Canton Valais#
Density of trash along lakes and rivers
This is a sample cantonal report. The structure and the format are based off of the federal report, (IQAASL). This version is intended for use as a decsion support tool. Thus, the user is expected to be familiar with the results in the federal report and the methods described in the Guide for Monitoring Marine Litter on European Seas (The guide).
Initial assessment: stakeholder discussion and priorities.
Stakeholders should consider the following questions while consulting the report:
Are the major rivers and lakes included?
Was their more or less observed in 2021 vs the prior results?
How do these results compare to assessments from other sources (EAWAG, EMPA, Internal reports)?
This includes reports from NGOS in the region
Is the data comparable?
Are the objects identified as the most common currently the focus of reduction or prevention campaigns?
How does the canton decide priorties in this regard?
Did or does the object appear in any regional action plan or strategy?
For objects that have been the focus of prevention or reduction campaigns in the past: are they on the most common objects list now?
If the objects are on the most common list, is this inline with expectations ?
What excatly was the mechanism or process that was intended to reduce the presence of the object?
With respect to the amount of resources attributed to prevention and mitigation: Do the attributed amounts reflect the importance of the object in terms of total amount found and frequency of occurence?
Does the sampling distribution reflect the topography and land-use of the canton?
Do the municipalities with elevated pcs/m have common land-use attributes?
Are the municipalities of strategic importance to the canton included?
Are their locations in the canton that should have been surveyed, according to cantonal priorities?
Are their products of regional interest that should be included in the cantonal report?
Map of survey locations
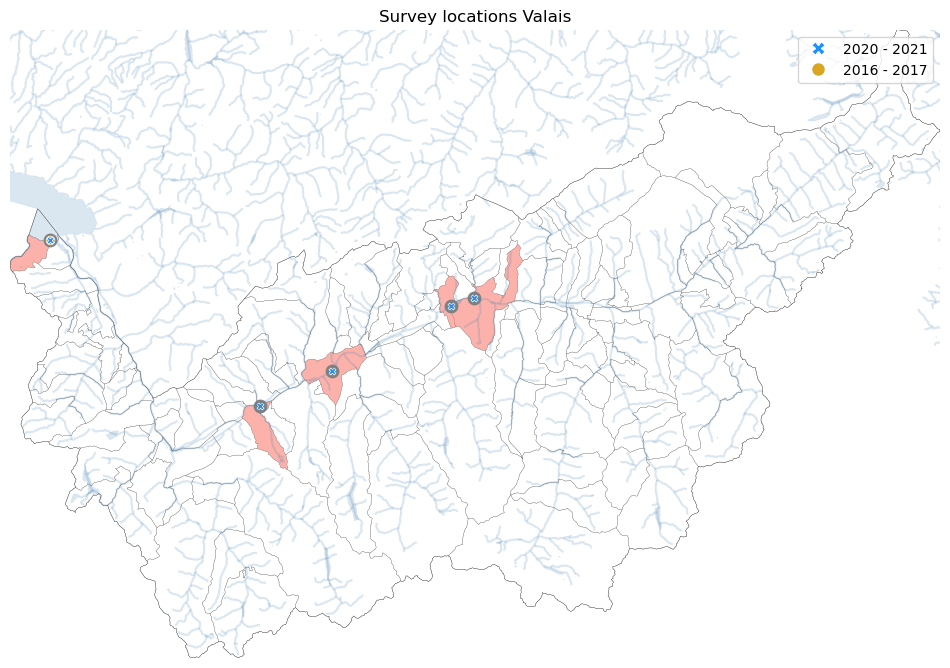
Vital statistics#
Features surveyed
Rivers: 1
Lakes: 1
Administrative boundaries
Survey locations: 5
Cities: 5
Material composition
| % of total | |
|---|---|
| material | |
| plastic | 96% |
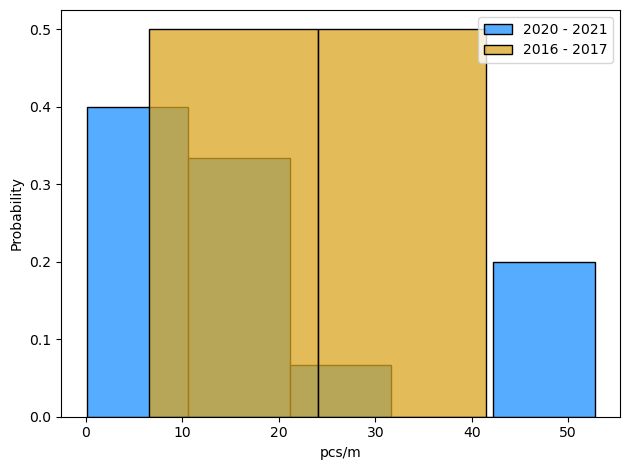
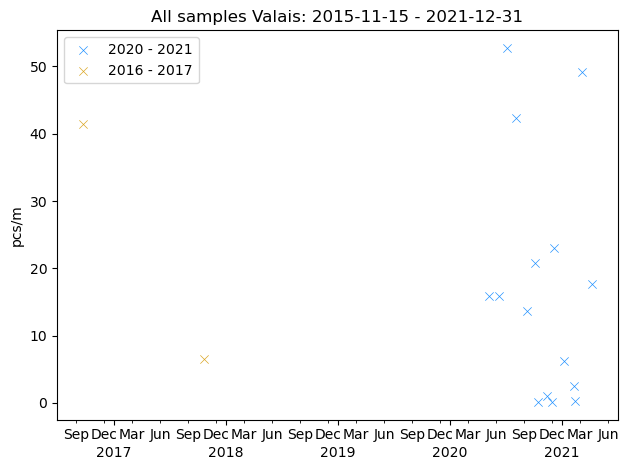
2016 - 2021
Number of samples: 17
Total objects: 8980
Average pcs/m: 18.22
Standard deviation: 17.37
Maximum pcs/m: 52.73
2020 - 2021
Number of samples: 15
Total objects: 7638
Average pcs/m: 17.44
Standard deviation: 17.21
Maximum pcs/m: 52.73
2016 - 2017
Number of samples: 2
Total objects: 1342
Average pcs/m: 24.01
Standard deviation: 17.46
Maximum pcs/m: 41.47
Features surveyed
Lakes: 1
Administrative boundaries
Survey locations: 1
Cities: 1
Material composition
| % of total | |
|---|---|
| material | |
| plastic | 96% |
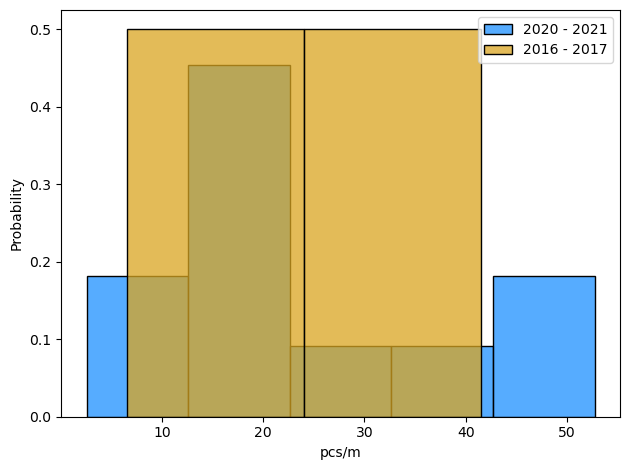
2016 - 2021
Number of samples: 13
Total objects: 8902
Average pcs/m: 23.7
Standard deviation: 16.34
Maximum pcs/m: 52.73
2020 - 2021
Number of samples: 11
Total objects: 7560
Average pcs/m: 23.64
Standard deviation: 16.12
Maximum pcs/m: 52.73
2016 - 2017
Number of samples: 2
Total objects: 1342
Average pcs/m: 24.01
Standard deviation: 17.46
Maximum pcs/m: 41.47
Features surveyed
Rivers: 1
Administrative boundaries
Survey locations: 4
Cities: 4
Material composition
| % of total | |
|---|---|
| material | |
| cloth | 5% |
| metal | 5% |
| plastic | 88% |
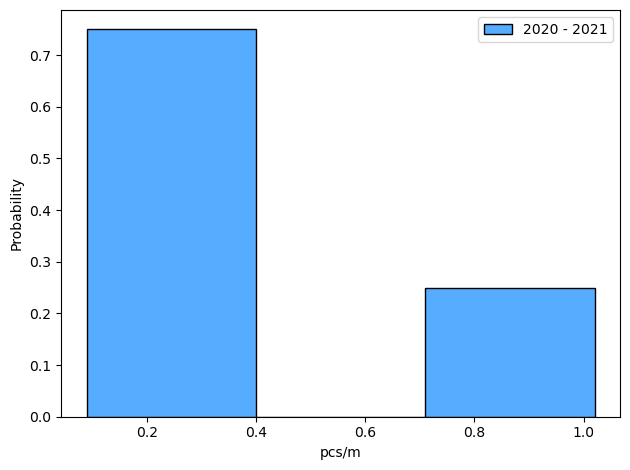
2020 - 2021
Number of samples: 4
Total objects: 78
Average pcs/m: 0.4
Standard deviation: 0.37
Maximum pcs/m: 1.02
2020 - 2021
Number of samples: 4
Total objects: 78
Average pcs/m: 0.4
Standard deviation: 0.37
Maximum pcs/m: 1.02
2015 - 2019
No samples prior to requested dates
How did we get this data ?
Common sense guidance:
The data should be considered as a reasonable estimate of the minimum amount of trash on the ground at the time of the survey.
There are many sources of variance. We have considered the following:
litter density between sampling groups.
litter density with respect to topographical features.
There are differences in detect-ability and appearance for items of the same classification that are due to the effects of decomposition.
Many surveyors are volunteers and have different levels of experience or physical constraints that limit what will actually be collected and counted.
How to make a report
Survey and Land use
A report is the implementation of a SurveyReport and a LandUseReport. The SurveyReport is the basic
element and does the initial aggregating and descriptive statistics for a query.
The land-use-report accepts SurveyReport.sample_results and assigns the land-use attributes to the record. The
land-use-report provides the baseline assessment of litter density with reference to the surrounding environment.
The assessment accepts as variables the proportion of available space that a topographical feature occupies in a
circle of \(\pi r² \text{ where r = 1 500 meters}\) and the center of that circle is the survey location.
These proportions are compared to the average pieces per meter for an object or group of objects.
Create a report
A report can be intiated by providing the name of the canton. If your canton does not appear this is because we have no data. The prior dates will be calculated automatically, by taking all data prior to the start date of the querry.
import reports
import geospatial
import gridforecast
# suppose you have defined your data into df
observed_dates = {'start':'2020-01-01', 'end':'2021-12-31'}
# everything that was seen before
prior_dates = {'start':'2015-11-15', 'end':'2019-12-31'}
# name the canton
canton = 'Bern'
# define the data of interest
data_of_interest = {'canton':canton, 'date_range':observed_dates}
# load the data
df = session_config.collect_survey_data()
# filter the data.
filtered_data, locations = gridforeacast.filter_data(df, data_of_interest)
# make a survey report
this_report = reports.SurveyReport(dfc=filtered_data)
# generate the parameters for the landuse report
target_df = this_report.sample_results
features = geospatial.collect_topo_data(locations=target_df.location.unique())
# make a landuse report
this_land_use = geospatial.LandUseReport(target_df, features)
Each report and the inference method are documented: SurveyReport, LandUseReport, GridForecaster
Most common objects 2020 - 2021#
The most common objects account for 87% of all objects
The most common objects from the selected data. The most common objects are a combination of the top ten most abundant objects and those objects that are found in more than 50% of the samples. Some objects are found frequently but at low quantities.Other objects are found in fewer samples but at higher quantities.
| Object | Quantity | pcs/m | % of total | Fail rate |
|---|---|---|---|---|
| Expanded polystyrene | 1'476 | 3,26 | 0,19 | 0,87 |
| Fragmented plastics | 1'183 | 2,64 | 0,15 | 0,87 |
| plastic caps, lid rings: G21, G22, G23, G24 | 576 | 1,35 | 0,08 | 0,73 |
| Industrial sheeting | 516 | 1,35 | 0,07 | 0,87 |
| Food wrappers; candy, snacks | 478 | 1,26 | 0,06 | 0,73 |
| Cotton bud/swab sticks | 453 | 0,99 | 0,06 | 0,73 |
| Foam packaging/insulation/polyurethane | 452 | 0,43 | 0,06 | 1,47 |
| Plastic construction waste | 295 | 0,65 | 0,04 | 0,80 |
| Plastic shotgun wadding | 219 | 0,47 | 0,03 | 0,80 |
| Food containers single use foamed or plastic | 175 | 0,39 | 0,02 | 0,73 |
| Tobacco; plastic packaging, containers | 133 | 0,35 | 0,02 | 0,60 |
| Cups, lids, single use foamed and hard plastic | 87 | 0,20 | 0,01 | 0,73 |
| Lollypop sticks | 85 | 0,19 | 0,01 | 0,73 |
| Straws and stirrers | 75 | 0,18 | 0,01 | 0,73 |
| Cigarette filters | 74 | 0,16 | 0,01 | 0,67 |
| Toys and party favors | 72 | 0,16 | 0,01 | 0,80 |
| Biomass holder | 46 | 0,11 | 0,01 | 0,67 |
| Medical; containers/tubes/ packaging | 45 | 0,10 | 0,01 | 0,60 |
| Fireworks; rocket caps, exploded parts & packaging | 35 | 0,07 | 0,00 | 0,60 |
| Plastic flower pots | 34 | 0,09 | 0,00 | 0,53 |
| Straps/bands; hard, plastic package fastener | 31 | 0,08 | 0,00 | 0,53 |
| Drink bottles < = 0.5L | 29 | 0,06 | 0,00 | 0,67 |
| Pens, lids, mechanical pencils etc. | 27 | 0,06 | 0,00 | 0,53 |
| Metal bottle caps, lids & pull tabs from cans | 24 | 0,05 | 0,00 | 0,53 |
| Sanitary pads /panty liners/tampons and applicators | 24 | 0,06 | 0,00 | 0,53 |
| Corks | 23 | 0,05 | 0,00 | 0,53 |
The most common objects account for 93% of all objects
The most common objects from the selected data. The most common objects are a combination of the top ten most abundant objects and those objects that are found in more than 50% of the samples. Some objects are found frequently but at low quantities.Other objects are found in fewer samples but at higher quantities.
| Object | Quantity | pcs/m | % of total | Fail rate |
|---|---|---|---|---|
| Expanded polystyrene | 1'474 | 4,44 | 0,19 | 1,00 |
| Fragmented plastics | 1'179 | 3,60 | 0,16 | 1,00 |
| plastic caps, lid rings: G21, G22, G23, G24 | 576 | 1,84 | 0,08 | 1,00 |
| Industrial sheeting | 498 | 1,81 | 0,07 | 1,00 |
| Food wrappers; candy, snacks | 477 | 1,72 | 0,06 | 0,91 |
| Cotton bud/swab sticks | 453 | 1,35 | 0,06 | 1,00 |
| Foam packaging/insulation/polyurethane | 452 | 0,48 | 0,06 | 2,00 |
| Plastic construction waste | 291 | 0,87 | 0,04 | 1,00 |
| Plastic shotgun wadding | 218 | 0,64 | 0,03 | 1,00 |
| Food containers single use foamed or plastic | 175 | 0,54 | 0,02 | 1,00 |
| Styrofoam < 5mm | 166 | 0,49 | 0,02 | 0,64 |
| Tobacco; plastic packaging, containers | 133 | 0,47 | 0,02 | 0,82 |
| Cups, lids, single use foamed and hard plastic | 87 | 0,27 | 0,01 | 1,00 |
| Lollypop sticks | 85 | 0,26 | 0,01 | 1,00 |
| Straws and stirrers | 75 | 0,24 | 0,01 | 1,00 |
| Cigarette filters | 72 | 0,22 | 0,01 | 0,82 |
| Toys and party favors | 71 | 0,22 | 0,01 | 1,00 |
| Biomass holder | 46 | 0,14 | 0,01 | 0,91 |
| Medical; containers/tubes/ packaging | 45 | 0,14 | 0,01 | 0,82 |
| Industrial pellets (nurdles) | 43 | 0,14 | 0,01 | 0,64 |
| Glass drink bottles, pieces | 37 | 0,11 | 0,00 | 0,64 |
| Labels, bar codes | 35 | 0,13 | 0,00 | 0,55 |
| Fireworks; rocket caps, exploded parts & packaging | 35 | 0,10 | 0,00 | 0,82 |
| Plastic flower pots | 34 | 0,12 | 0,00 | 0,73 |
| Foamed items & pieces (non packaging/insulation) foamed sponge material | 32 | 0,10 | 0,00 | 0,55 |
| Straps/bands; hard, plastic package fastener | 31 | 0,11 | 0,00 | 0,73 |
| Bags; plastic shopping/carrier/grocery and pieces | 29 | 0,11 | 0,00 | 0,55 |
| Drink bottles < = 0.5L | 29 | 0,08 | 0,00 | 0,91 |
| Pens, lids, mechanical pencils etc. | 27 | 0,08 | 0,00 | 0,73 |
| Tape; electrical, insulating | 23 | 0,07 | 0,00 | 0,64 |
| Corks | 23 | 0,07 | 0,00 | 0,73 |
| Metal bottle caps, lids & pull tabs from cans | 23 | 0,06 | 0,00 | 0,64 |
| Small plastic bags; freezer, zip-lock etc. | 21 | 0,08 | 0,00 | 0,55 |
| Sanitary pads /panty liners/tampons and applicators | 21 | 0,08 | 0,00 | 0,64 |
| Cigarette lighters | 17 | 0,06 | 0,00 | 0,55 |
| Paraffin wax | 10 | 0,03 | 0,00 | 0,64 |
| Rubber bands | 8 | 0,03 | 0,00 | 0,55 |
| Drink bottles > 0.5L | 8 | 0,03 | 0,00 | 0,55 |
| Syringes - needles | 8 | 0,03 | 0,00 | 0,55 |
| Pheromone baits for vineyards | 7 | 0,02 | 0,00 | 0,55 |
The most common objects account for 80% of all objects
The most common objects from the selected data. The most common objects are a combination of the top ten most abundant objects and those objects that are found in more than 50% of the samples. Some objects are found frequently but at low quantities.Other objects are found in fewer samples but at higher quantities.
| Object | Quantity | pcs/m | % of total | Fail rate |
|---|---|---|---|---|
| Industrial sheeting | 18 | 0,09 | 0,23 | 0,50 |
| Diapers - wipes | 13 | 0,07 | 0,17 | 0,50 |
| Bags; plastic shopping/carrier/grocery and pieces | 9 | 0,04 | 0,12 | 0,25 |
| Sheeting ag. greenhouse film | 4 | 0,02 | 0,05 | 0,25 |
| Tape-caution for barrier, police, construction etc. | 4 | 0,02 | 0,05 | 0,50 |
| Plastic construction waste | 4 | 0,02 | 0,05 | 0,25 |
| Fragmented plastics | 4 | 0,02 | 0,05 | 0,50 |
| Sanitary pads /panty liners/tampons and applicators | 3 | 0,01 | 0,04 | 0,25 |
| Cigarette filters | 2 | 0,01 | 0,03 | 0,25 |
| Expanded polystyrene | 2 | 0,01 | 0,03 | 0,50 |
Defining the most common objects
The default method for defining the most common objects is based on the number of items collected and the number of times that at least one of an object was found with respect to the number of surveys in the query, the fail rate.
Adjusting the fail rate will increase or decrease the number of the most common objects. The fail rate is included with the object inventory.
# the most common objects are accesible in the survey report
# the report.object_summary method aggregates the data to code
# and attaches the fail rate and % of total
inventory = this_report.object_summary()
# userdisplay.most_common, takes the 10 most abundant and filters
# the data for fail rate >= 0.5. The method returns a formatted table,
# a list of the codes and the ratio of the quantity of the most common to the whole
mostcommon, codes, ratio = userdisplay.most_common(inventory)
Land use#
Land use refers to the measurable topographic features within a cirlce of r = 1 500 m and area = \(\pi r²\) with the survey location in the middle. The features, measured in meters squared, are given as a ratio \(\frac{\text{area of feature}}{\text{area of circle}}\). Thus a location with high percentage of buildings will have a rating or value between 60% and 100%. The pcs/m rating is the average of all locations with a land-use profile of the same rating.
The rate per feature refers to the average pcs/m observed at a particular land use rate
Under what conditions is the pcs/m elevated? Where is it the least?
The sampling profile refers to the ratio of samples that were taken at a particular land use rate
Does the sampling profile reflect the topography of the region?
Rate per feature 2020 - 2021#
Land use
| 0 - 20% | 20 - 40% | 40 - 60% | 60 - 80% | 80 - 100% | |
|---|---|---|---|---|---|
| Orchards | 18.68 | 0.09 | 0.00 | 0.00 | 0.00 |
| Vineyards | 20.04 | 0.56 | 0.00 | 0.00 | 0.00 |
| Buildings | 0.47 | 23.64 | 0.00 | 0.18 | 0.00 |
| Forest | 0.14 | 0.30 | 21.76 | 0.00 | 0.00 |
| Undefined | 0.43 | 21.70 | 0.00 | 0.00 | 0.00 |
| Public Services | 17.44 | 0.00 | 0.00 | 0.00 | 0.00 |
Streets
The streets are measured as the length of the road network in the cirlce with r= 1 500 m and area \(\pi r²\) and the survey location in the middle. The lenghts for each location are normalized from 0 - 1. Thus in the table below, the locations that have the shortest road net work will be in category 1, the those with a more dense network will be higher.
| 0 - 20% | 20 - 40% | 40 - 60% | 60 - 80% | 80 - 100% | |
|---|---|---|---|---|---|
| streets | 23.64 | 1.02 | 0.20 | 0.18 | 0 |
Land use
| 0 - 20% | 20 - 40% | 40 - 60% | 60 - 80% | 80 - 100% | |
|---|---|---|---|---|---|
| Orchards | 23.64 | 0.00 | 0.00 | 0.00 | 0.00 |
| Vineyards | 23.64 | 0.00 | 0.00 | 0.00 | 0.00 |
| Buildings | 0.00 | 23.64 | 0.00 | 0.00 | 0.00 |
| Forest | 0.00 | 0.00 | 23.64 | 0.00 | 0.00 |
| Undefined | 0.00 | 23.64 | 0.00 | 0.00 | 0.00 |
| Public Services | 23.64 | 0.00 | 0.00 | 0.00 | 0.00 |
Streets
The streets are measured as the length of the road network in the cirlce with r= 1 500 m and area \(\pi r²\) and the survey location in the middle. The lenghts for each location are normalized from 0 - 1. Thus in the table below, the locations that have the shortest road net work will be in category 1, the those with a more dense network will be higher.
| 0 - 20% | 20 - 40% | 40 - 60% | 60 - 80% | 80 - 100% | |
|---|---|---|---|---|---|
| streets | 23.64 | 0 | 0 | 0 | 0 |
Land use
| 0 - 20% | 20 - 40% | 40 - 60% | 60 - 80% | 80 - 100% | |
|---|---|---|---|---|---|
| Orchards | 0.50 | 0.09 | 0.00 | 0.00 | 0.00 |
| Vineyards | 0.24 | 0.56 | 0.00 | 0.00 | 0.00 |
| Buildings | 0.47 | 0.00 | 0.00 | 0.18 | 0.00 |
| Forest | 0.14 | 0.30 | 1.02 | 0.00 | 0.00 |
| Undefined | 0.43 | 0.30 | 0.00 | 0.00 | 0.00 |
| Public Services | 0.40 | 0.00 | 0.00 | 0.00 | 0.00 |
Streets
The streets are measured as the length of the road network in the cirlce with r= 1 500 m and area \(\pi r²\) and the survey location in the middle. The lenghts for each location are normalized from 0 - 1. Thus in the table below, the locations that have the shortest road net work will be in category 1, the those with a more dense network will be higher.
| 0 - 20% | 20 - 40% | 40 - 60% | 60 - 80% | 80 - 100% | |
|---|---|---|---|---|---|
| streets | 0 | 1.02 | 0.20 | 0.18 | 0 |
Sampling profile 2020 - 2021#
Land use
| 0 - 20% | 20 - 40% | 40 - 60% | 60 - 80% | 80 - 100% | |
|---|---|---|---|---|---|
| Orchards | 93% | 7% | 0% | 0% | 0% |
| Vineyards | 87% | 13% | 0% | 0% | 0% |
| Buildings | 20% | 73% | 0% | 7% | 0% |
| Forest | 13% | 7% | 80% | 0% | 0% |
| Undefined | 20% | 80% | 0% | 0% | 0% |
| Public Services | 100% | 0% | 0% | 0% | 0% |
Streets
The streets are measured as the length of the road network in the cirlce with r= 1 500 m and area \(\pi r²\) and the survey location in the middle. The lengths for each location are normalized from 0 - 1. Thus in the table below, the locations that have the shortest road net work will be in category 1, the those with a more dense network will be higher.
| 0 - 20% | 20 - 40% | 40 - 60% | 60 - 80% | 80 - 100% | |
|---|---|---|---|---|---|
| streets | 73% | 7% | 13% | 7% | 0% |
Land use
| 0 - 20% | 20 - 40% | 40 - 60% | 60 - 80% | 80 - 100% | |
|---|---|---|---|---|---|
| Orchards | 100% | 0% | 0% | 0% | 0% |
| Vineyards | 100% | 0% | 0% | 0% | 0% |
| Buildings | 0% | 100% | 0% | 0% | 0% |
| Forest | 0% | 0% | 100% | 0% | 0% |
| Undefined | 0% | 100% | 0% | 0% | 0% |
| Public Services | 100% | 0% | 0% | 0% | 0% |
Streets
The streets are measured as the length of the road network in the cirlce with r= 1 500 m and area \(\pi r²\) and the survey location in the middle. The lenghts for each location are normalized from 0 - 1. Thus in the table below, the locations that have the shortest road net work will be in category 1, the those with a more dense network will be higher.
| 0 - 20% | 20 - 40% | 40 - 60% | 60 - 80% | 80 - 100% | |
|---|---|---|---|---|---|
| streets | 100% | 0% | 0% | 0% | 0% |
Land use
| 0 - 20% | 20 - 40% | 40 - 60% | 60 - 80% | 80 - 100% | |
|---|---|---|---|---|---|
| Orchards | 75% | 25% | 0% | 0% | 0% |
| Vineyards | 50% | 50% | 0% | 0% | 0% |
| Buildings | 75% | 0% | 0% | 25% | 0% |
| Forest | 50% | 25% | 25% | 0% | 0% |
| Undefined | 75% | 25% | 0% | 0% | 0% |
| Public Services | 100% | 0% | 0% | 0% | 0% |
Streets
The streets are measured as the length of the road network in the cirlce with r= 1 500 m and area \(\pi r²\) and the survey location in the middle. The lenghts for each location are normalized from 0 - 1. Thus in the table below, the locations that have the shortest road net work will be in category 1, the those with a more dense network will be higher.
| 0 - 20% | 20 - 40% | 40 - 60% | 60 - 80% | 80 - 100% | |
|---|---|---|---|---|---|
| streets | 0% | 25% | 50% | 25% | 0% |
Defining land use
Land cover
These measured land-use attributes are the labeled polygons from the map layer Landcover defined here (swissTLMRegio product information), they are extracted using vector overlay techniques in QGIS (QGIS).
Buildings: built up, urbanized
Woods: not a park, harvesting of trees may be active
Vineyards: does not include any other type of agriculture
Orchards: not vineyards
Undefined: areas of the map with no predefined label
# the land use is summarized using a LandUseReport object
# the average pieces per meter by land use category
rate_per_feature = this_land_use.n_pieces_per_feature()
# the sampling distribution
samples_per_feature = this_land_use.n_samples_per_feature()
# the variety of locations per feature
locations_per_feature = this_land_use.locations_per_feature()
# format for display .html
styled_rate_per_feature = userdisplay.litter_rates_per_feature(rate_per_feature)
Public services
Public services are the labled polygons from the Freizeitareal and Nutzungsareal map layers, defined in (swissTLMRegio product information). Both layers represent areas used for specific activities. Freizeitareal identifies areas used for recreational purposes and Nutzungsareal represents areas such as hospitals, cemeteries, historical sites or incineration plants. As a ratio of the available dry-land in a hex, these features are relatively small (less than 10%) of the total dry-land. For identified features within a bounding hex the magnitude in meters² of these variables is scaled between 0 and 1, thus the scaled value represents the size of the feature in relation to all other measured values for that feature from all other hexagons.
Recreation: parks, sports fields, attractions
Infrastructure: Schools, Hospitals, cemeteries, powerplants
Streets and roads
Streets and roads are the labled polylines from the TLM Strasse map layer defined in (swissTLMRegio product information). All polyines from the map layer within a bounding hex are merged (disolved in QGIS commands) and the combined length of the polylines, in meters, is the magnitude of the variable for the bounding hex.
Forecast#
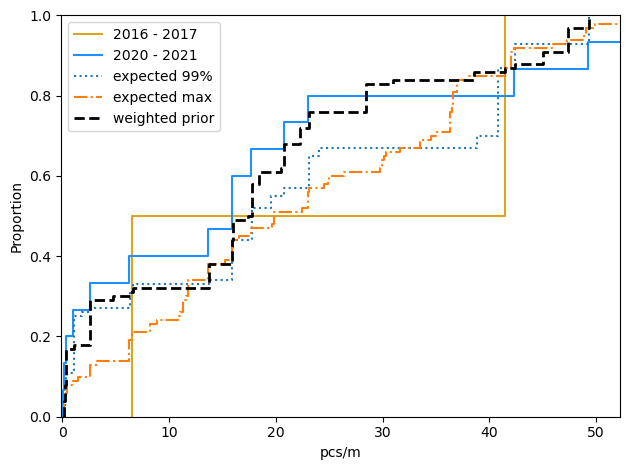
Minimum expected survey results 2025
Given the 99th percentile
Average: 21.19
HDI 95%: 0.3 - 49.3
90% Range: 0.3 - 49.3
Given the weighted prior
Average: 18.09
HDI 95%: 0.1 - 47.4
90% Range: 0.2 - 47.4
Given the observed max
Average: 21.44
HDI 95%: 0.52 - 52.69
90% Range: 1.02 - 51.4
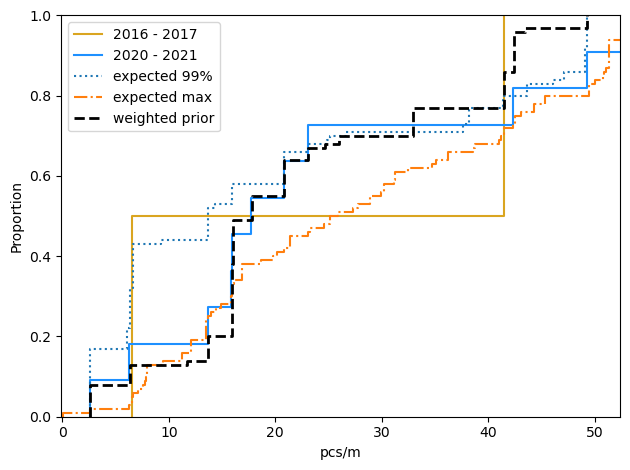
Minimum expected survey results 2025
Given the 99th percentile
Average: 20.25
HDI 95%: 2.6 - 49.3
90% Range: 2.6 - 49.3
Given the weighted prior
Average: 22.68
HDI 95%: 2.6 - 42.4
90% Range: 2.6 - 42.4
Given the observed max
Average: 27.17
HDI 95%: 0.34 - 47.81
90% Range: 2.87 - 50.2
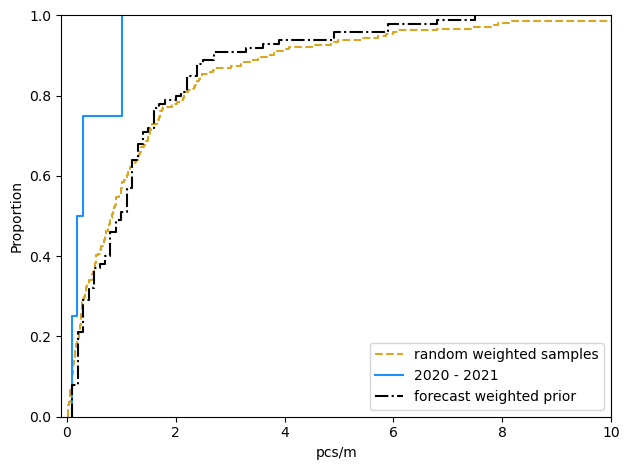
Minimum expected survey results 2025
Given the observed 99
No prior data to consider see weighted prior
Given the weighted prior
Average: 1.33
HDI 95%: 0.1 - 4.9
90% Range: 0.1 - 4.9
Given the observed max
No prior data to consider see weighted prior
Forecast methods
The applied method would best be classified as Empirical Bayes, in the sense that the prior is derived from the data (Bayesian Filtering and Smoothing or Empirical Bayes methods in classical and Bayesian inference). However, we share the concerns of Davidson-Pillon Bayesian methods for hackers about double counting and eliminate it the possibility as part of the formulation of the prior.
Model assumptions
Locations with similar land use attributes will have similar litter density rates
The data is a best estimate of what was present on the day of the survey
There are regional differences with respect to the density of specific objects
The locations surveyed are maintained by a public administration
The choice of land use features was a natural choice but was further explored in Near or Far.
Our parameter estimates are thus derived from the data and they remain testable and quantifiable according to Prior Probabilities, E T Jaynes. This makes our calculation very repetetive but also very well understood. It can be defined in a few lines of code for any set of survey results.
# standared libaries
import numpy as np
from scipy.stats import dirichlet, multinomial
# collect the data of interest
h = array of survey values
# count the number of times that each survey values exceed a value on the gird
counts = np.array([np.sum((h > x) & (h <= x + .1)) for x in grid_range])
# use the dirichlet dist to estimate p(Y >= x) for each x on the grid
# and sample from the estimation
adist = dirichlet(counts)
this_dist = adist.rvs(1-[0]
# draw samples from the conjugate
posterior_samples = multinomial.rvs(nsamples, p=this_dist)
Lakes and rivers sampled - all data#
Lakes sampled
| samples | pcs/m | |
|---|---|---|
| Lac-leman | 13 | 23.70 |
Rivers sampled
| samples | pcs/m | |
|---|---|---|
| Rhone | 4 | 0.40 |
Municipal Results - all data#
The average pieces per meter and the combined land use classification for each city.
| quantity | pcs/m | samples | orchards | vineyards | buildings | forest | undefined | public services | streets | |
|---|---|---|---|---|---|---|---|---|---|---|
| city | ||||||||||
| Saint-Gingolph | 8902 | 23.70 | 13 | 1 | 1 | 2 | 3 | 2 | 1 | 1 |
| quantity | pcs/m | samples | orchards | vineyards | buildings | forest | undefined | public services | streets | |
|---|---|---|---|---|---|---|---|---|---|---|
| city | ||||||||||
| Leuk | 15 | 0.30 | 1 | 1 | 1 | 1 | 2 | 2 | 1 | 3 |
| Riddes | 3 | 0.09 | 1 | 2 | 2 | 1 | 1 | 1 | 1 | 3 |
| Salgesch | 51 | 1.02 | 1 | 1 | 2 | 1 | 3 | 1 | 1 | 2 |
| Sion | 9 | 0.18 | 1 | 1 | 1 | 4 | 1 | 1 | 1 | 4 |