAL"], to_aggregate: str = None):
return data[data.location.isin(locations)].groupby(columns, as_index=False)[to_aggregate].sum()
def pivotValues(aggregate_values, index: str = "location", columns: str = "OBJVAL", values: str = "surface"):
return aggregate_values.pivot(index=index, columns=columns, values=values).fillna(0)
def collectAndPivot(data: pd.DataFrame = None, locations: [] = None, columns: list = ["location", "OBJVAL"], to_aggregate: str = None):
# collects the geo data and aggregates the categories for a 3000 m hex
# the total for each category is the total amount for that category in the specific 3000 m hex
# with the center defined by the survey location.
aggregated = collectAggregateValues(data=data, locations=locations, columns=columns, to_aggregate=to_aggregate)
pivoted = pivotValues(aggregated, index=columns[0], columns=columns[1], values=to_aggregate)
pivoted.columns.name = "None"
return pivoted.reset_index(drop=False)
def resultsDf(rhovals: pdtype = None, pvals: pdtype = None)-> pdtype:
# masks the values of rho where p > .05
results_df = []
for i, n in enumerate(pvals.index):
arow_of_ps = pvals.iloc[i]
p_fail = arow_of_ps[ arow_of_ps > 0.05]
arow_of_rhos = rhovals.iloc[i]
for label in p_fail.index:
if arow_of_rhos[label] == 1:
pass
else:
arow_of_rhos[label] = 0
results_df.append(arow_of_rhos)
return results_df
def rotateText(x):
return 'writing-mode: vertical-lr; transform: rotate(-180deg); padding:10px; margins:0; vertical-align: baseline;'
def aStyledCorrelationTable(data, columns = ['Obstanlage', 'Reben', 'Siedl', 'Stadtzentr', 'Wald', 'k/n']):
rho = data[columns].corr(method='spearman')
pval = data[columns].corr(method=lambda x, y: stats.spearmanr(x, y)[1])
pless = pd.DataFrame(resultsDf(rho, pval))
pless.columns.name = None
bfr = pless.style.format(precision=2).set_table_styles(table_css_styles)
bfr = bfr.background_gradient(axis=None, vmin=rho.min().min(), vmax=rho.max().max(), cmap=cmap)
bfr = bfr.applymap_index(rotateText, axis=1)
return bfr
def addExceededTested(data, exceeded, passed, ratio, tested):
# merges the results of test threshold on to the survey results
data = data.merge(exceeded, left_on='location', right_index=True)
data = data.merge(passed, left_on='location', right_index=True)
data = data.merge(ratio, left_on="location", right_index=True)
data = data.merge(tested, left_on="location", right_index=True)
return data
def testThreshold(data, threshold, gby_column):
# given a data frame, a threshold and a groupby column
# the given threshold will be tested against the sum
# of aggregated value produced by aggregating on the
# groupby column
res_code["k"] = data.pcs_m >= threshold
exceeded = data.groupby([gby_column])['k'].sum()
exceeded.name = "k"
tested = data.groupby([gby_column]).loc_date.nunique()
tested.name = 'n'
passed = tested-exceeded
passed.name = "n-k"
ratio = exceeded/tested
ratio.name = 'k/n'
return exceeded, tested, passed, ratio
class CodeResults:
def __init__(self, data, attributes, column="pcs_m", method = stats.spearmanr):
self.code_data = data
self.attributes = attributes
self.column = column
self.x = self.code_data[column]
self.method = method
self.y = None
super().__init__()
def getRho(self, x: np.array = None)-> float:
# assigns y from self
result = self.method(x, self.y)
return result.correlation
def exactPValueForRho(self)-> float:
# perform a permutation test instead of relying on
# the asymptotic p-value. Only one of the two inputs
# needs to be shuffled.
p = stats.permutation_test((self.x,) , self.getRho, permutation_type='pairings', n_resamples=1000)
return p.pvalue
def rhoForAGroupOfAttributes(self):
# returns the results of the
# the correlation test, including
# a permutation test on p
rhos = []
code = self.code_data.code.unique()[0]
for attribute in self.attributes:
self.y = self.code_data[attribute].values
c= self.getRho(self.x)
p = self.exactPValueForRho()
# rhos.append({"code":code, "attribute":attribute, "c":c, "p":p.statistic})
return {"code":code, "attribute":attribute, "c":c, "p":p}
def rhoForAGroupOfAttributes(data, attributes, column="pcs_m"):
rhos = []
code = data.code.unique()[0]
for attribute in attributes:
p = CodeResults(data, [attribute],column=column).rhoForAGroupOfAttributes()
rhos.append(p)
return rhos
def cleanSurveyResults(data):
# performs data cleaning operations on the
# default data ! this does not remove
# Walensee ! The new map data is complete
data['loc_date'] = list(zip(data.location, data["date"]))
data['date'] = pd.to_datetime(data["date"])
# get rid of microplastics
mcr = data[data.groupname == "micro plastics (< 5mm)"].code.unique()
# replace the bad code
data.code = data.code.replace('G207', 'G208')
data = data[~data.code.isin(mcr)]
# walensee has no landuse values
# data = data[data.water_name_slug != 'walensee']
return data
class SurveyResults:
"""Creates a dataframe from a valid filename. Assigns the column names and defines a list of
codes and locations that can be used in the CodeData class.
"""
file_name = 'resources/checked_sdata_eos_2020_21.csv'
columns_to_keep=[
'loc_date',
'location',
'river_bassin',
'feature',
'city',
'w_t',
'intersects',
'code',
'pcs_m',
'quantity'
]
def __init__(self, data: str = file_name, clean_data: bool = True, columns: list = columns_to_keep, w_t: str = None):
self.dfx = pd.read_csv(data)
self.df_results = None
self.locations = None
self.valid_codes = None
self.clean_data = clean_data
self.columns = columns
self.w_t = w_t
def validCodes(self):
# creates a list of unique code values for the data set
conditions = [
isinstance(self.df_results, pdtype),
"code" in self.df_results.columns
]
if all(conditions):
try:
valid_codes = self.df_results.code.unique()
except ValueError:
print("There was an error retrieving the unique code names, self.df.code.unique() failed.")
raise
else:
self.valid_codes = valid_codes
def surveyResults(self):
# if this method has been called already
# return the result
if self.df_results is not None:
return self.df_results
# for the default data self.clean data must be called
if self.clean_data is True:
fd = cleanSurveyResults(self.dfx)
# if the data is clean then if can be used directly
else:
fd = self.dfx
# filter the data by the variable w_t
if self.w_t is not None:
fd = fd[fd.w_t == self.w_t]
# keep only the required columns
if self.columns:
fd = fd[self.columns]
# assign the survey results to the class attribute
self.df_results = fd
# define the list of codes in this df
self.validCodes()
return self.df_results
def surveyLocations(self):
if self.locations is not None:
return self.locations
if self.df_results is not None:
self.locations = self.dfResults.location.unique()
return self.locations
else:
print("There is no survey data loaded")
return None
def makeACorrelationTable(data, columns, name=None, figsize=(6,9)):
corr = data[columns].corr()
mask = np.triu(np.ones_like(corr, dtype=bool))
# Set up the matplotlib figure
f, ax = plt.subplots(figsize=figsize)
# Generate a custom diverging colormap
cmap = sns.diverging_palette(230, 20, as_cmap=True)
# Draw the heatmap with the mask and correct aspect ratio
sns.heatmap(corr, mask=mask, cmap=cmap, vmax=.3, center=0,
square=True, linewidths=.5, cbar_kws={"shrink": .5}, ax=ax)
ax.tick_params(axis="x", which="both", labelrotation=90)
ax.tick_params(axis="y", which="both", labelrotation=0)
ax.set_ylabel("")
ax.set_xlabel("")
glue(name,f, display=False)
plt.close()
4. Rivers: new map data#
This document repeats the calculations in section three but only includes survey results from locations on river-banks.
There are no excluded regions
There is geo-data for all regions under consieration
The map data is from the most recent release from Swiss Geo Admin
4.1. Important changes#
The land-use categories are labeled differently. The new map data from swissTLM3d does not have the general class agriculture. Any un-labeled surface in the hex was accounted for by subsracting the total of all labeled categories from the surface area of the hex = 5’845’672:
# there are areas on the map that are not defined by a category.
# the total surface area of all categories is subtracted from the
# the surface area of a 3000m hex = 5845672
area_of_a_hex = 5845672
defined_land_cover= land_cover.groupby([ "river_bass","location", "lat","lon","city","feature"], as_index=False).surface.sum()
defined_land_cover["OBJVAL"] = "undefined"
defined_land_cover["surface"] = area_of_a_hex - defined_land_cover.surface
land_cover = pd.concat([land_cover, defined_land_cover])
4.1.1. Why is this important?#
Repeatability. The old map data was not available.
Ease of access for researches or stakeholders who wish to verify the results
Relevance: different map layers could be used but these are the most recent
4.1.2. Why is this better?#
The old map layers used grids of 100 m². The new map layers uses polygons.
There is no need to transform or manipulate the land-use data once the hex grid overlay is completed
A Hexagon not a circle: The buffer is a hexagon of 3’000 m, it is circumscribed by a circle r = 1’500 m. The hexagon allows for better scaling. There is a small loss in the total surface area under consideration. However, hexagonal grids are very easy to implement in QGIS, which means that calculations can be brought to scale quickly.
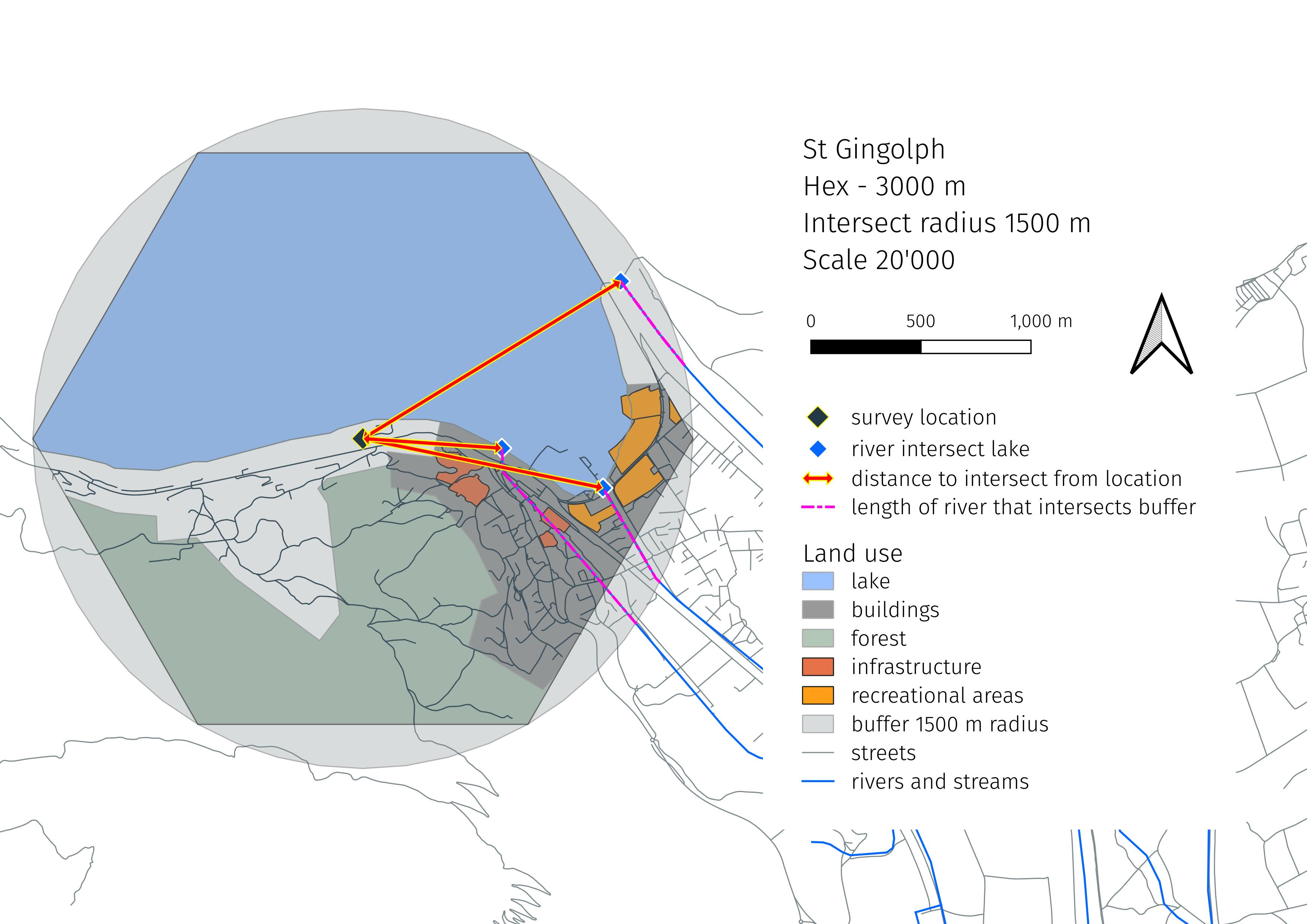
Fig. 4.1 A 3000 m Hex with land-use features#
The calculations are the same at each Geopraphic level. The number of samples and the mix of landuse attributes changes with every subset of data. It is those changes and how they relate to the magnitude of trash encountered that concerns these enquiries. This document assumes the reader knows what beach-litter monitoring is and how it applies to the health of the environment.
A statistical test is not a replacement for common sense. It is an another piece of evidence to consider along with the results from previous studies, the researchers personal experience as well as the history of the problem within the geographic constraints of the data.
4.1.3. Notes#
objects of interest
The objects of interest are defined as those objects where 20 or more were collected at one or more surveys. In reference to the default data: that is the value of the quantity column.
percent attributed to buildings
There are now multiple possible categories for buildings. The general category built surface is used as well as city center. There is another category that is specific to places of gathering or public use.
method of comparison
The total surface area of each category or subcategory is considered in relation to the survey results. This is a change from the previous sections where the % of total was considered.
4.2. The survey data#
The sampling period for the IQAASL project started in April 2020 and ended May 2021.
Show code cell source
# the SurveyResults class will collect the data in the
# resources data
# fdx = SurveyResults()
# call the surveyResults method to get the survey data
df = pd.read_csv('resources/surveys_iqaasl.csv')
df.code = df.code.replace('G207', 'G208')
# the lakes of interest
collection_points = [
'zurichsee',
'bielersee',
'neuenburgersee',
'walensee',
'vierwaldstattersee',
'brienzersee',
'thunersee',
'lac-leman',
'lago-maggiore',
'lago-di-lugano',
'zugersee'
]
# the data-frame of survey results to be considered
df = df[~df.feature.isin(collection_points)]
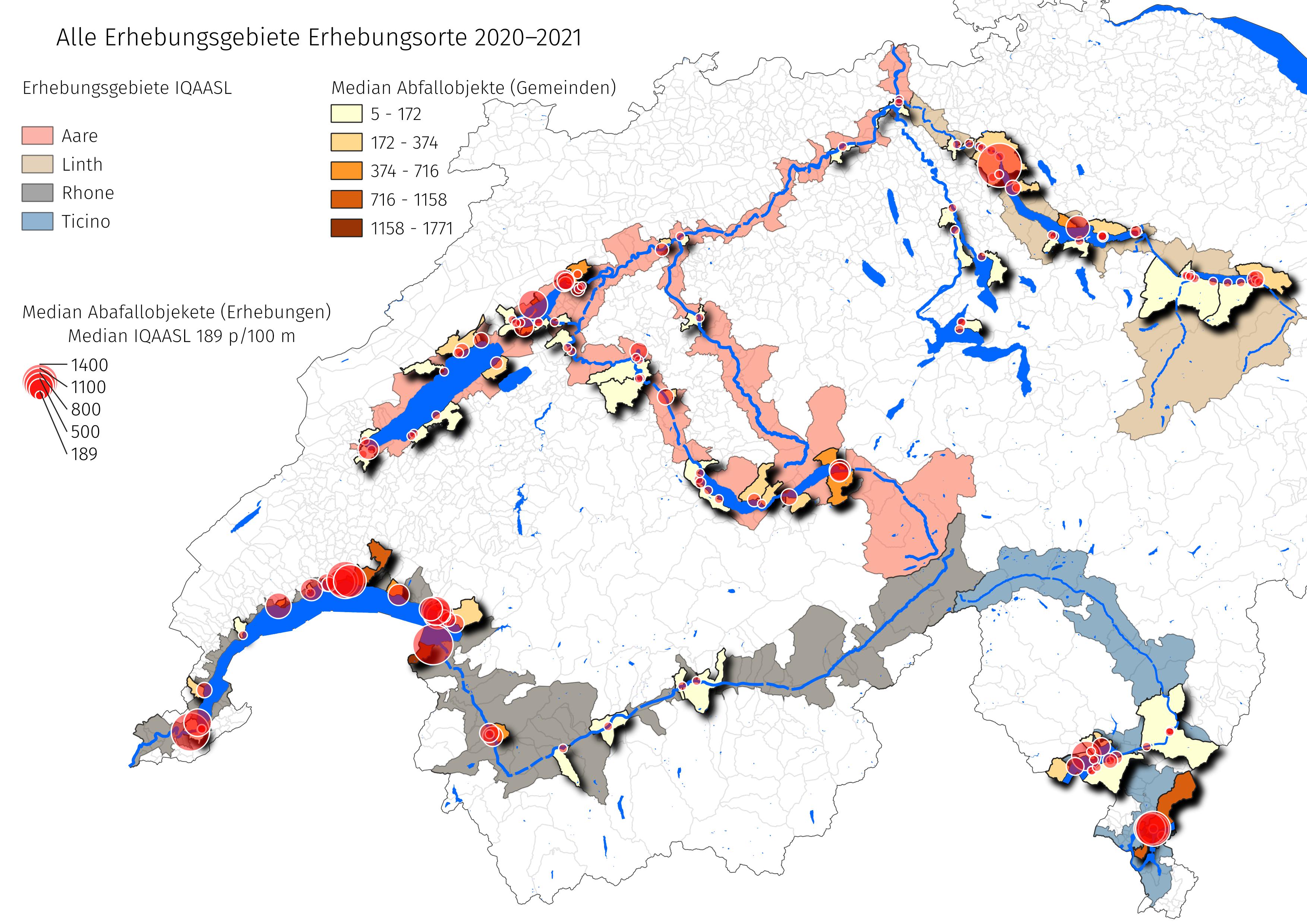
Fig. 4.2 #
figure 4.2: All survey locations IQAASL.
Show code cell source
## The survey results
locations = df.location.unique()
samples = df.loc_date.unique()
rivers = df[df.w_t == "r"].drop_duplicates("loc_date").w_t.value_counts().values[0]
codes_identified = df[df.quantity > 0].code.unique()
codes_possible = df.code.unique()
total_id = df.quantity.sum()
data_summary = {
"n locations": len(locations),
"n samples": len(samples),
"n lake samples": rivers,
"n identified object types": len(codes_identified),
"n possible object types": len(codes_possible),
"total number of objects": total_id
}
pd.DataFrame(index = data_summary.keys(), data=data_summary.values()).style.set_table_styles(table_css_styles)
| 0 | |
|---|---|
| n locations | 50 |
| n samples | 55 |
| n lake samples | 55 |
| n identified object types | 141 |
| n possible object types | 229 |
| total number of objects | 2475 |
4.3. The map data#
The proceeding is the land-use categories and the relevant sub-categories. With the exception of Land Cover the total of each category was considered for each hex. The covariance of each sub-category is given in the annex.
4.3.1. The base: Land cover#
This is how the earth is covered, independent of its use. The following categories are the base land-cover categories:
Orchard
Vineyards
Settlement
City center
Forest
Undefined
Wetlands
The area of each sub-category of land-cover within a 3000 m hex is totaled and the correlation is considered independently. The categories that follow are superimposed on to these surfaces.
Show code cell source
# recover the map data
mypath= "resources/hex-3000m/rivers/"
map_data = {f.split('.')[0]:pd.read_csv(join(mypath, f)) for f in listdir(mypath) if isfile(join(mypath, f))}
# fetch a map
land_cover = map_data["hex-3000-river-locations-landcover"]
land_cover.rename(columns={"undefined":"Undefined"}, inplace=True)
# from the data catalog:
# https://www.swisstopo.admin.ch/fr/geodata/landscape/tlm3d.html#dokumente
land_cover = land_cover[land_cover.location.isin(locations)]
# there are areas on the map that are not defined by a category.
# the total surface area of all categories is subtracted from the
# the surface area of a 3000m hex = 5845672
area_of_a_hex = 5845672
defined_land_cover= land_cover.groupby([ "river_bass","location","feature"], as_index=False).surface.sum()
defined_land_cover["OBJVAL"] = "Undefined"
defined_land_cover["surface"] = area_of_a_hex - defined_land_cover.surface
land_cover = pd.concat([land_cover, defined_land_cover])
# aggregate the geo data for each location
# the geo data for the 3000 m hexagon surrounding the survey location
# is aggregated into the labled categories, these records get merged with
# survey data, keyed on location
al_locations = collectAndPivot(data=land_cover, locations=land_cover.location.unique(), columns= ["location", "OBJVAL"], to_aggregate="surface")
# the result is a dataframe with the survey results and the geo data on one row
results = df.merge(al_locations, on="location", how='outer', validate="many_to_one")
codes = results[results.quantity > 20].code.unique()
value_columns = ['Obstanlage', 'Reben', 'Siedl', 'Stadtzentr', 'Wald', 'location', 'Undefined', 'Sumpf', 'feature', 'code']
y_column = ["pcs_m"]
unique_column = ["loc_date"]
collect_totals = {}
res_codes = [results[results.code == x][[*unique_column, *y_column, *value_columns]] for x in codes]
results_dfs = results.drop_duplicates("loc_date")
collect_totals.update({"land_cover":results_dfs})
# test rho for each category and code
# an itterative process that takes along time
rho_for_land_cover = [pd.DataFrame(rhoForAGroupOfAttributes(x,['Obstanlage', 'Reben', 'Wald','Sumpf', 'Siedl', 'Stadtzentr', 'Undefined'], column="pcs_m")) for x in res_codes]
rho_for_land_cover = pd.concat(rho_for_land_cover)
# select the pvalues and coefiecients:
ps = pd.pivot(rho_for_land_cover, columns="attribute", index="code", values="p")
rhos = pd.pivot(rho_for_land_cover, columns="attribute", index="code", values="c")
# mask out the results with p > .05
landcover = pd.DataFrame(resultsDf(rhos, ps))
landcover.columns.name = None
landcover.index.name = None
# this defines the css rules for the correlation tables
table_font = {'selector': 'tr', 'props': 'font-size: 14px;'}
table_data = {'selector': 'td', 'props': 'padding: 6px;'}
table_correlation_styles = [even_rows, odd_rows, table_font, header_row]
4.3.2. Streets#
# from the data catalog:
# https://www.swisstopo.admin.ch/fr/geodata/landscape/tlm3d.html#dokumente
# the road network has alot of detail, therefore there are
# alot of categories. We are interested in the effect of all
# methods that could lead to an object being dropped or forgotten
# near the location. We take the sum of all road types.
# the columns:
The different road sizes that are included.
10m road
1m path
2m path
2m path fragment
3m road
4m road
6m road
8m road
exit
highway
car road
sevice road
entrance
ferry
marked lane
square
rest area
link
access
We take the sum of the lengths of all street types within the 3’000 m hex.
Show code cell source
hex_data = map_data['hex-3000-river-locations-strasse']
# from the data catalog:
# https://www.swisstopo.admin.ch/fr/geodata/landscape/tlm3d.html#dokumente
# the road network has alot of detail, therefore there are
# alot of categories. We are interested in the effect of all
# methods that could lead to an object being dropped or forgotten
# near the location. We take the sum of all road types.
# the columns:
labels = [
'10m Strasse',
'1m Weg',
'1m Wegfragment',
'2m Weg',
'2m Wegfragment',
'3m Strasse',
'4m Strasse',
'6m Strasse',
'8m Strasse',
'Ausfahrt',
'Autobahn',
'Autostrasse',
'Dienstzufahrt',
'Einfahrt',
'Faehre',
'Markierte Spur',
'Platz',
'Raststaette', 'Verbindung', 'Zufahrt'
]
# the label for the total
total_column = "strasse"
# the geo data and survey data are merged on location
merge_column = "location"
# parameter of interest from the geo data
measure = "length"
# the independent variables of interest
value_columns = [total_column, merge_column, 'code']
# the value of interest
y_column = ["pcs_m"]
# the unique identifier for each survey
unique_column = ["loc_date"]
# the column labels from the geo data
data_columns = [merge_column, "OBJVAL"]
al_hex_data = collectAndPivot(data=hex_data, locations=hex_data.location.unique(), columns=data_columns, to_aggregate=measure)
strasse_data = al_hex_data.copy()
al_hex_data["strasse"] = al_hex_data[al_hex_data.columns[2:]].sum(axis=1)
results = df.merge(al_hex_data, on=merge_column, how='outer', validate="many_to_one")
# results[total_column] = results[labels].sum(axis=1)
res_codes = [results[results.code == x][[*unique_column, *y_column, *value_columns]] for x in codes]
results_dfs = results.drop_duplicates("loc_date")
collect_totals.update({"streets":results_dfs})
rho_for_hex_data = [pd.DataFrame(rhoForAGroupOfAttributes(x,[total_column], column="pcs_m")) for x in res_codes]
rho_for_hex_data = pd.concat(rho_for_hex_data)
ps = pd.pivot(rho_for_hex_data, columns="attribute", index="code", values="p")
rhos = pd.pivot(rho_for_hex_data, columns="attribute", index="code", values="c")
strasse = pd.DataFrame(resultsDf(rhos, ps))
strasse.columns.name = None
4.3.3. Recreation and sports#
This is all sporting and recreation areas. Includes camping and swimming pools.
# from the data catalog:
# https://www.swisstopo.admin.ch/fr/geodata/landscape/tlm3d.html#dokumente
# Cette Feature Class répertorie des surfaces destinées aux loisirs ou au sport. Des superpositions
# entre des polygones avec des types d’objets différents sont autorisées.
# these are areas for recreation and sports. They are superimposed over other polygons
# like buildings or cities. We are taking the total surface area
swimming pool
campsite
parade ground, festival area
golf course
sports field
zoo
recreation area
The surface area of these attributes are combined
Show code cell source
hex_data = map_data['hex-3000-river-locations-freizeitareal']
# from the data catalog:
# https://www.swisstopo.admin.ch/fr/geodata/landscape/tlm3d.html#dokumente
# Cette Feature Class répertorie des surfaces destinées aux loisirs ou au sport. Des superpositions
# entre des polygones avec des types d’objets différents sont autorisées.
# these are areas for recreation and sports. They are superimposed over other polygons
# like buildings or cities. We are taking the total surface area
labels = hex_data.OBJEKTART.unique()
# the label for the total
total_column = "freizeitareal"
# the geo data and survey data are merged on location
merge_column = "location"
# parameter of interest from the geo data
measure = "surface"
# the independent variables of interest
value_columns = [*labels, "freizeitareal",'location', 'code']
# the value of interest
y_column = ["pcs_m"]
# the unique identifier for each survey
unique_column = ["loc_date"]
# the column labels from the geo data
data_columns = [merge_column, "OBJEKTART"]
al_hex_data = collectAndPivot(data=hex_data, locations=hex_data.location.unique(), columns=data_columns, to_aggregate=measure)
recreation_data = al_hex_data.copy()
results = df.merge(al_hex_data, on=merge_column, how='outer', validate="many_to_one")
results[total_column] = results[labels].sum(axis=1)
res_codes = [results[results.code == x][[*unique_column, *y_column, *value_columns]] for x in codes]
results_dfs = results.drop_duplicates("loc_date")
collect_totals.update({"recreation":results_dfs})
rho_for_hex_data = [pd.DataFrame(rhoForAGroupOfAttributes(x,[total_column], column="pcs_m")) for x in res_codes]
rho_for_hex_data = pd.concat(rho_for_hex_data)
ps = pd.pivot(rho_for_hex_data, columns="attribute", index="code", values="p")
rhos = pd.pivot(rho_for_hex_data, columns="attribute", index="code", values="c")
freizeitareal = pd.DataFrame(resultsDf(rhos, ps))
freizeitareal.columns.name = None
4.3.4. Public use#
These are places like schools, hospitals, official parks, cemeteries
# from the data catalog:
# https://www.swisstopo.admin.ch/fr/geodata/landscape/tlm3d.html#dokumente
# Cette Feature Class représente des surfaces utilisées à des fins
# spécifiques. Des superpositions entre des polygones avec des types d’objets différents sont autorisées.
# this is surface area for specific uses: schools, parks, cemeteries, hospitals.
# historical sites. We are taking the total
wastewater treatment
aboriculture
cemetery
historic area
gravel extraction
monastery
power plant
prison
fair/carnivals
public park
allotment garden
school/university
hospietal
quarry
maintenance facility
unmanaged forest
The surface area of these attributes are combined
Show code cell source
hex_data = map_data['hex-3000-river-locations-nutzungsareal']
hex_data = hex_data[~hex_data["OBJEKTART"].isin(["Obstanlage", "Reben"])]
# from the data catalog:
# https://www.swisstopo.admin.ch/fr/geodata/landscape/tlm3d.html#dokumente
# Cette Feature Class représente des surfaces utilisées à des fins
# spécifiques. Des superpositions entre des polygones avec des types d’objets différents sont autorisées.
# this is surface area for specific uses: schools, parks, cemeteries, hospitals.
# historical sites. We are taking the total
labels = [
'Abwasserreinigungsareal', 'Antennenareal', 'Baumschule',
'Deponieareal', 'Friedhof', 'Historisches Areal',
'Kehrichtverbrennungsareal', 'Kiesabbauareal', 'Klosterareal',
'Kraftwerkareal', 'Massnahmenvollzugsanstaltsareal', 'Messeareal',
'Oeffentliches Parkareal', 'Schrebergartenareal',
'Schul- und Hochschulareal', 'Spitalareal', 'Truppenuebungsplatz',
'Unterwerkareal', 'Wald nicht bestockt'
]
# the label for the total
total_column = "nutuzungsareal"
# the geo data and survey data are merged on location
merge_column = "location"
# parameter of interest from the geo data
measure = "surface"
# the independent variables of interest
value_columns = [*labels, "nutuzungsareal",'location', 'code']
# the value of interest
y_column = ["pcs_m"]
# the unique identifier for each survey
unique_column = ["loc_date"]
# the column labels from the geo data
data_columns = [merge_column, "OBJEKTART"]
al_hex_data = collectAndPivot(data=hex_data, locations=hex_data.location.unique(), columns=data_columns, to_aggregate=measure)
public_use = al_hex_data.copy()
results = df.merge(al_hex_data, on=merge_column, how='outer', validate="many_to_one")
results[total_column] = results[labels].sum(axis=1)
res_codes = [results[results.code == x][[*unique_column, *y_column, *value_columns]] for x in codes]
results_dfs = results.drop_duplicates("loc_date")
collect_totals.update({"public_use":results_dfs})
rho_for_hex_data = [pd.DataFrame(rhoForAGroupOfAttributes(x,[total_column], column="pcs_m")) for x in res_codes]
rho_for_hex_data = pd.concat(rho_for_hex_data)
ps = pd.pivot(rho_for_hex_data, columns="attribute", index="code", values="p")
rhos = pd.pivot(rho_for_hex_data, columns="attribute", index="code", values="c")
nutuzungsareal = pd.DataFrame(resultsDf(rhos, ps))
nutuzungsareal.columns.name = None
4.3.5. Length of river network and distance to intersection#
See section Condisder distance to river for the explanation on how these values are derived from the Geo data.
# from the data catalog:
# https://www.swisstopo.admin.ch/fr/geodata/landscape/tlm3d.html#dokumente
# Cette Feature Class répertorie les cours d’eau sous forme de lignes.
# Les lignes sont orientées dans le sens du courant.
# the intersect data is derived. the labels are from the rivers layer and the
# the survey points layer.
# permutation is not required here.
# there are > 900 records, each result is keyed
# to each intersection in the buffer. Therefore
# there are 983 records for each code.
def collectCorrelation(data, codes, columns):
results = []
for code in codes:
d = data[data.code == code]
dx = d.pcs_m.values
for name in columns:
dy = d[name].values
c, p = stats.spearmanr(dx, dy)
results.append({"code":code, "variable":name, "rho":c, "p":p})
return results
Show code cell source
# the intersect data
ind = pd.read_csv('resources/hex-3000m/rivers/river-locations-intersection_length.csv')
ind = ind.groupby('location', as_index=False).length.sum()
# merge the intersection data with the survey data
ints_and_data = df.merge(ind, on="location", how="outer")
# define the locations of interest
locations = df.location.unique()
data = ints_and_data[(ints_and_data.code.isin(codes)) & (ints_and_data.location.isin(locations))].copy()
data.groupby(["loc_date", "location"], as_index=False).length.sum()
data.fillna(0, inplace=True)
columns = [ "length"]
# permutation is not required here.
# there are > 900 records, each result is keyed
# to each intersection in the buffer. Therefore
# there are 983 records for each code.
def collectCorrelation(data, codes, columns):
results = []
for code in codes:
d = data[data.code == code]
dx = d.pcs_m.values
for name in columns:
dy = d[name].values
c, p = stats.spearmanr(dx, dy)
results.append({"code":code, "variable":name, "rho":c, "p":p})
return results
corellation_results = collectCorrelation(data, codes, columns)
crp = pd.DataFrame(corellation_results)
pvals = crp.pivot(index="code", columns="variable", values="p")
rhovals = crp.pivot(index="code", columns="variable", values="rho")
d_and_l = pd.DataFrame(resultsDf(rhovals, pvals))
# collect_totals.update({"distance": data[["loc_date", "distance"]]})
collect_totals.update({"length": data[["loc_date", "length"]]})
4.3.6. The number of river intersections#
The total number of river intersections within 1 500 m radius is considered. The number of intersections is from the previous map layer.
4.4. The land-use profile#
Show code cell source
# merge the derived land use values into a data frame
lc = collect_totals["land_cover"][['loc_date','Obstanlage', 'Reben', 'Wald','Sumpf', 'Siedl', 'Stadtzentr', 'Undefined']]
lc= lc.merge(collect_totals['public_use'][['loc_date', 'nutuzungsareal']], on="loc_date")
lc = lc.merge(collect_totals['recreation'][['loc_date', 'freizeitareal']], on="loc_date")
# format the m² and linear meters to km² and Km
lc[lc.columns[1:]] = lc[lc.columns[1:]] * 0.000001
lc = lc.merge(collect_totals['streets'][["loc_date", "strasse"]], on="loc_date")
lc[["strasse"]] = lc[["strasse"]]/1000
ic = collect_totals['length'][['loc_date', 'length']]
ic[["length"]] = ic[["length"]]/1000
ic.drop_duplicates(["loc_date"], inplace=True)
ic = ic.rename(columns={'length':'Length of river network [km]'})
icx=ic[["loc_date", "Length of river network [km]"]].set_index("loc_date")
lc["Length of river network [km]"] = lc.loc_date.apply(lambda x: icx.loc[f"{x}", "Length of river network [km]"])
column_names = {
"Obstanlage":"Orchard [km²]",
"Reben":"Vineyard [km²]",
"Wald":"Woods [km²]",
"Sumpf":"Wetlands [km²]",
"Stadtzentr":"City-center [km²]",
"Siedl":"Buildings/Urban [km²]",
"strasse":"Roads/streets [km]",
"freizeitareal":"Recreation/sports [km²]",
"nutuzungsareal":"Schools/infrastructure [km²]",
"Undefined":"Undefined [km²]",
"Length of river network [km]":"Length of river network [km]"
}
lc = lc.rename(columns=column_names)
# method to get the ranked correlation of pcs_m to each explanatory variable
def make_plot_with_spearmans(data, ax, n):
sns.scatterplot(data=data, x=n, y=unit_label, ax=ax, color='black', s=30, edgecolor='white', alpha=0.6)
corr, a_p = stats.spearmanr(data[n], data[unit_label])
return ax, corr, a_p
fig, axs = plt.subplots(3,4, figsize=(9,7), sharey=False)
data = lc
for i,n in enumerate(lc.columns[1:]):
column = i%4
row=i%3
ax = axs[row, column]
# the ECDF of the land use variable
the_data = ECDF(data[n].values)
sns.lineplot(x=the_data.x, y= (the_data.y), ax=ax, color='dodgerblue', label="cumulative distribution" )
# get the median % of land use for each variable under consideration from the data
the_median = data[n].median()
# plot the median and drop horzontal and vertical lines
ax.scatter([the_median], .5, color='red',s=50, linewidth=2, zorder=100, label="the median")
ax.vlines(x=the_median, ymin=0, ymax=.5, color='red', linewidth=2)
ax.hlines(xmax=the_median, xmin=0, y=0.5, color='red', linewidth=2)
#remove the legend from ax
ax.get_legend().remove()
if column == 0:
ax.set_ylabel("Share of \nsurveys [%]", labelpad = 15)
else:
ax.set_yticks([])
# add the median value from all locations to the ax title
ax.set_title(f'{n}\nmedian={round(the_median, 2)}',fontsize=10, loc='left')
ax.set_xlabel(" ")
ax.set_ylim(0,1)
for anax in [axs[2,3]]:
anax.grid(False)
anax.set_xticks([])
anax.set_yticks([])
anax.spines["top"].set_visible(False)
anax.spines["right"].set_visible(False)
anax.spines["bottom"].set_visible(False)
anax.spines["left"].set_visible(False)
h, l = ax.get_legend_handles_labels()
axs[2,3].legend(h,l, loc="center", bbox_to_anchor=(.5,.5))
plt.tight_layout()
glue("the_land_use_profile", fig, display=False)
plt.close()
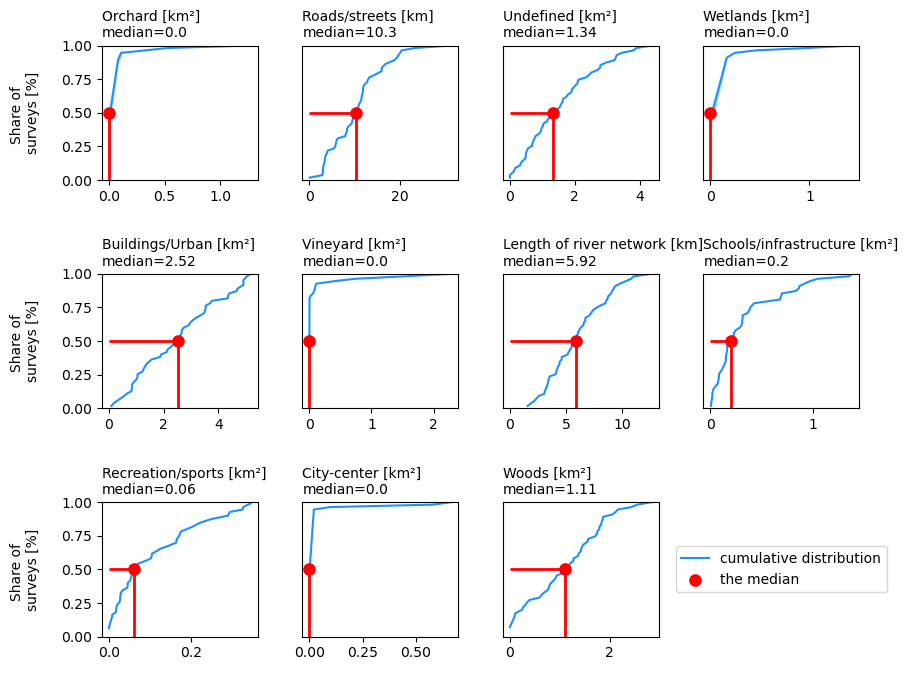
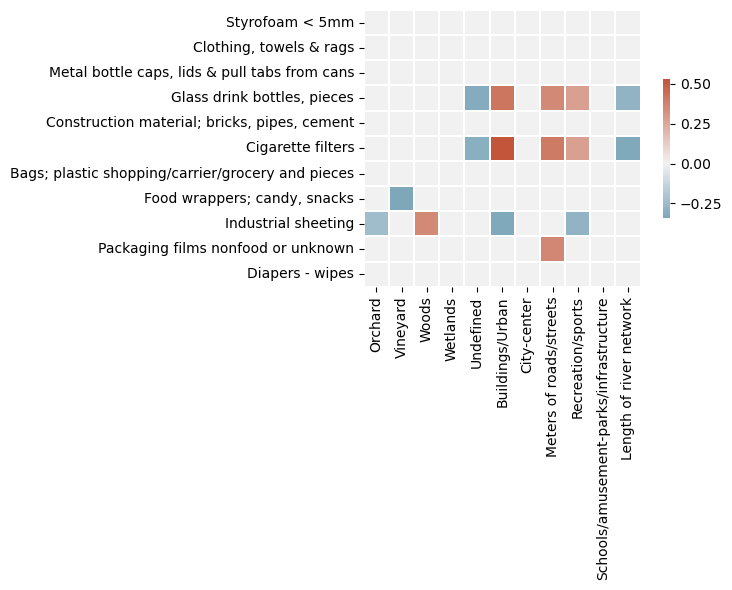
4.5. Rho with the new map data#
The total columns from the precedding sections are merged with the land cover section. In this version we account for more objects while homogenizing the sampling conditions. The removal of rivers is tantamount to removing zeroes given the consistently low survey results in the class. The exception is Lavey-les-Bains, situated jsut down stream from a damn and collected when the river was particularly low.
Show code cell source
all_results = pd.concat([landcover, strasse.strasse, freizeitareal.freizeitareal, nutuzungsareal.nutuzungsareal, d_and_l.length],axis=1).fillna(0)
column_names = {
"Obstanlage":"Orchard",
"Reben":"Vineyard",
"Wald":"Woods",
"Sumpf":"Wetlands",
"Undefined":"Undefined",
"Siedl":"Buildings/Urban",
"Stadtzentr":"City-center",
"strasse":"Meters of roads/streets",
"freizeitareal":"Recreation/sports",
"nutuzungsareal":"Schools/amusement-parks/infrastructure",
"distance": "Distance to river intersection",
"length": "Length of river network",
}
col_order = [
"Obstanlage",
"Reben",
"Wald",
"Sumpf",
"Undefined",
"Siedl",
"Stadtzentr",
"strasse",
"freizeitareal",
"nutuzungsareal",
"length",
]
all_results["desc"] = all_results.index.map(lambda x: code_d_map.loc[x])
all_results.set_index("desc", drop=True, inplace=True)
all_results = all_results[col_order]
all_results.rename(columns=column_names, inplace=True)
all_results.columns.name = None
all_results.index.name = None
bfr = all_results.style.format(precision=2).set_table_styles(table_css_styles)
bfr = bfr.background_gradient(axis=None, vmin=all_results.min().min(), vmax=all_results.max().max(), cmap=cmap)
bfr = bfr.applymap_index(rotateText, axis=1)
glue('rho_new_map_data', bfr, display=False)
| Orchard | Vineyard | Woods | Wetlands | Undefined | Buildings/Urban | City-center | Meters of roads/streets | Recreation/sports | Schools/amusement-parks/infrastructure | Length of river network | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Styrofoam < 5mm | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| Clothing, towels & rags | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| Metal bottle caps, lids & pull tabs from cans | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| Glass drink bottles, pieces | 0.00 | 0.00 | 0.00 | 0.00 | -0.32 | 0.42 | 0.00 | 0.35 | 0.28 | 0.00 | -0.28 |
| Construction material; bricks, pipes, cement | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| Cigarette filters | 0.00 | 0.00 | 0.00 | 0.00 | -0.30 | 0.53 | 0.00 | 0.40 | 0.28 | 0.00 | -0.33 |
| Bags; plastic shopping/carrier/grocery and pieces | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| Food wrappers; candy, snacks | 0.00 | -0.34 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| Industrial sheeting | -0.24 | 0.00 | 0.35 | 0.00 | 0.00 | -0.33 | 0.00 | 0.00 | -0.28 | 0.00 | 0.00 |
| Packaging films nonfood or unknown | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.36 | 0.00 | 0.00 | 0.00 |
| Diapers - wipes | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
4.5.2. Total correlations, total positive correlations, total negative corrrelations for 3’000 m hex#
Show code cell source
def countTheNumberOfCorrelations(data):
results = []
for acol in data.columns:
d = data[acol]
pos = (d > 0).sum()
neg = (d < 0).sum()
results.append({"attribute":acol, "positive":pos, "negative":neg, "total": pos + neg})
return results
total_correlations = pd.DataFrame(countTheNumberOfCorrelations(all_results))
total_correlations.set_index("attribute", drop=True, inplace=True)
total_correlations.loc['Total']= total_correlations.sum()
total_correlations.index.name = None
bfr = total_correlations.style.format(precision=2).set_table_styles(table_css_styles)
glue('total_correlations', bfr, display=False)
| positive | negative | total | |
|---|---|---|---|
| Orchard | 0 | 1 | 1 |
| Vineyard | 0 | 1 | 1 |
| Woods | 1 | 0 | 1 |
| Wetlands | 0 | 0 | 0 |
| Undefined | 0 | 2 | 2 |
| Buildings/Urban | 2 | 1 | 3 |
| City-center | 0 | 0 | 0 |
| Meters of roads/streets | 3 | 0 | 3 |
| Recreation/sports | 2 | 1 | 3 |
| Schools/amusement-parks/infrastructure | 0 | 0 | 0 |
| Length of river network | 0 | 2 | 2 |
| Total | 8 | 8 | 16 |
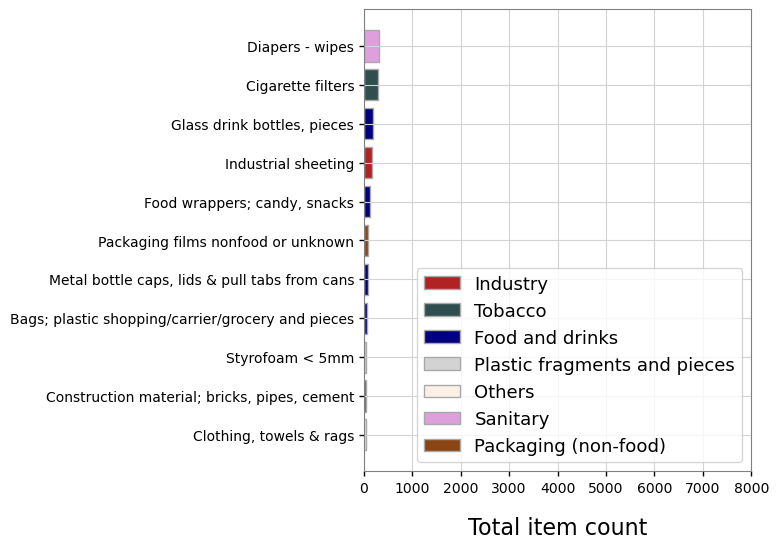
4.5.3. The cumulative totals of the objects of interest, grouped by economic source#
The object of interest were grouped according to economic source by considering the possible uses for each object, as defined in the object description and sources columns of the default codes data:
tobaco: “Tobacco”, “Smoking related”
industry: ‘Industry’,’Construction’, ‘Industrial’, ‘Manufacturing’
sanitary: “Sanitary”, “Personal hygiene”, “Water treatment”
packaging: ‘Packaging (non-food)’,’Packaging films nonfood or unknown’, ‘Paper packaging’
food: ‘Food and drinks’,’Foil wrappers, aluminum foil’, ‘Food and drinks’, ‘Food and drink’
fragments: ‘Plastic fragments and pieces’, ‘Plastic fragments angular <5mm’, ‘Styrofoam < 5mm’, ‘Plastic fragments rounded <5mm’, ‘Foamed plastic <5mm’, ‘Fragmented plastics’
Show code cell source
def check_condition(x, conditions, i):
if list(set(x)&set(conditions[i])):
data = conditions[i][0]
elif i == 0 and not list(set(x)&set(conditions[i])):
data = "Others"
else:
data = check_condition(x, conditions, i-1)
return data
# define the broad categories:
tobaco = ["Tobacco", "Smoking related"]
industry = ['Industry','Construction', 'Industrial', 'Manufacturing']
sanitary = ["Sanitary", "Personal hygiene", "Water treatment"]
packaging = ['Packaging (non-food)','Packaging films nonfood or unknown', 'Paper packaging']
food = ['Food and drinks','Foil wrappers, aluminum foil', 'Food and drinks', 'Food and drink']
fragments = ['Plastic fragments and pieces',
'Plastic fragments angular <5mm',
'Styrofoam < 5mm',
'Plastic fragments rounded <5mm',
'Foamed plastic <5mm',
'Fragmented plastics',
]
conditions = [tobaco, industry, sanitary, packaging, food, fragments]
codes_fail = codes
dT20 = df[df.code.isin(codes_fail)].groupby("code", as_index=False).quantity.sum().sort_values("quantity", ascending=False)
dT20["description"] = dT20.code.map(lambda x: code_d_map[x])
dT20.set_index("code", drop=True, inplace=True)
for each_code in dT20.index:
srcs = dfCodes.loc[each_code][["source", "source_two", "source_three", "description"]]
a = check_condition(srcs.values, conditions, len(conditions)-1)
dT20.loc[each_code, "Type"] = a
total_type = dT20.groupby(["Type"], as_index=False).quantity.sum()
total_type["Proportion [%]"] = ((total_type.quantity/df.quantity.sum())*100).round(1)
total_type.set_index("Type", drop=True, inplace=True)
total_type.index.name = None
total_type.loc["Total"] = total_type.sum()
total_type.style.format(precision=1).set_table_styles(table_css_styles)
| quantity | Proportion [%] | |
|---|---|---|
| Food and drinks | 451.0 | 18.2 |
| Industry | 218.0 | 8.8 |
| Others | 38.0 | 1.5 |
| Packaging (non-food) | 87.0 | 3.5 |
| Plastic fragments and pieces | 50.0 | 2.0 |
| Sanitary | 305.0 | 12.3 |
| Tobacco | 300.0 | 12.1 |
| Total | 1449.0 | 58.4 |
Show code cell source
fig, ax = plt.subplots(figsize=(5,6))
colors = {'Industry': 'firebrick', 'Tobacco': 'darkslategrey', 'Food and drinks': 'navy', 'Plastic fragments and pieces':'lightgrey',
'Others':'linen','Sanitary':'plum','Packaging (non-food)':'saddlebrown'}
width = 0.6
labels = list(colors.keys())
handles = [plt.Rectangle((0,0),1,1, color=colors[label]) for label in labels]
ax.barh(dT20.description, dT20.quantity, color=[colors[i] for i in dT20.Type], edgecolor='darkgrey')
ax.invert_yaxis()
ax.set_ylabel('')
xticks = [0,1000, 2000, 3000, 4000, 5000, 6000, 7000, 8000]
ax.set_xticks(xticks)
ax.set_xticklabels([str(x) for x in xticks])
ax.set_xlabel('Total item count', fontsize=16, labelpad =15)
ax.xaxis.set_ticks_position('bottom')
ax.yaxis.set_ticks_position('left')
ax.tick_params(labelcolor='k', labelsize=10, width=1)
ax.yaxis.grid(color='lightgray')
ax.xaxis.grid(color='lightgray')
ax.set_facecolor('white')
plt.legend(handles, labels, fontsize=13,facecolor='white', loc="lower right")
for ha in ax.legend_.legend_handles:
ha.set_edgecolor("darkgrey")
plt.grid(True)
ax.spines['top'].set_color('0.5')
ax.spines['right'].set_color('0.5')
ax.spines['bottom'].set_color('0.5')
ax.spines['left'].set_color('0.5')
# plt.savefig('C:/Users/schre086/figures/land_use_ch/top_20items.png', bbox_inches='tight')
plt.show()
4.6. Annex#
4.6.1. Print version of rho values#
resources/output/tlm-3d-2022-land-use.jpeg
This script updated 08/08/2023 in Biel, CH
❤️ what you do everyday
analyst at hammerdirt
Git repo: https://github.com/hammerdirt-analyst/landuse.git
Git branch: main
IPython : 8.12.0
numpy : 1.24.2
json : 2.0.9
matplotlib: 3.7.1
PIL : 9.5.0
pandas : 2.0.0
scipy : 1.10.1
seaborn : 0.12.2