Show code cell source
# sys, file and nav packages:
import datetime as dt
# math packages:
import pandas as pd
import numpy as np
from scipy import stats
from statsmodels.distributions.empirical_distribution import ECDF
# charting:
import matplotlib as mpl
import matplotlib.pyplot as plt
from matplotlib import colors
import matplotlib.dates as mdates
from matplotlib import ticker
import seaborn as sns
# build report
import reportlab
from reportlab.platypus.flowables import Flowable
from reportlab.platypus import SimpleDocTemplate, Paragraph, Spacer, PageBreak, KeepTogether
from reportlab.lib.pagesizes import A4
from reportlab.lib.units import cm
from reportlab.platypus import Table, TableStyle
# the module that has all the methods for handling the data
import resources.featuredata as featuredata
from resources.featuredata import makeAList, small_space, large_space, aSingleStyledTable, smallest_space
from resources.featuredata import caption_style, subsection_title, title_style, block_quote_style
from resources.featuredata import figureAndCaptionTable, tableAndCaption, aStyledTableWithTitleRow
from resources.featuredata import sectionParagraphs, section_title, addToDoc, makeAParagraph, bold_block
# home brew utitilties
import resources.chart_kwargs as ck
import resources.sr_ut as sut
# images and display
from PIL import Image as PILImage
from IPython.display import Markdown as md
from myst_nb import glue
import locale
loc = locale.getlocale()
lang = "de_CH.utf8"
locale.setlocale(locale.LC_ALL, lang)
save_fig_prefix = "resources/output/"
save_figure_kwargs = {
"fname": None,
"dpi": 300.0,
"format": "jpeg",
"bbox_inches": None,
"pad_inches": 0,
"bbox_inches": 'tight',
"facecolor": 'auto',
"edgecolor": 'auto',
"backend": None,
}
pdf_link = 'resources/pdfs/land_use_correlation.pdf'
source_prefix = "https://hammerdirt-analyst.github.io/IQAASL-End-0f-Sampling-2021/"
source = "land_use_correlation.html"
# set some parameters:
today = dt.datetime.now().date().strftime("%Y-%m-%d")
start_date = "2020-03-01"
end_date ="2021-05-31"
unit_label = "pcs_m"
# banded color for table
a_color = "saddlebrown"
# get the data:
survey_data = pd.read_csv("resources/checked_sdata_eos_2020_21.csv")
dfBeaches = pd.read_csv("resources/beaches_with_land_use_rates.csv")
dfCodes = pd.read_csv("resources/codes_with_group_names_2015.csv")
# set the index of the beach data to location slug
dfBeaches.set_index("slug", inplace=True)
# set the code index and edit descriptions for display:
dfCodes.set_index("code", inplace=True)
# make a map to the code descriptions
code_description_map = dfCodes.description
# make a map to the code materials
code_material_map = dfCodes.material
codes_class = featuredata.Codes(code_data=dfCodes, language='de')
codes_class.adjustForLanguage()
# language specific
# importing german code descriptions and material type transaltions
de_codes = pd.read_csv("resources/codes_german_Version_1.csv")
de_codes.set_index("code", inplace=True)
glue("blank_caption", " ", display=False)
dfCodes = codes_class.dfCodes
17. Landnutzungsprofil#
Das Landnutzungsprofil ist eine numerische Darstellung der Art und des Umfangs der wirtschaftlichen Aktivität um den Erhebungsort. Das Profil wird anhand von Daten berechnet, die in Kartenebenen gespeichert sind, die im Geoportal des Bundes und beim Bundesamt für Statistik verfügbar sind.
Abfallobjekte sind weggeworfene Objekte, die in der natürlichen Umgebung gefunden werden. Das Objekt selbst und der Kontext, in dem es gefunden wird, sind Indikatoren für die wirtschaftliche und geografische Herkunft. Wie das Land in der Nähe des Erhebungsortes genutzt wird, ist ein wichtiger Kontext, der bei der Bewertung der Erhebungsergebnisse berücksichtigt werden muss. [] []
Im September 2020 hat die Europäische Union Basislinien und Zielwerte für Abfallobjekte am Strand veröffentlicht. Nach Abwägung vieler Faktoren, darunter die Transparenz der Berechnungsmethode und die Leistung in Bezug auf Ausreisser, hat die EU entschieden, dass der Medianwert der Datenerhebungen zum Vergleich der Basiswerte zwischen den Regionen verwendet wird. Dies hat das Interesse der Gemeinden geweckt, punktuelle Abfallobjekte besser zu identifizieren und zu quantifizieren, da sie versuchen, den effizientesten Weg zur Einhaltung der Zielwerte zu finden. Die Identifizierung relevanter Landnutzungsmuster und -merkmale ist ein wesentliches Element in diesem Prozess. [] [] []
Hier schlagen wir eine Methode vor, um die Ergebnisse von Untersuchungen des Ufer-Abfallaufkommens im Hinblick auf das Landnutzungsprofil im Umkreis von 1500 m um den Erhebungsort auszuwerten. Die Erhebungsergebnisse der häufigsten Objekte werden mit Hilfe von Spearmans rho oder Spearmans ranked correlation, einem nicht-parametrischen Test auf Assoziation mit den gemessenen Landnutzungsmerkmalen getestet. []
17.1. Berechnung des Landnutzungsprofils#
Das Landnutzungsprofil setzt sich aus den messbaren Eigenschaften zusammen, die geografisch verortet sind und aus den aktuellen Versionen der Arealstatisik der Schweiz und swissTLMRegio extrahiert werden können. [] [].
Die folgenden Werte wurden in einem Radius von 1500 m um jeden Erhebungsort berechnet:
Fläche, die von Gebäuden eingenommen wird in %
Fläche, die dem Wald vorbehalten ist in %
Fläche, die für Aktivitäten im Freien genutzt wird in %
Fläche, die von der Landwirtschaft genutzt wird in %
Strassen in Gesamtzahl der Strassenkilometer
Anzahl Flussmündungen
Berechnung des Landnutzungsprofils
Das Bundesamt für Statistik stellt die Arealstatistik zur Verfügung, ein Raster von Punkten 100m x 100m, das die Schweiz abdeckt. Jedem Punkt ist eine von 27 verschiedenen Landnutzungskategorien zugeordnet, die durch die Standardklassifikation von 2004 definiert sind. Dieses Raster dient als Grundlage für die Berechnung des Landnutzungsprofils in der Umgebung des Erhebungsorts. Für diese Studie wurden die Landnutzungskategorien in sieben Gruppen aus den siebenundzwanzig verfügbaren Kategorien zusammengefasst.
Die aggregierten Werte und die entsprechenden Landnutzungskategorien
Gebäude: (1, 2, 3, 4, 5, 9)
Transport:(6, 7, 8)
Erholung: (10)
Landwirtschaft: (11, 12, 13, 14, 15, 16, 18)
Wald: (17, 19, 20, 21, 22)
Wasser: (23, 24)
unproduktiv: (25, 26, 27)
Für jeden Erhebungsort wurde die kumulative Summe und die kumulative Summe jeder Gruppe innerhalb des 1500-m-Puffers berechnet. Die dem Wasser zugewiesene Menge wurde von der kumulativen Summe abgezogen. Das Ergebnis wurde verwendet, um den Prozentsatz der Landnutzung für jede Kategorie zu berechnen.
Die Kategorie Aktivitäten im Freien umfasst verschiedene Anwendungen für die öffentliche Nutzung. Die Nutzung reicht von Sportplätzen bis hin zu Friedhöfen und umfasst alle Bereiche, die für soziale Aktivitäten zur Verfügung stehen.
Berechnung der Strassenlänge
Die Strassenlänge wurde berechnet, indem die Kartenebene swissTLM3D_TLM_STRASSE mit dem 1500-m-Puffer jedes Erhebungsortes geschnitten wurde. Alle Strassen und Wege wurden zu einer Linie zusammengefasst (QGIS: dissolve) und die Länge der Linie ist der angegebene Wert der Strassenkilometer.
Zählen der Einträge aus Fliessgewässern
Für Erhebungsorte an Seen wurde die Anzahl der Flussmündungen im Umkreis von 1500 m von jedem Erhebungsort berechnet. Die Kartenebene swissTLM3D_TLM_FLIESSGEWAESSER (Fliessgewässer) wurde mit swissTLM3D_TLM_STEHENDES_GEWAESSER (Seen) geschnitten (QGI: «Linienschnittpunkte»), und die Anzahl der Schnittpunkte pro 1500 m Puffer wurde gezählt (QGI: «Punkte im Polygon zählen»). Die Kartenebene der Seen wurde um 100 Meter erweitert, um alle Abflussstellen oder Bäche zu erfassen, die in der Nähe des Sees enden. [] []
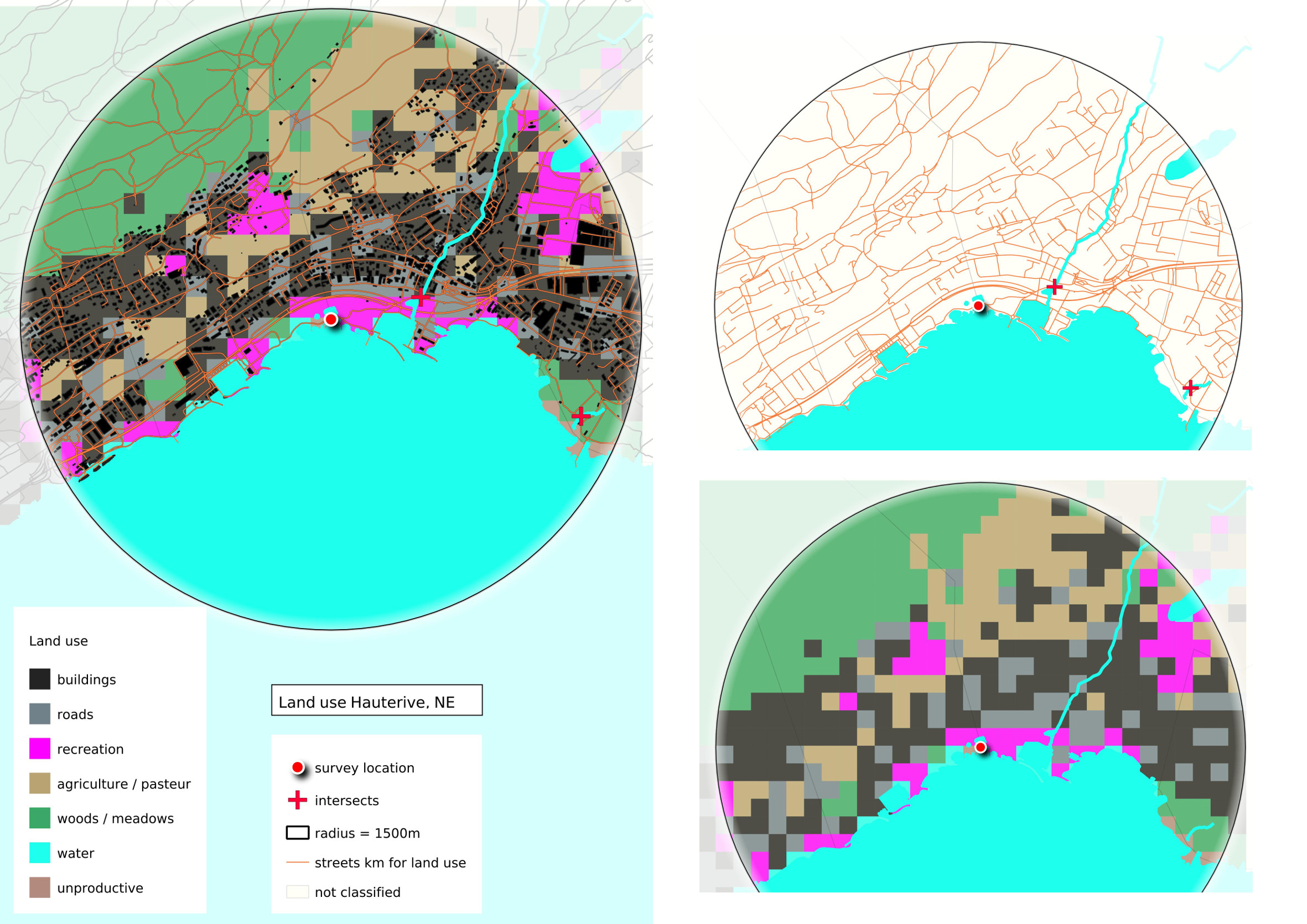
Abb. 17.1 #
Abildung 17.1: Für die Berechnung des Landnutzungsprofils verwendete Kartenebenen. Oben links: alle messbaren Werte innerhalb von 1500 m. Oben rechts: Strassen und Flussmündungen innerhalb von 1500 m. Unten rechts: Landnutzungspunkte, die zur Berechnung des prozenutalen Anteils der Gesamtfläche und der Gesamtfläche verwendet werden.
Berechnetes Landnutzungsprofil von Hauterive-petite-plage, NE 31-07-2020.
Fläche, die von Gebäuden eingenommen wird: 32,7 %
Fläche, die für Aktivitäten im Freien genutzt wird: 9,9 %
Fläche, die von der Landwirtschaft genutzt wird: 18,9 %
Fläche, die dem Wald vorbehalten ist: 24,3 %
Strassen in Gesamtzahl der Strassenkilometer: 85
Anzahl Flussmündungen: 2

Abb. 17.2 #
Abildung 17.2: Datenerhebungen in einer ländlichen Umgebung. Kallnach, BE 26.02.2021

Abb. 17.3 #
Abildung 17.3: Datenerhebungen in einer städtischen Umgebung. Vevey, 28.02.2021
17.1.1. Landnutzungsprofil des Projekts#
Das Landnutzungsprofil zeigt die prozentualen Anteile jeder Landnutzungskategorie innerhalb eines Radius von 1500 m um den Erhebungsort zugeordnet wird. Das Verhältnis der gefundenen Abfallobjekte unterscheidet sich je nach Landnutzungsprofil. Das Verhältnis gibt daher einen Hinweis auf die ökologischen und wirtschaftlichen Bedingungen um den Erhebungsort.
Verteilung der Anzahl der Datenerhebungen für die verschiedenen Landnutzungsmerkmale, n = 350 Stichproben
Show code cell source
# explanatory variables that are being considered
luse_exp = ['% to buildings', '% to recreation', '% to agg', '% to woods', 'streets km', 'intersects']
luse_ge = featuredata.luse_de
# columns needed
use_these_cols = ['loc_date' ,
'date',
'% to buildings',
'% to trans',
'% to recreation',
'% to agg',
'% to woods',
'population',
'water_name_slug',
'streets km',
'intersects',
'groupname',
'code'
]
# the land use data was unvailable for these municipalities
no_land_use = ['Walenstadt', 'Weesen', 'Glarus Nord', 'Quarten']
# slice the data by start and end date, remove the locations with no land use data
use_these_args = ((survey_data["date"] >= start_date)&(survey_data["date"] <= end_date)&(~survey_data.city.isin(no_land_use)))
survey_data = survey_data[use_these_args].copy()
# format the data and column names
survey_data['date'] = pd.to_datetime(survey_data.date)
# the survey total for each survey indifferent of object
dfdt = survey_data.groupby(use_these_cols[:-2], as_index=False).agg({unit_label:'sum', 'quantity':'sum'})
sns.set_style("whitegrid")
fig, axs = plt.subplots(2, 3, figsize=(9,9), sharey="row")
for i, n in enumerate(luse_exp):
r = i%2
c = i%3
ax=axs[r,c]
# the ECDF of the land use variable
the_data = ECDF(dfdt[n].values)
sns.lineplot(x=the_data.x, y= the_data.y, ax=ax, color='dodgerblue', label="% der Oberfläche")
# get the median % of land use for each variable under consideration from the data
the_median = dfdt[n].median()
# plot the median and drop horzontal and vertical lines
ax.scatter([the_median], 0.5, color='red',s=50, linewidth=2, zorder=100, label="Median")
ax.vlines(x=the_median, ymin=0, ymax=0.5, color='red', linewidth=2)
ax.hlines(xmax=the_median, xmin=0, y=0.5, color='red', linewidth=2)
#remove the legend from ax
ax.get_legend().remove()
if i <= 3:
if i == 0:
ax.set_ylabel("Prozent der Standorte", **ck.xlab_k)
ax.xaxis.set_major_formatter(ticker.PercentFormatter(1.0, 0, "%"))
else:
pass
handles, labels = ax.get_legend_handles_labels()
# add the median value from all locations to the ax title
ax.set_title(F"median: {(round(the_median, 2))}",fontsize=12, loc='left')
ax.set_xlabel(featuredata.luse_de[n], **ck.xlab_k)
plt.tight_layout()
# plt.subplots_adjust(top=.88, hspace=.3)
plt.subplots_adjust(top=.91, hspace=.5)
plt.suptitle("Landnutzung im Umkries von 1 500 m um den Erhebungsort", ha="center", y=1, fontsize=16)
fig.legend(handles, labels, bbox_to_anchor=(.5,.5), loc="upper center", ncol=6)
figure_name = f"landnutzung_im_Umkreis"
landnutzung_file_name = f'{save_fig_prefix}{figure_name}.jpeg'
save_figure_kwargs.update({"fname":landnutzung_file_name})
plt.savefig(**save_figure_kwargs)
glue("landnutzung_im_Umkreis", fig, display=False)
plt.close()
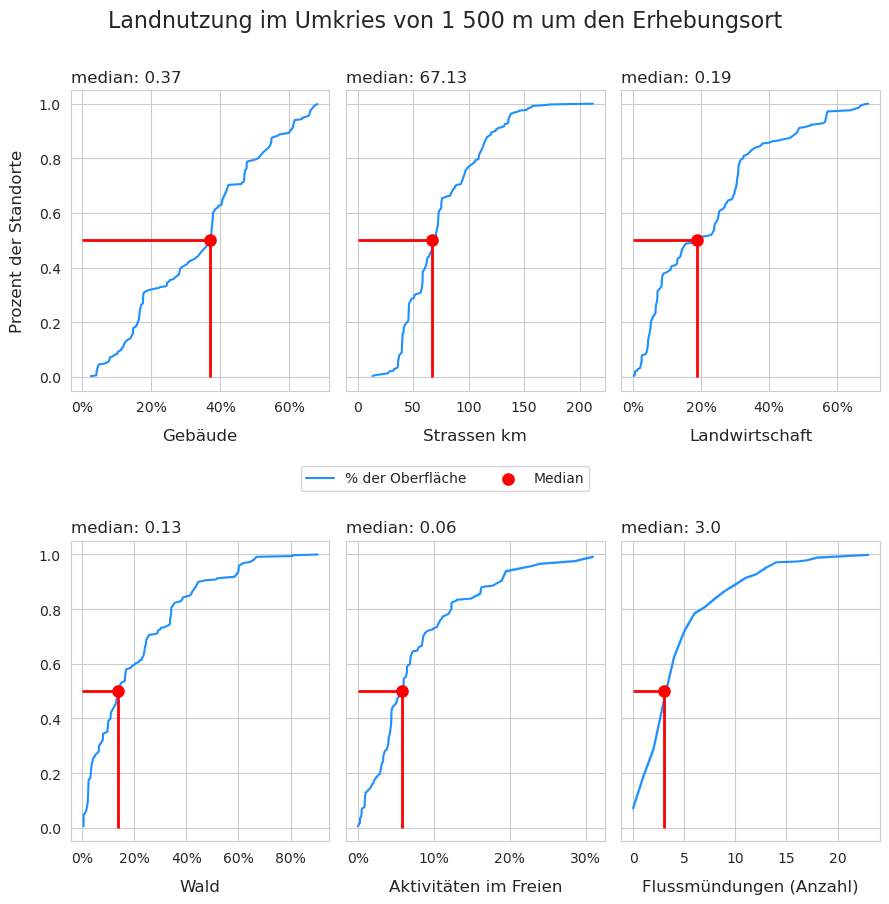
Abb. 17.4 #
Abildung 17.4: Verteilung der Anzahl der Datenerhebungen für die verschiedenen Landnutzungsmerkmale, n = 350 Stichproben
Die Landnutzung in der Umgebung der Datenerhebungen war stärker auf Gebäude als auf Landwirtschaft und Wald ausgerichtet. So entfielen bei der Hälfte aller Datenerhebungen mindestens 37 % der Landnutzung auf Gebäude gegenüber 19 % für die Landwirtschaft und 13 % für Wälder. Bei der Hälfte aller Stichproben betrug der Anteil der Landnutzung für Aktivitäten im Freien mindestens 6 %.
Die Länge des Strassennetzes innerhalb der Pufferzone unterscheidet sich zwischen Orten, die ansonsten ähnliche Landnutzungsmerkmale aufweisen. Die Länge des Strassennetzes pro Pufferzone reicht von 13 km bis 212 km. 50 % der Datenerhebungen hatten ein Strassennetz von weniger als 67 km.
Die Anzahl der Datenerhebungen reicht von 0 bis 23. Von den 354 Datenerhebungen hatten 50 % 3 oder weniger Flussmündungen innerhalb von 1500 m um den Erhebungsort. Die Grösse des mündenden Flusses oder Kanals wurde nicht berücksichtigt. Datenerhebungen an Fliessgewässern haben 0 Flussmündungen.
Die Bevölkerung (nicht gezeigt) stammt aus der Statistik der Bevölkerung und der Haushalte 2018 und stellt die Bevölkerung der Gemeinde dar, die den Erhebungsort umgibt. Die kleinste Einwohnerzahl betrug 442 und die grösste 415 367. Von den gesamten Datenerhebungen stammen 50 % aus Gemeinden mit einer Einwohnerzahl von mindestens 12 812.
17.1.2. Auswahl der Datenerhebungsorte#
Die Erhebungsorte wurden anhand der folgenden Kriterien ausgewählt:
Daten aus früheren Datenerhebungen (SLR, MCBP)
Ganzjährig sicherer Zugang
Innerhalb von 30 Minuten zu Fuss von den nächsten öffentlichen Verkehrsmitteln entfernt
Die Erhebungsorte repräsentieren die mit öffentlichen Verkehrsmitteln erreichbaren Landnutzungsbedingungen von etwa 1,7 Millionen Menschen..
17.2. Zuordnung von Landnutzung zu Erhebungsergebnissen#
Es gibt 350 Datenerhebungen an 129 Erhebungsorten entlang von Fliessgewässern und Seen. Der Mittelwert war mehr als doppelt so hoch wie der Median, was die extremen Werte widerspiegelt, die für Ufer-Abfallobjekte-Untersuchungen typisch sind. []
Show code cell source
# set the date intervals for the chart
months = mdates.MonthLocator(interval=1)
months_fmt = mdates.DateFormatter('%b')
days = mdates.DayLocator(interval=7)
# set the grid for the chart
sns.set_style("whitegrid")
# chart the daily totals and the ECDF of all surveys under consideration
fig, ax = plt.subplots(1,2, figsize=(10,6), sharey=False)
axone=ax[0]
axtwo = ax[1]
axone.set_ylabel("p/m", **ck.xlab_k14)
axone.xaxis.set_minor_locator(days)
axone.xaxis.set_major_formatter(months_fmt)
axone.set_xlabel(" ")
axtwo.set_ylabel("Prozent der Standorte", **ck.xlab_k14)
axtwo.set_xlabel("p/m", **ck.xlab_k)
# time series plot of the survey results
sns.scatterplot(data=dfdt, x='date', y=unit_label, color="dodgerblue", s=34, ec='white', ax=axone)
# ecdf of the survey results
this_ecdf = ECDF(dfdt.pcs_m.values)
# plot the cumulative disrtibution
sns.lineplot(x=this_ecdf.x,y=this_ecdf.y, ax=axtwo, label='Kumulativverteilung')
# get the median and mean from the data
the_median = dfdt.pcs_m.median()
the_mean = dfdt.pcs_m.mean()
# get the percentile ranking of the mean
p_mean = this_ecdf(the_mean)
# plot the median and drop horzontal and vertical lines
axtwo.scatter([the_median], 0.5, color='red',s=50, linewidth=2, zorder=100, label="Median")
axtwo.vlines(x=the_median, ymin=0, ymax=0.5, color='red', linewidth=1)
axtwo.hlines(xmax=the_median, xmin=0, y=0.5, color='red', linewidth=1)
# plot the mean and drop horzontal and vertical lines
axtwo.scatter([the_mean], p_mean, color='magenta',s=50, linewidth=2, zorder=100, label="Mittelwert")
axtwo.vlines(x=the_mean, ymin=0, ymax=p_mean, color='magenta', linewidth=1)
axtwo.hlines(xmax=the_mean, xmin=0, y=p_mean, color='magenta', linewidth=1)
handle, labels = axtwo.get_legend_handles_labels()
plt.legend(handle,labels)
plt.tight_layout()
figure_name = f"results_distribution"
results_distribution_file_name = f'{save_fig_prefix}{figure_name}.jpeg'
save_figure_kwargs.update({"fname":results_distribution_file_name})
plt.savefig(**save_figure_kwargs)
results_distribution_cpt = [
"<b>Links:</b> Erhebungsergebnisse. <b>Rechts:</b> kumulative Verteilung aller Seen und Fliessgewässer ohne Walensee ",
"(das Walenseegebiet wurde mangels ausreichender Landnutzungsdaten ausgeschlossen). Anzahl der Proben: 350. ",
"Anzahl der Erhebungsorte: 129. Median: 2,14 p/m. Mittelwert: 4,15 p/m.",
]
results_distribution_caption = ''.join(results_distribution_cpt)
glue("results_distributionresults_distribution_caption", results_distribution_caption, display=False)
glue("results_distribution_example", fig, display=False)
plt.close()
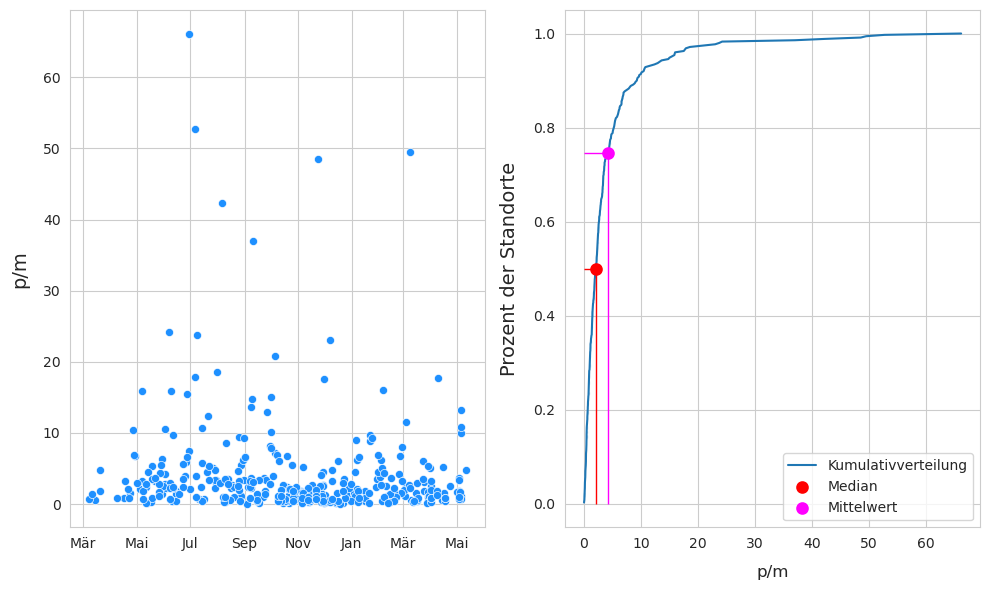
Abb. 17.5 #
Abildung 17.5: Links: Erhebungsergebnisse. Rechts: kumulative Verteilung aller Seen und Fliessgewässer ohne Walensee (das Walenseegebiet wurde mangels ausreichender Landnutzungsdaten ausgeschlossen). Anzahl der Proben: 350. Anzahl der Erhebungsorte: 129. Median: 2,14 p/m. Mittelwert: 4,15 p/m.
17.2.1. Spearmans \(\rho\) – ein Beispiel#
Die Rangkorrelation nach Spearman testet auf eine statistisch signifikante monotone Beziehung oder Assoziation zwischen zwei Variablen. Die Hypothese lautet, dass es keinen Zusammenhang zwischen dem Landnutzungsprofil und den Erhebungsergebnissen gibt. []
Die Testergebnisse beziehen sich auf die Richtung (rho) einer Assoziation und darauf, ob diese Assoziation wahrscheinlich auf einen Zufall zurückzuführen ist (p-Wert) oder nicht.) Damit ein Test als signifikant gilt, muss der p-Wert kleiner als 0,05 sein. []
Nullhypothese: Es gibt keine monotone Beziehung zwischen den beiden Variablen.
Alternativhypothese: Es besteht eine monotone Beziehung und das Vorzeichen (+/-) gibt die Richtung an.
Sie gibt keine Auskunft über das Ausmass der Beziehung. Als Beispiel sei die Beziehung zwischen den Erhebungsergebnissen von Zigarettenstummeln und der bebauten oder landwirtschaftlich genutzten Fläche angeführt. []
Show code cell source
# data for the example
data = survey_data[survey_data.code == "G27"].groupby(["loc_date","% to buildings", "% to agg"], as_index=False)[unit_label].sum()
# run the test under the two conditions
sprmns_b = stats.spearmanr(data["% to buildings"], data[unit_label])
sprmns_a = stats.spearmanr(data["% to agg"], data[unit_label])
# plot the survey results with respect to the land use profile
fig, axs = plt.subplots(1,2, figsize=(8,5.5), sharey=True)
sns.scatterplot(data=data, x="% to buildings", y=unit_label, ax=axs[0], color="magenta")
sns.scatterplot(data=data, x="% to agg", y=unit_label, ax=axs[1], color="dodgerblue")
axs[0].set_xlabel("% Gebäude", **ck.xlab_k14)
axs[1].set_xlabel("% Landwirtschaft", **ck.xlab_k14)
axs[0].set_ylabel("p/m", **ck.xlab_k14)
plt.tight_layout()
figure_name = f"spearmans_example"
spearmans_example_file_name = f'{save_fig_prefix}{figure_name}.jpeg'
save_figure_kwargs.update({"fname":spearmans_example_file_name})
plt.savefig(**save_figure_kwargs)
spearmans_example_cpt = [
"<b>Links:</b> Erhebungsergebnisse. <b>Rechts:</b> kumulative Verteilung aller Seen und Fliessgewässer ohne Walensee ",
"(das Walenseegebiet wurde mangels ausreichender Landnutzungsdaten ausgeschlossen). Anzahl der Proben: 350. ",
"Anzahl der Erhebungsorte: 129. Median: 2,14 p/m. Mittelwert: 4,15 p/m.",
]
spearmans_example_caption = ''.join(spearmans_example_cpt)
glue("spearmans_example_caption", spearmans_example_caption, display=False)
glue("spearmans_example", fig, display=False)
plt.close()
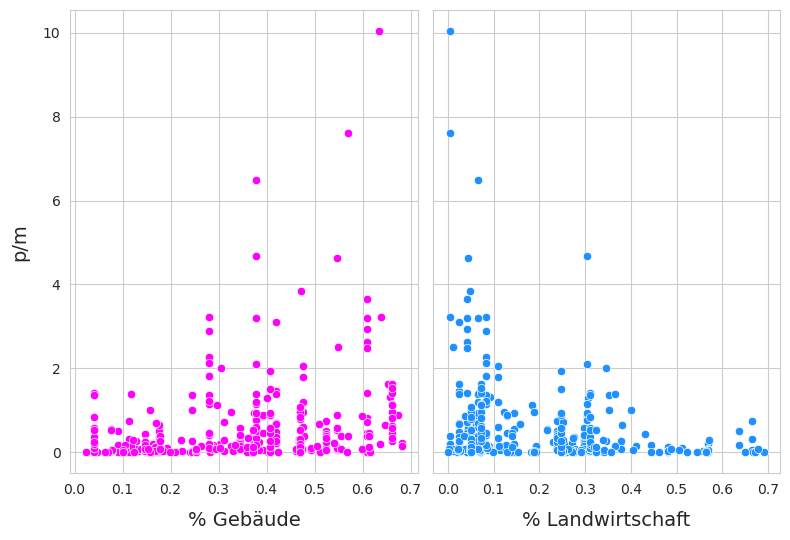
Abb. 17.6 #
Abildung 17.6: Links: Datenerhebungen der Zigarettenstummel in Bezug auf den prozentualen Anteil der Grundstücke an den Gebäuden. rho = 0,39, p-value < 0,001. Rechts: Datenerhebungen der Zigarettenstummel in Bezug auf den Prozentsatz der landwirtschaftlichen Nutzfläche. rho = -0,31, p-value < 0,001.
Betrachtet man die Erhebungsergebnisse für Zigarettenstummel in Bezug auf den prozentualen Anteil von bebauten oder landwirtschaftlich genutzten Flächen, ist der Wert von rho entgegengesetzt.
17.2.2. Zuordnung der Erhebungssummen zur Landnutzung#
Ergebnisse des Spearman-Rangkorrelationstests: Summen der Datenerhebungen in Bezug auf das Landnutzungsprofil
Rot/Rosa steht für eine positive Assoziation
Gelb steht für eine negative Assoziation
Weiss bedeutet, dass keine statistische Grundlage für die Annahme eines Zusammenhangs vorliegt, p > 0,05
Show code cell source
# correlation of survey total to land use attributes:
fig, axs = plt.subplots(2, 3, figsize=(8,7), sharey="row")
for i, n in enumerate(luse_exp):
r = i%2
c = i%3
ax=axs[r,c]
ax, corr, a_p = sut.make_plot_with_spearmans(dfdt, ax, n, unit_label=unit_label)
if c == 0:
ax.set_ylabel('pcs/m', **ck.xlab_k)
ax.set_xlabel(featuredata.luse_de[n], **ck.xlab_k)
if a_p <= .001:
title_str = "p < .001"
else:
title_str = F"p={round(a_p, 3)}"
ax.set_title(rF"$\rho={round(corr,4)}$, {title_str}")
# find p
if a_p < 0.05:
if corr > 0:
ax.patch.set_facecolor('salmon')
ax.patch.set_alpha(0.5)
else:
ax.patch.set_facecolor('palegoldenrod')
ax.patch.set_alpha(0.5)
plt.tight_layout()
figure_name = f"sprmns_ex_survey_total"
sprmns_ex_survey_total_file_name = f'{save_fig_prefix}{figure_name}.jpeg'
save_figure_kwargs.update({"fname":sprmns_ex_survey_total_file_name})
plt.savefig(**save_figure_kwargs)
spearmans_example_cpt = [
"Im Allgemeinen kann ein positiver Zusammenhang zwischen den Erhebungsergebnissen und dem prozentualen Anteil ",
"der Flächen für Gebäude oder Aktivitäten im Freien und ein negativer Zusammenhang mit ",
"Wäldern und Landwirtschaf angenommen werden."
]
sprmns_ex_survey_total_caption = ''.join(spearmans_example_cpt)
glue("sprmns_ex_survey_total_caption", sprmns_ex_survey_total_caption, display=False)
glue("sprmns_ex_survey_total", fig, display=False)
plt.close()
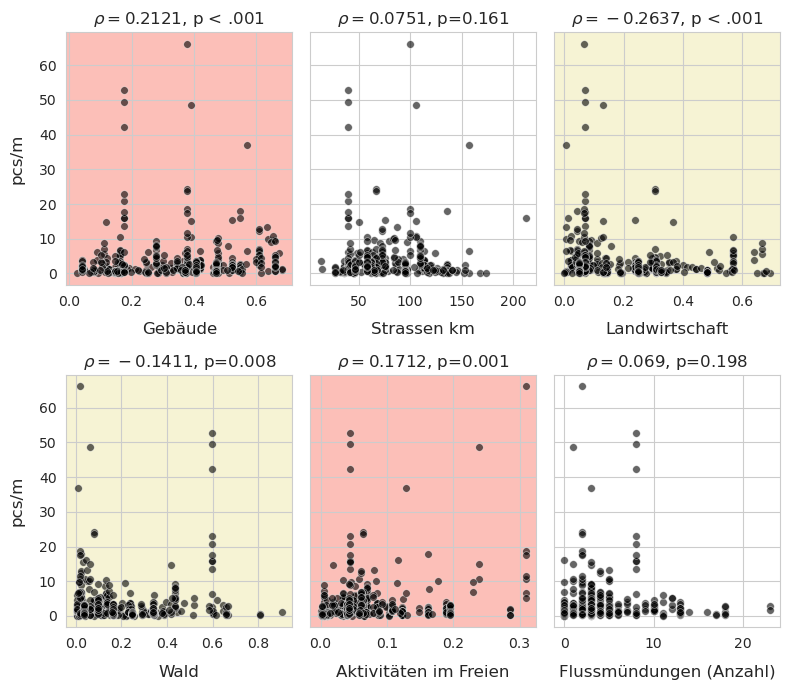
Abb. 17.7 #
Abildung 17.7: Im Allgemeinen kann ein positiver Zusammenhang zwischen den Erhebungsergebnissen und dem prozentualen Anteil der Flächen für Gebäude oder Aktivitäten im Freien und ein negativer Zusammenhang mit Wäldern und Landwirtschaf angenommen werden.
17.2.3. Zuordnung der häufigsten Objekte zur Landnutzung#
Die häufigsten Objekte sind alle Objekte, die entweder die zehn häufigsten nach Anzahl sind oder alle Objekte, die in mindestens 50 % aller Datenerhebungen identifiziert wurden, was ungefähr 68 % aller identifizierten und gezählten Objekte entspricht. Einige Objekte wurden in 50 % der Fälle identifiziert, kamen aber nicht so häufig vor, dass sie in die «Top-Ten-Liste» aufgenommen werden konnten.
Show code cell source
# common aggregations of survey data
agg_pcs_quantity = {unit_label:"sum", "quantity":"sum"}
agg_pcs_median = {unit_label:"median", "quantity":"sum"}
# cumulative statistics for each code
c_t_params = dict(agg=agg_pcs_median, description_map=code_description_map, material_map=code_material_map)
code_totals = sut.the_aggregated_object_values(survey_data, **c_t_params)
code_totals['item'] = code_totals.index.map(lambda x: codes_class.dMap.loc[x])
# all codes with a fail rate > fail rate = most common objects
better_than_50 = code_totals[code_totals["fail rate"] >= 50]
# the ten objects with the greatest quantity
t_ten = code_totals.sort_values(by="quantity", ascending=False)[:10]
# combine the most abundant with the most common
abundant_codes = list(set(t_ten.index) | set(better_than_50.index))
# get the survey data for the most common codes for the final table data
cols_to_use = ['item','quantity', 'fail rate', '% of total']
m_common = code_totals.loc[abundant_codes, cols_to_use].sort_values(by="quantity", ascending=False)
m_common["% of total"] = ((m_common.quantity/survey_data.quantity.sum())*100).astype('int')
# format values for table
new_columns = featuredata.most_common_objects_table_de
mcc = m_common[list(new_columns.keys())]
colLabels = list(new_columns.values())
mcc.rename(columns=new_columns, inplace=True)
language = "de"
# .pdf output
data = mcc.copy()
data["Anteil"] = data["Anteil"].map(lambda x: f"{int(x)}%")
data['Objekte (St.)'] = data['Objekte (St.)'].map(lambda x:featuredata.thousandsSeparator(x, language))
data['Häufigkeitsrate'] = data['Häufigkeitsrate'].map(lambda x: f"{x}%")
data.set_index("Objekte", drop=True, inplace=True)
mc_caption_string = [
"Die am häufigsten gefundenen Objekte sind die zehn mengenmässig am meisten vorkommenden Objekte ",
"und/oder Objekte, die in mindestens 50\% aller Datenerhebungen identifiziert wurden (Häufigkeitsrate)."
]
mc_caption_string = "".join(mc_caption_string)
pdf_mc_table = featuredata.aStyledTable(data, caption=mc_caption_string, colWidths=[7*cm, 2.2*cm, 2*cm, 2.8*cm])
# this defines the css rules for the note-book table displays
header_row = {'selector': 'th:nth-child(1)', 'props': f'background-color: #FFF;text-align:right;'}
even_rows = {"selector": 'tr:nth-child(even)', 'props': f'background-color: rgba(139, 69, 19, 0.08);'}
odd_rows = {'selector': 'tr:nth-child(odd)', 'props': 'background: #FFF;'}
table_font = {'selector': 'tr', 'props': 'font-size: 12px;'}
table_data = {'selector': 'td', 'props': 'padding:6px;'}
table_css_styles = [even_rows, odd_rows, table_font, header_row, table_data]
# set pandas display
aformatter = {
"Anteil":lambda x: f"{int(x)}%",
"Häufigkeitsrate": lambda x: f"{int(x)}%",
"Objekte (St.)": lambda x: featuredata.thousandsSeparator(int(x), "de")
}
mcc.set_index("Objekte", inplace=True, drop=True)
mcc.index.name = None
mcc.columns.name = None
mcd = mcc.style.format(aformatter).set_table_styles(table_css_styles)
glue('mcommon_caption', mc_caption_string, display=False)
glue('mcommon_tables', mcd, display=False)
| Objekte (St.) | Anteil | Häufigkeitsrate | |
|---|---|---|---|
| Zigarettenfilter | 7 824 | 15% | 87% |
| Fragmentierte Kunststoffe | 6 943 | 13% | 86% |
| Expandiertes Polystyrol | 4 833 | 9% | 66% |
| Snack-Verpackungen | 3 160 | 6% | 85% |
| Industriefolie (Kunststoff) | 2 221 | 4% | 68% |
| Getränkeflaschen aus Glas, Glasfragmente | 2 057 | 4% | 66% |
| Industriepellets (Nurdles) | 1 948 | 3% | 32% |
| Schaumstoffverpackungen/Isolierung | 1 546 | 3% | 53% |
| Wattestäbchen/Tupfer | 1 369 | 2% | 51% |
| Styropor < 5mm | 1 098 | 2% | 24% |
| Kunststoff-Bauabfälle | 916 | 1% | 51% |
| Kronkorken, Lasche von Dose/Ausfreisslachen | 668 | 1% | 52% |
Abb. 17.8 #
Abildung 17.8: Die am häufigsten gefundenen Objekte sind die zehn mengenmässig am meisten vorkommenden Objekte, und/oder Objekte, die in mindestens 50 % aller Datenerhebungen identifiziert wurden (Häufigkeitsrate).
17.2.3.1. Ergebnisse Spearmans \(\rho\)#
Aus der ersten Abbildung lässt sich ein positiver Zusammenhang zwischen der Anzahl der identifizierten Objekte und dem prozentualen Anteil der Flächen, die Gebäuden und Orten für Aktivitäten im Freien zugeordnet sind, ableiten. Das Umgekehrte gilt für den prozentualen Anteil von Landwirtschaft und Wald. Es gibt keine statistische Grundlage für die Annahme eines Zusammenhangs zwischen der Länge von Strassen oder der Anzahl von Flussmündungen und dem Gesamtergebnis der Erhebung.
Das Ergebnis von Spearmans rho für die am häufigsten vorkommenden Objekte steht im Zusammenhang mit den Ergebnissen in der vorangegangenen Abbildung und veranschaulicht, wie sich verschiedene Objekte unter verschiedenen Bedingungen anhäufen.
Rot/Rosa steht für eine positive Assoziation
Gelb steht eine negative Assoziation
Weiss bedeutet, dass keine statistische Grundlage für die Annahme eines Zusammenhangs vorliegt, p > 0,05
Show code cell source
fig, axs = plt.subplots(len(abundant_codes),len(luse_exp), figsize=(len(luse_exp)+6,len(abundant_codes)), sharey='row')
for i,code in enumerate(m_common.index):
data = survey_data[survey_data.code == code]
for j, n in enumerate(luse_exp):
this_data = data.groupby(['loc_date', n], as_index=False)[unit_label].sum()
ax=axs[i, j]
ax.grid(False)
ax.tick_params(axis='both', which='both',bottom=False,top=False,labelbottom=False, labelleft=False, left=False)
if i == 0:
ax.set_title(F"{luse_ge[n]}", fontsize=10)
else:
pass
if j == 0:
ax.set_ylabel(F"{codes_class.dMap.loc[code]}", rotation=0, ha='right', **ck.xlab_k14)
ax.yaxis.label.set(fontsize=10)
ax.set_xlabel(" ")
else:
ax.set_xlabel(" ")
ax.set_ylabel(" ")
_, corr, a_p = sut.make_plot_with_spearmans(this_data, ax, n, unit_label=unit_label)
if a_p < 0.05:
if corr > 0:
ax.patch.set_facecolor('salmon')
ax.patch.set_alpha(0.5)
else:
ax.patch.set_facecolor('palegoldenrod')
ax.patch.set_alpha(0.5)
plt.tick_params(labelsize=10, which='both', axis='both')
plt.tight_layout()
plt.subplots_adjust(wspace=0.02, hspace=0.02)
figure_name = f"sprmns_mcommon"
sprmns_mcommon_file_name = f'{save_fig_prefix}{figure_name}.jpeg'
save_figure_kwargs.update({"fname":sprmns_mcommon_file_name})
plt.savefig(**save_figure_kwargs)
sprmns_mcommon_cpt = [
" "
]
sprmns_mcommon_caption = ''.join(sprmns_mcommon_cpt)
glue("sprmns_mcommon_captionl_caption", sprmns_mcommon_caption, display=False)
glue("sprmns_mcommon", fig, display=False)
plt.close()
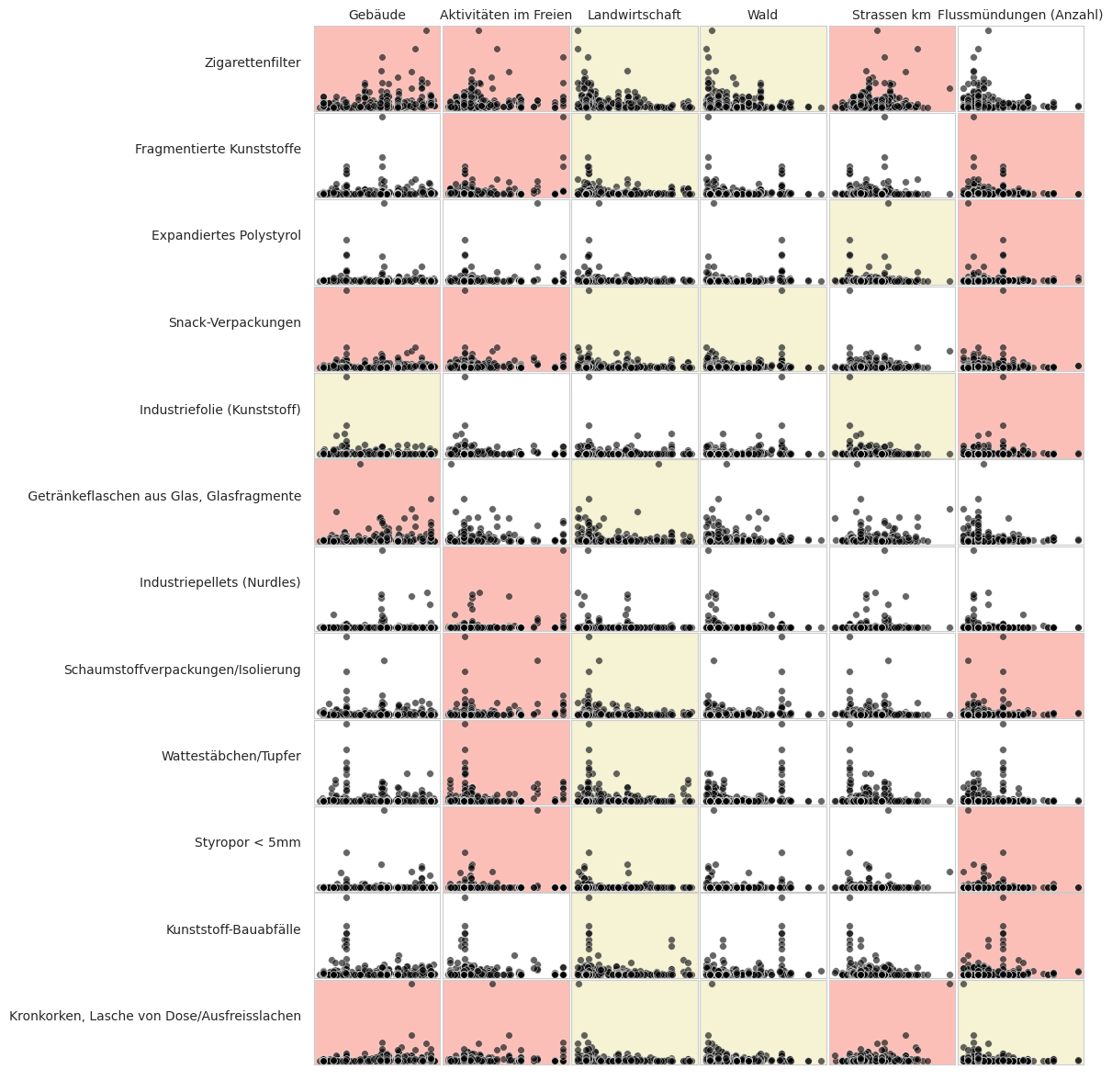
Abb. 17.9 #
Abildung 17.9: Im Allgemeinen kann ein positiver Zusammenhang zwischen den Erhebungsergebnissen und dem prozentualen Anteil der Flächen für Gebäude oder Aktivitäten im Freien und ein negativer Zusammenhang mit Wäldern und Landwirtschaf angenommen werden.
17.2.4. Spearmans \(\rho\) interpretieren#
Eine positive Assoziation bedeutet, dass die Erhebungsergebnisse tendenziell zunehmen, wenn der prozentuale Wert des Landnutzungsmerkmals steigt. Dies kann auf eine Kovarianz der Merkmale zurückzuführen sein. In jedem Fall ist eine positive Assoziation ein Signal dafür, dass sich die Objekte unter diesen Bedingungen eher häufen.
Eine negative Assoziation bedeutet, dass das Landnutzungsmerkmal die Akkumulation des Objekts nicht erleichtert. Dieses Ergebnis ist für landwirtschaftliche Flächen und Wälder auf nationaler Ebene üblich. Eine negative Assoziation ist ein Signal dafür, dass die Objekte unter diesen Bedingungen nicht zur Akkumulation neigen.
Keine oder wenige Assoziationen bedeutet, dass die Landnutzungsmerkmale keinen Einfluss auf die Akkumulation des Objekts hatten. Die Erhebungsergebnisse der häufigsten Objekte ohne oder mit wenigen Assoziationen lassen sich in zwei Kategorien einteilen:
Allgegenwärtig: hohe Häufigkeitsrate, hohe Stückzahl pro Meter. Unabhängig von der Landnutzung im gesamten Untersuchungsgebiet in gleichbleibenden Raten gefunden.
Vorübergehend: niedrige Häufigkeitsrate, hohe Menge, hohe Stückzahl pro Meter, wenige Verbände. Gelegentlich in grossen Mengen an bestimmten Orten gefunden
17.3. Diskussion#
Insgesamt war es wahrscheinlich, dass Datenerhebungen an Orten mit mehr Gebäuden und Möglichkeiten für Aktivitäten im Freien die Anhäufung von Objekten an Gewässern begünstigten. Betrachtet man die häufigsten Objekte, so wurden nur vier der zwölf Objekte in Anwesenheit von mehr Gebäuden häufiger identifiziert. Dabei handelt es sich in der Regel um Objekte, die mit dem Verzehr von Lebensmitteln und/oder Tabakwaren in der Nähe des Ortes zusammenhängen. Das deutet darauf hin, dass in stark frequentierten Gebieten in Wassernähe noch einiges an Vorbeugung und Verminderung möglich ist.
Sechs der zwölf Objekte haben jedoch keine positive Assoziation zur Fläche, die von Gebäuden eingenommen wird, wurden aber in mindestens 50 % aller Datenerhebungen gefunden. Diese Objekte werden im Allgemeinen mit der beruflichen Nutzung oder im Fall der Wattestäbchen mit der persönlichen Hygiene
Kunststoff-Bauabfälle
fragmentierte Kunststoffe
Industriefolien
expandiertes Polystyrol
Wattestäbchen/Stäbchen
Isolierung, einschliesslich Sprühschäume
Ausserdem haben diese Objekte im Vergleich zu Produkten, die mit Tabakwaren oder Nahrungsmitteln in Verbindung stehen, im Allgemeinen weniger positive Assoziationen. Dies deutet darauf hin, dass das entsprechende Landnutzungsmerkmal derzeit nicht berücksichtigt wird und/oder diese Objekte unabhängig von den Landnutzungsmerkmalen in ähnlichen Mengen identifiziert werden. Es kann davon ausgegangen werden, dass diese Objekte in der Umwelt allgegenwärtig sind.
Schliesslich wurden zwei der zwölf häufigsten Objekte in weniger als 50 % der Datenerhebungen gefunden und weisen nur wenige positive Assoziationen auf:
Industriepellets
expandierte Schaumstoffe < 5 mm
Diese Objekte werden in grossen Mengen sporadisch an bestimmten Orten gefunden. Sie wurden in allen Untersuchungsgebieten und in allen Seen identifiziert. Industriepellets haben einen sehr spezifischen Verwendungszweck und Kundenstamm, so dass es möglich ist, auf der Grundlage der Dichte und des Erhebungsorts der identifizierten Pellets und des Standorts des nächstgelegenen Verbrauchers oder Herstellers von Pellets, siehe Geteilte Verantwortung¶, die Quelle zu bestimmen und die Auswirkungen zu verringern.
17.3.1. Anwendung#
Die Anzahl der Stichproben, die verwendet werden, um eine Assoziation mit Spearman zu bestimmen, muss vorsichtig gewählt sein.
Ebenso das Gewicht, das den Ergebnissen beigemessen wird. Die Ergebnisse für Zigarettenfilter sind ein gutes Beispiel. Die Diagramme zeigen eindeutig sowohl negative als auch positive Assoziationen in Abhängigkeit von der Landnutzung, aber rho ist kleiner als 0,5. Es handelt sich also keineswegs um eine lineare Beziehung und das Ausmass bleibt unbestimmt.
Die Betroffenen sollten diese Ergebnisse und deren Anwendbarkeit auf ihre spezifische Situation prüfen. Eine Schlussfolgerung, die gezogen werden kann, ist, dass es eine Methode gibt, um auf der Grundlage der empirischen Daten aus den Datenerhebungen mit angemessener Sicherheit Zonen der Akkumulation zu identifizieren. Diese Ergebnisse ermöglichen es den Akteuren, ihre Prioritäten auf die Herausforderungen zu setzen, die für ihre Region oder Situation spezifisch sind.
Der Korrelationskoeffizient nach Spearman lässt sich leicht anwenden, sobald der endgültige Datensatz bestimmt wurde. Der Wert des Koeffizienten ändert sich jedoch je nach Erhebungsgebiet oder See, an dem der Test angewendet wird. Das bedeutet, dass das Verständnis und die Interpretation dieser Ergebnisse nicht nur ein nationales, sondern auch ein regionales und kommunales Anliegen ist.
Warum 1500 Meter? Für diese Studie haben wir uns mit Objekten befasst, die hohe Werte für rho bei kleineren Radien aufwiesen, die dem Massstab der bereitgestellten Daten angemessen waren. Es wurden auch andere Entfernungen in Betracht gezogen (2 km, 2,5 km, 5 km und 10 km). Generell gilt, dass mit zunehmendem Radius die den Gebäuden zugewiesene Fläche abnimmt und damit auch der Wert von rho. Dieses Thema wurde in einem Artikel, der derzeit für das Peer-Review-Verfahren vorbereitet wird, ausführlicher behandelt.
Die Überprüfung einer Assoziation erfolgt durch die Berücksichtigung aller anderen Schlüsselindikatoren und das Urteil von Experten. Das kommunale Reinigungs- und Unterhaltspersonal ist mit den Bedingungen vor Ort vertraut und ist eine der besten Informationsquellen. Die Wiederholung von Stichproben an einem bestimmten Ort für einen bestimmten Zeitraum und der Vergleich der Ergebnisse mit den Ausgangswerten für das Erhebungsgebiet ist ebenfalls eine zuverlässige Methode, um die Leistung in Bezug auf das Erhebungsgebiet zu bestimmen.
Der Rangkorrelationskoeffizient ist eine effiziente und zuverlässige Methode, mit der sich Landnutzungsklassifizierungen identifizieren lassen, die mit erhöhten oder verringerten Mengen an bestimmten Abfallobjekten verbunden sind. Das Ausmass der Beziehung in Bezug auf die Anzahl der Objekte auf dem Boden bleibt jedoch undefiniert.
Um mehr darüber zu erfahren, wie sich die Erhebungsergebnisse je nach Landnutzung ändern und/oder gleichbleiben, siehe Geteilte Verantwortung.
Um zu verstehen, wie die Abfallobjekte für diesen Bericht berechnet wurden, siehe Basiswerte für Abfallobjekte an Gewässern.